






一、如何本地部署大模型
-
硬件环境准备(内存>16GB、显卡显存8GB以上)
-
软件环境准备,安装python虚拟环境神器:Anaconda
-
去魔搭社区(https://modelscope.cn/home)找相应的开源模型 ChatGLM-6B
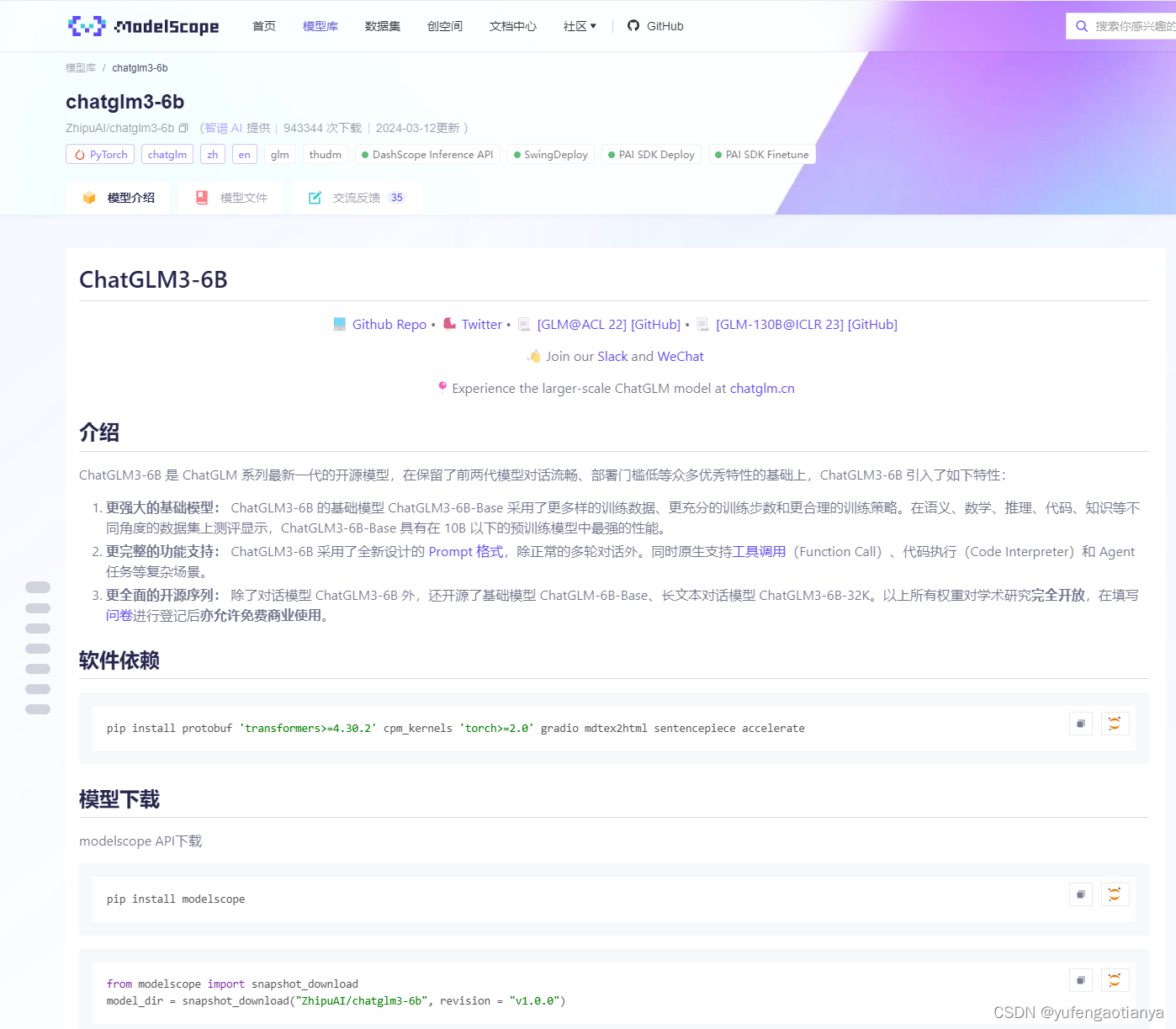
-
安装模型运行必须的环境和魔搭社区插件(以下插件依次安装)
环境安装国内镜像(中国科技大学) -i https://mirrors.ustc.edu.cn/pypi/web/simple
pip install protobuf ‘transformers>=4.30.2’ cpm_kernels ‘torch>=2.0’ gradio mdtex2html sentencepiece accelerate
安装torch注意事项torch 安装要找相应的显卡cuda版本 命令行运行命令 nvidia-smi 查看显卡cuda支持的最高版本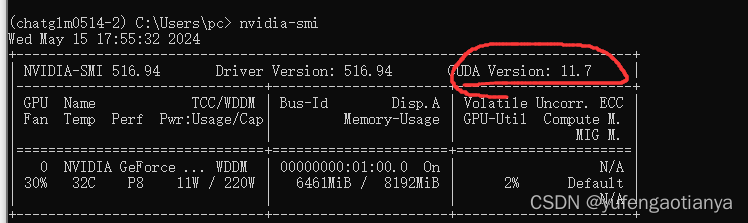
我cuda版本是11.7;所以进入pytorch官网选择相应版本:https://pytorch.org/get-started/locally/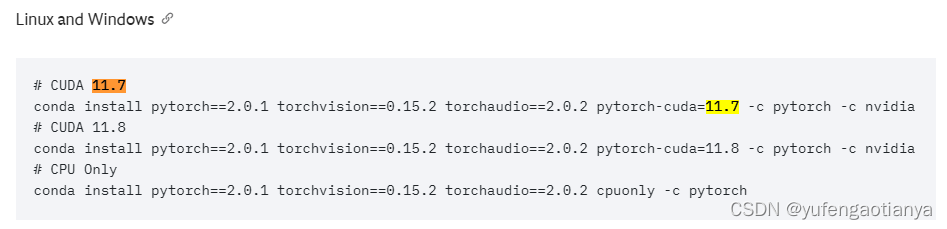
CUDA 11.7 使用以下命令安装环境
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia 上述环江安装好之后,重启电脑;命令行输入:nvcc -V 查看安装情况 -
加载模型,开始私有模型之旅
# 查看torch安装情况
import torch
print("是否可用:", torch.cuda.is_available()) # 查看GPU是否可用
print("GPU数量:", torch.cuda.device_count()) # 查看GPU数量
print("torch方法查看CUDA版本:", torch.version.cuda) # torch方法查看CUDA版本
print("GPU索引号:", torch.cuda.current_device()) # 查看GPU索引号
# print("GPU名称:", torch.cuda.get_device_name(1)) # 根据索引号得到GPU名称
#下载模型 也可以在魔搭社区自行下载
from modelscope import snapshot_download
# 下载模型
model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")
加载模型
from modelscope import AutoTokenizer, AutoModel
# 下载模型
# model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")
model_dir= r"D:\ai\chatglm3-6b"
# 加载预处理分词器 把文字转换为模型理解的数据
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# 加载一个预处理模型
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().quantize(4).cuda()
# 设置模型为推理模式
model = model.eval()















 3810
3810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









