







目录
本实验将使用Dify和Amazon Bedrock快速构建GenAI应用,旨在为解决方案架构师、开发人员和 IT 专业人士提供动手实践
预期收获
- 了解DIfy的核心功能,包括RAG、Tools、Workflow等
- 可以使用Dify 快速构建GenAI应用
预计时长
2小时
需要技术水平
Level200及以上
预估费用
预估整体费用< 1$
实验准备
AWS账号
在本实验中,您将登录到您自己的 AWS 账户进行操作。
Important
在您自己的帐号中运行该工作坊会导致额外成本。请确保在结束后清理已配置的资源。要清理资源,请按照清理实验环境的步骤操作。
安装Dify
- 下载一键部署Dify社区版的cloudformation模板:
curl -O https://raw.githubusercontent.com/luanluandehaobaoman/dify-on-aws/main/dify.yaml-
登录AWS Cloudformation控制台导入模板并部署(支持AWS global所有region)
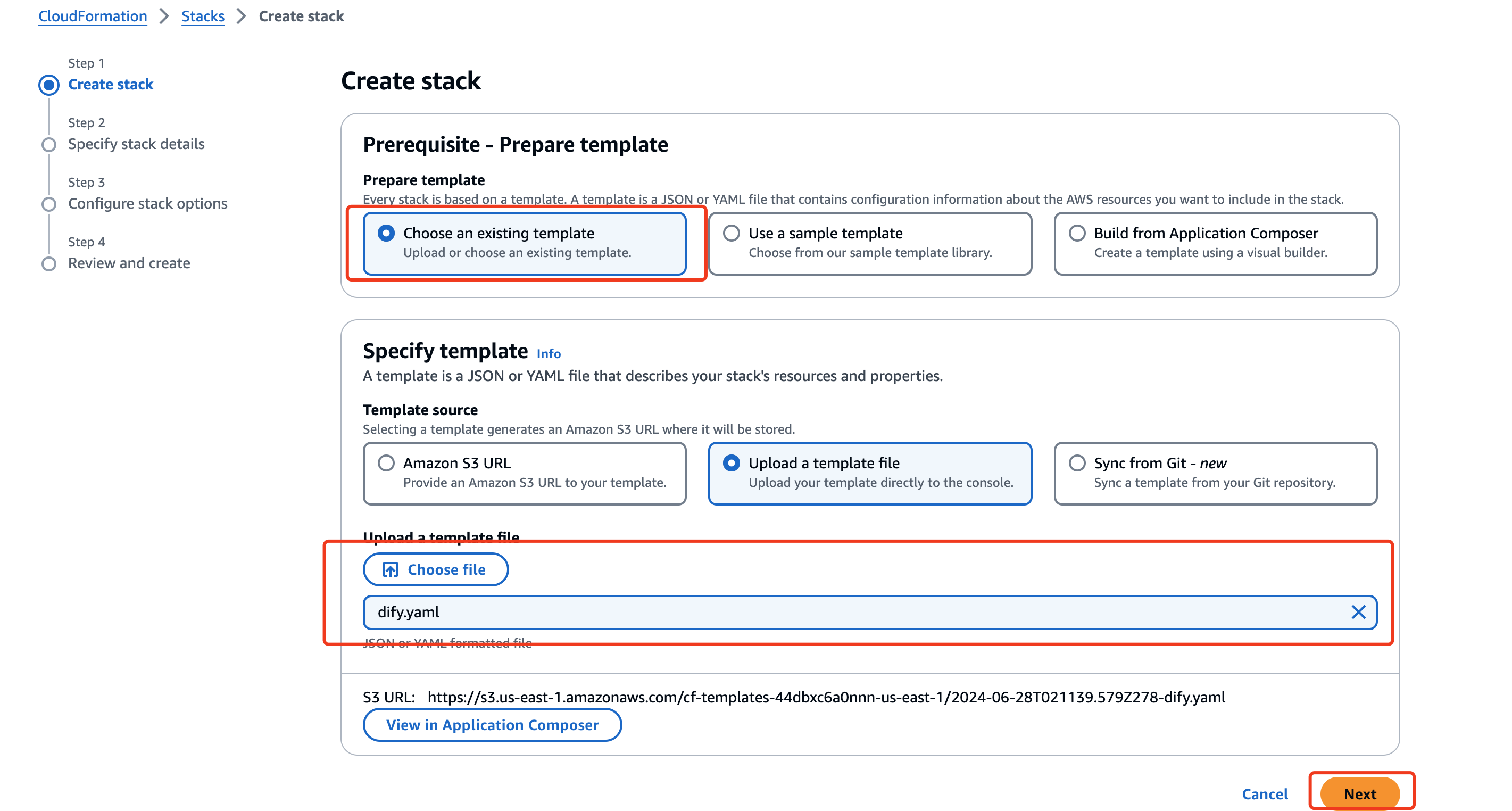
创建自定义堆栈名称,其他保持默认配置
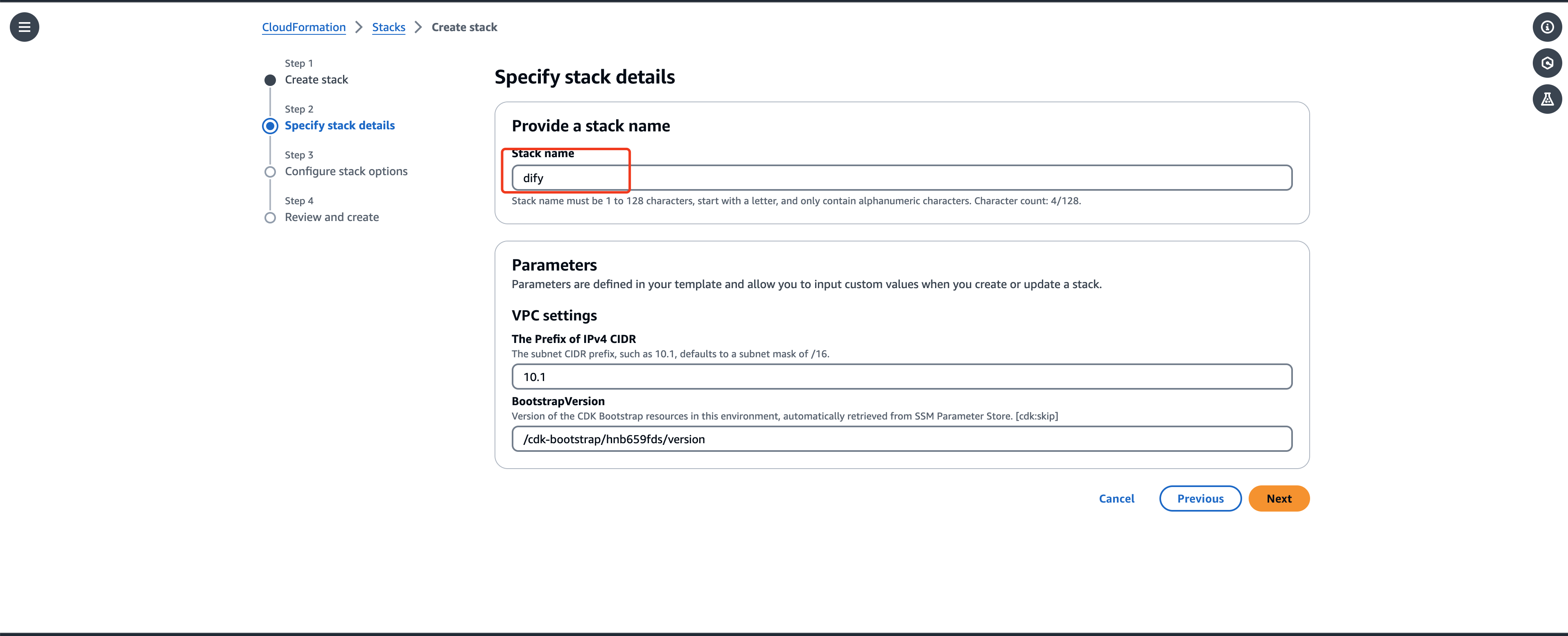
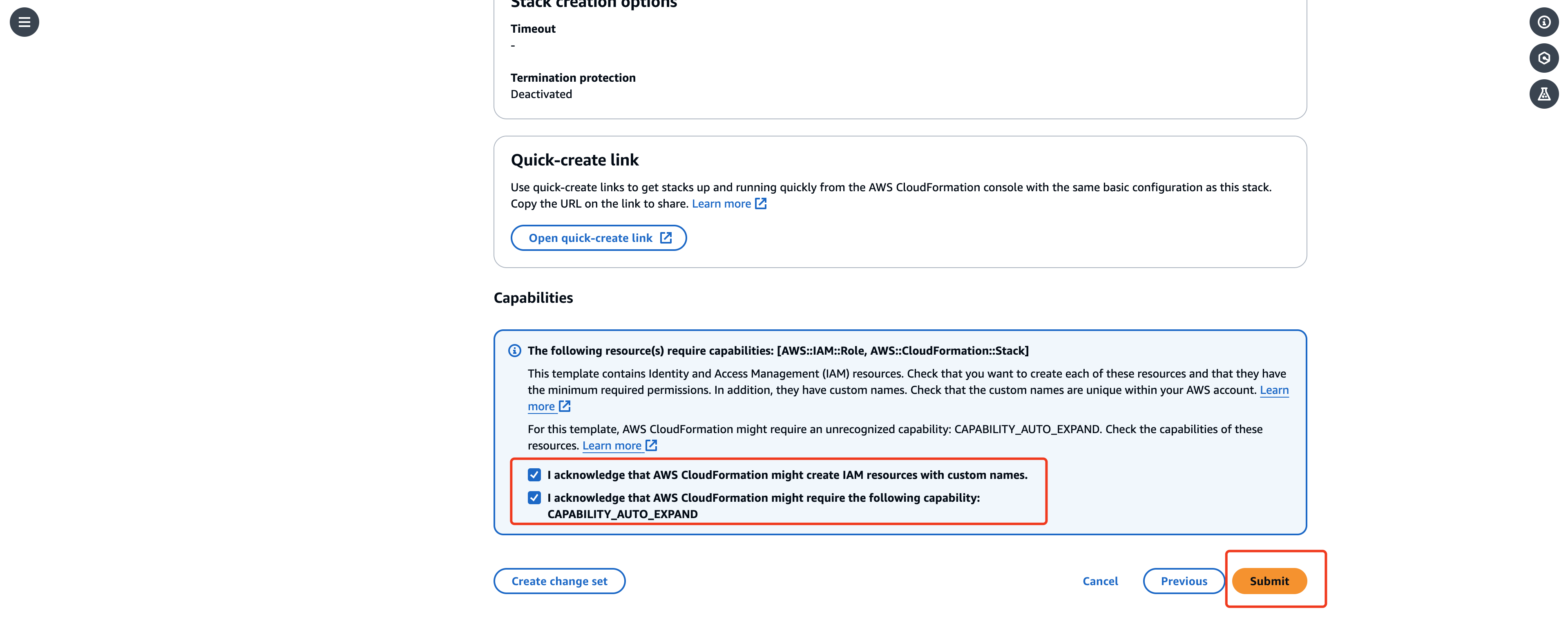
-
cloudformation 的
output会输出 Dify 的访问地址
配置拥有Bedrock访问权限的AK SK
在IAM控制台—Users—Create user,配置user name后创建一个不带console权限的IAM user
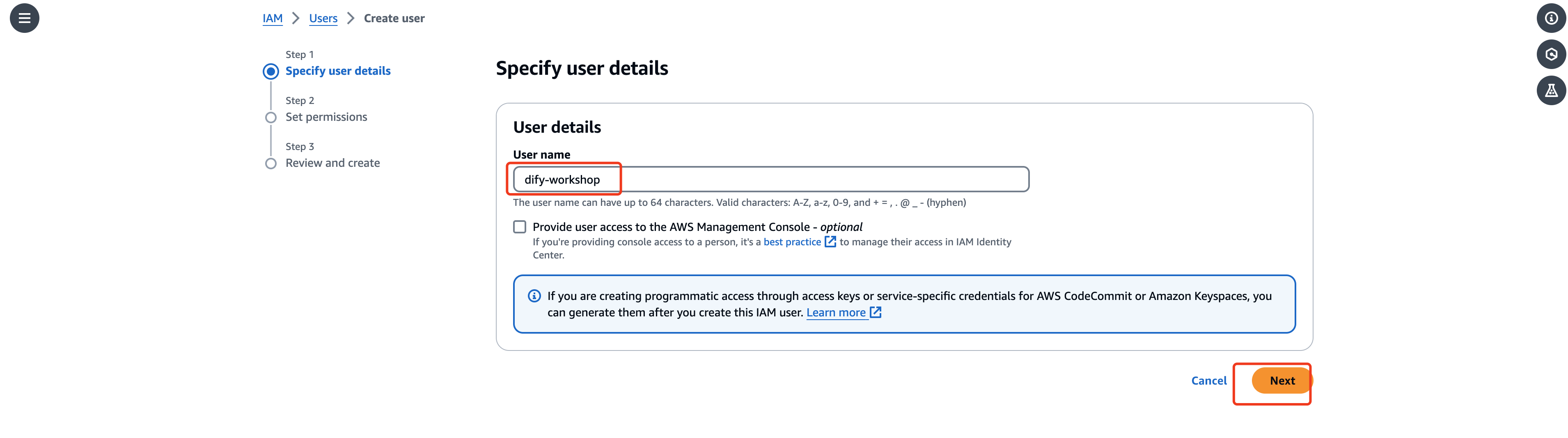
IAM user创建完成后,单击打开创建的IAM user,添加权限
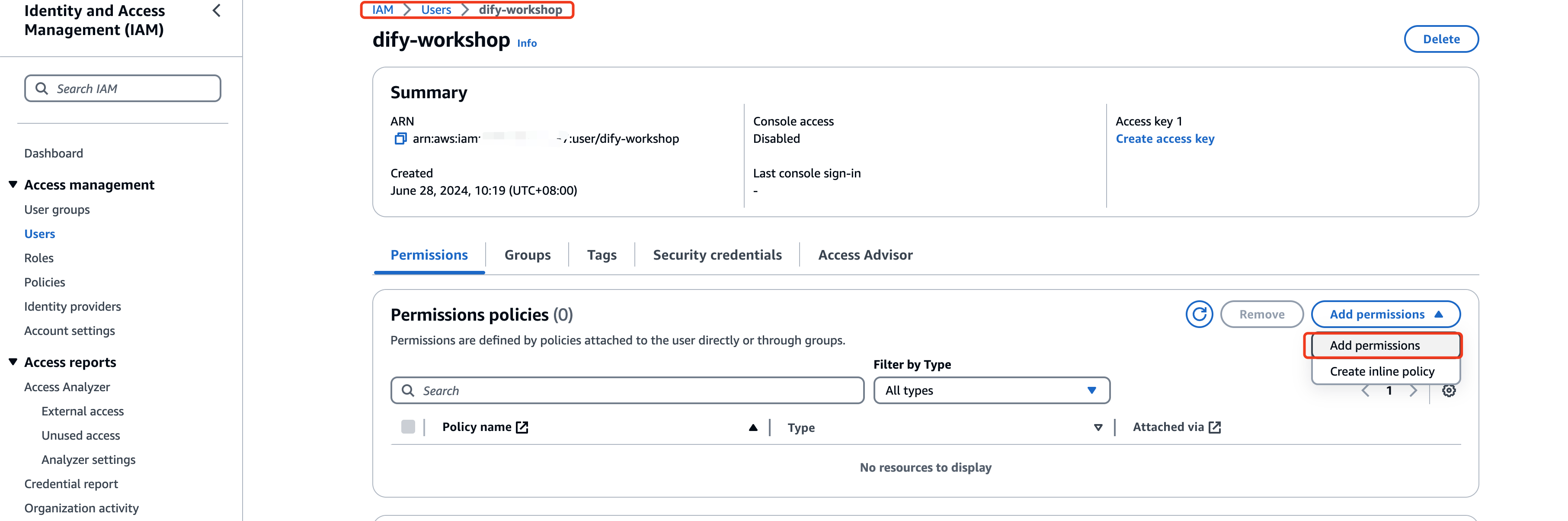
选择AmazonBedrockFullAccess权限
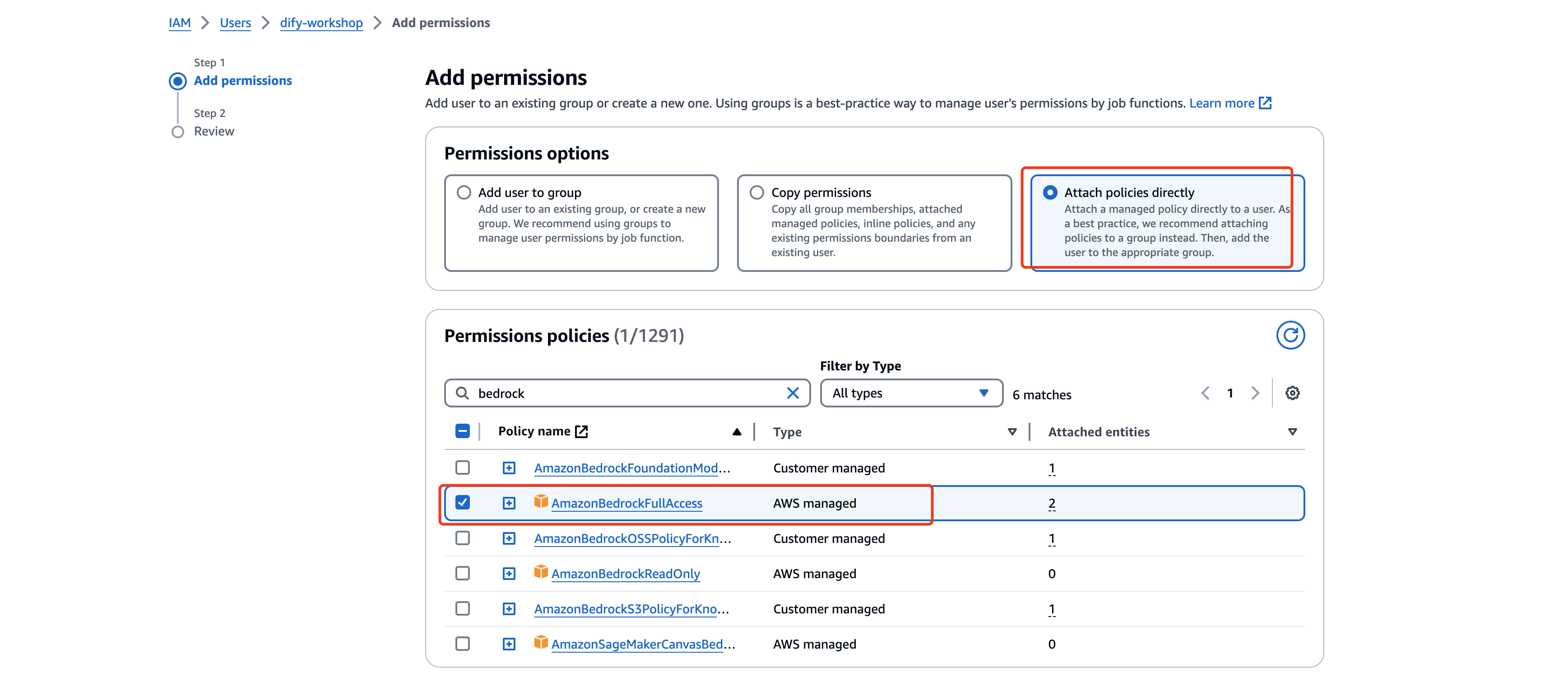
点击Create access key创建AK SK
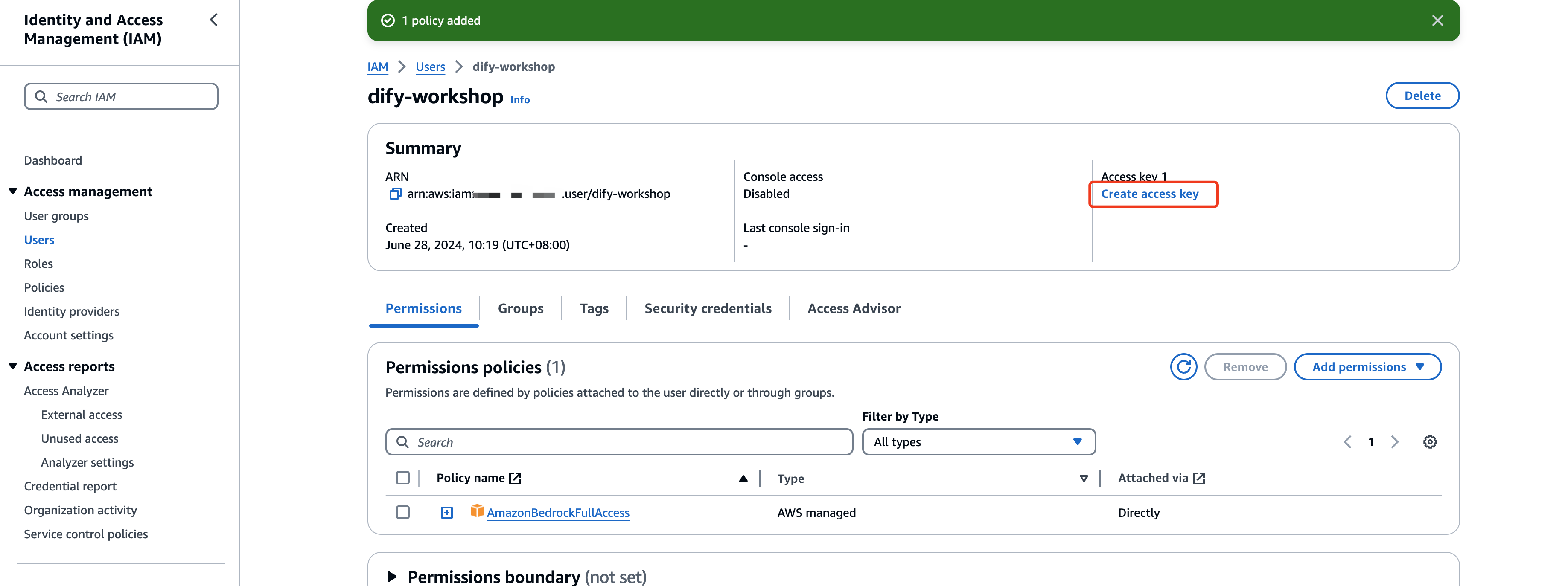
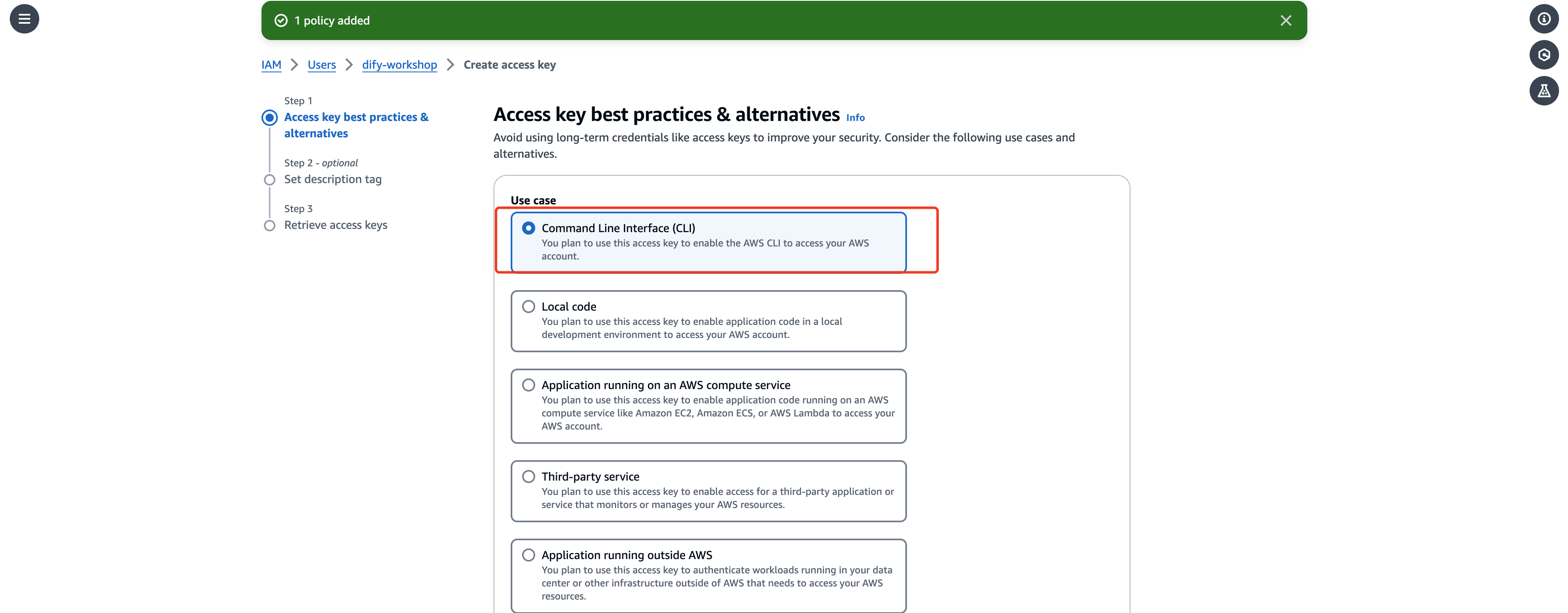

依次点击next及Create access key就可完成创建,记录好生成的AK SK用于后续步骤
Important
不建议在生产环境使用AK/SK,请确保在结束后删除此步骤配置的IAM User,请按照清理实验环境的步骤操作。
配置Bedrock的访问权限
- 使用Cloudformation stack的outputs输出的地址访问Dify
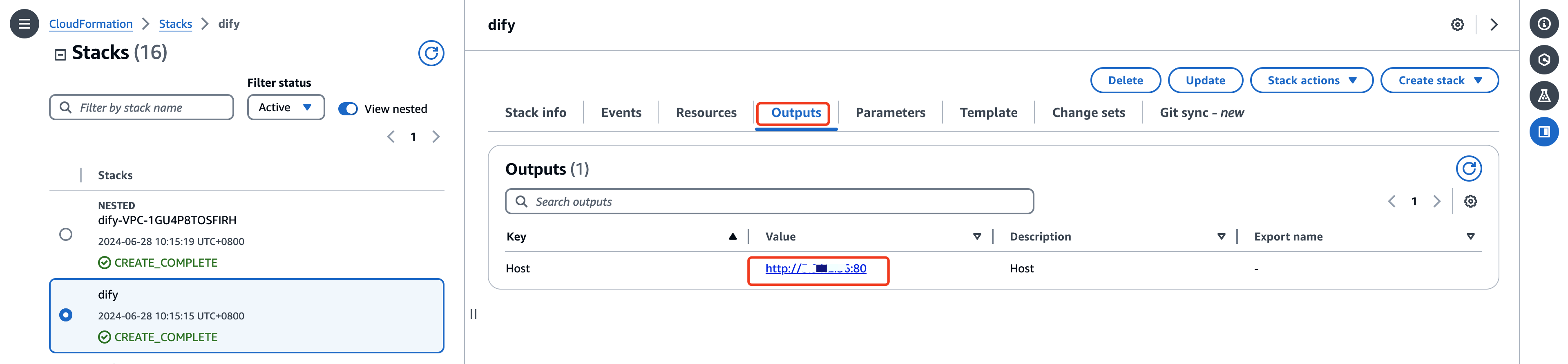
- 设置管理员账户

- 登录
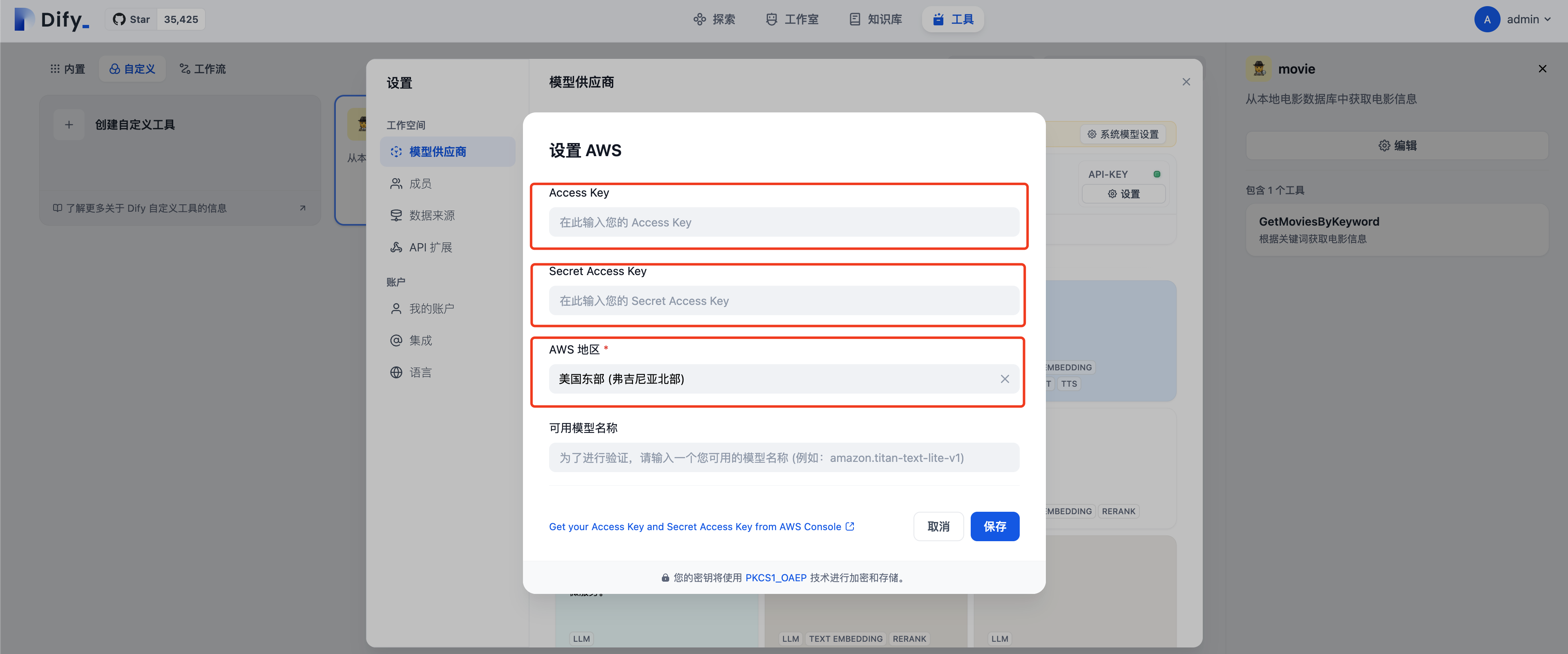
- 点击页面右上角 用户名→设置→模型供应商→Bedrock,配置前一步创建的拥有Bedrock权限的AK SK,region选择账户中已经拥有Bedrock model访问权限的region
Important
Amazon Bedrock 支持的region
Lab1-ChatBot with RAG
本章节我们将创建一个使用知识库内容来回答问题的对话机器人:
- 首先我们会用Dify的知识库功能创建知识库。
- 然后创建一个聊天助手应用,并体验开箱即用的聊天增强以及工具箱中的内容审核和标注回复等功能。
- 最后在聊天助手中导入知识库作为上下文验证效果。
创建知识库
Step1 知识库创建
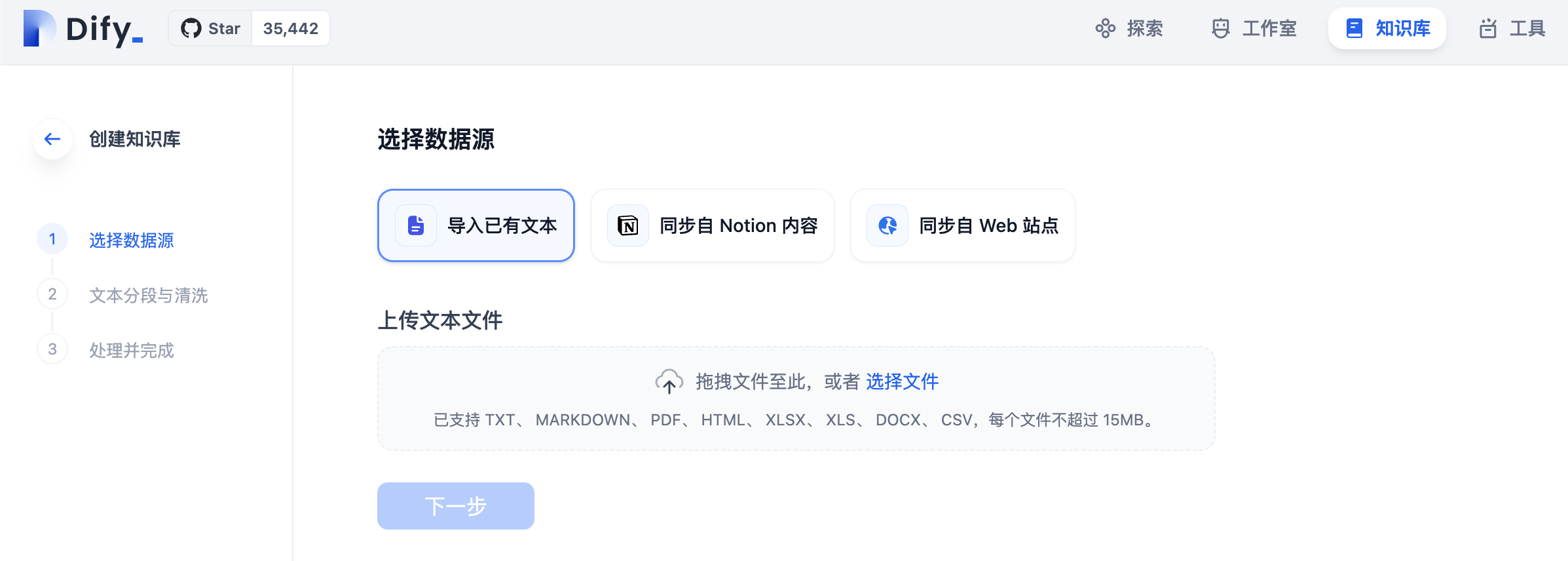
在Dify控制台的知识库功能区点击创建知识库,DIfy目前支持三种方式的数据源(v0.6.11),本实验我们使用导入已有文本的方式。
选择“导入已有文本”,上传刚刚下载的文档,然后点击下一步按钮导入
Step2 设置文本分段和清洗
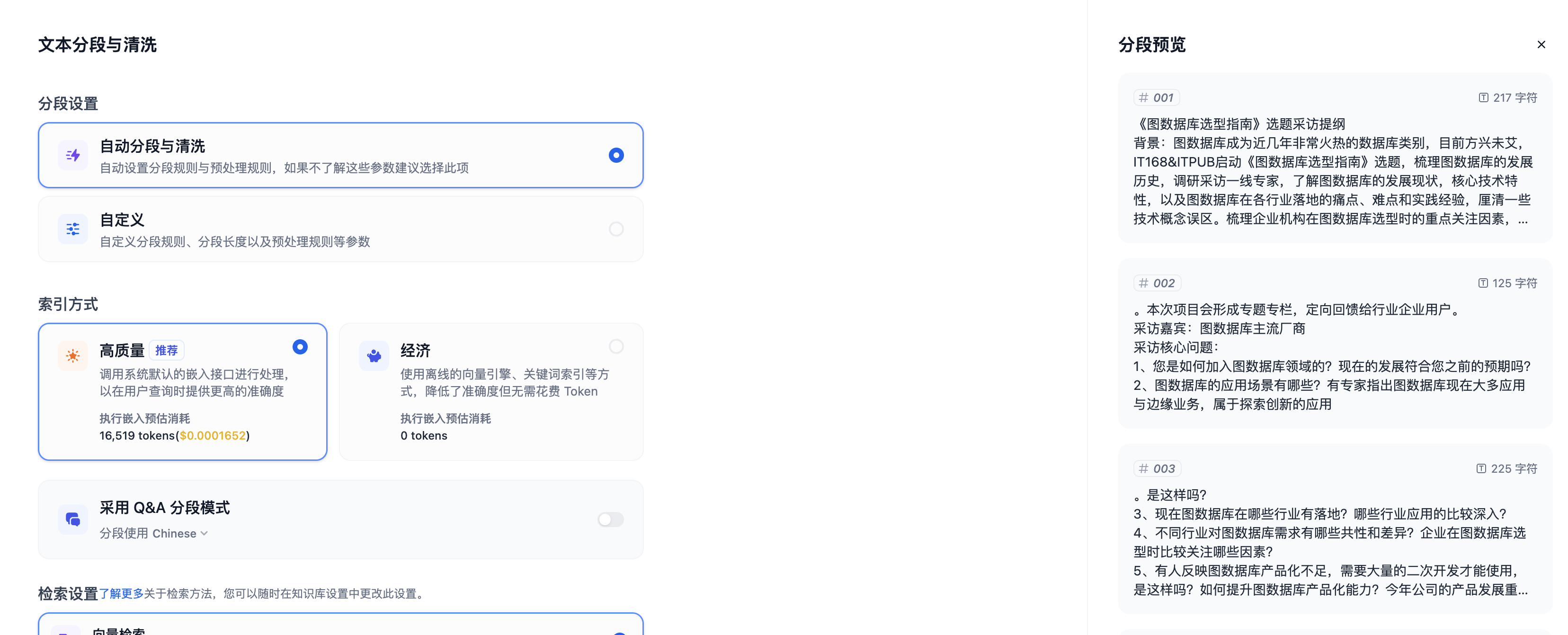
Dify以一种实时交互的方式展示切片信息,方便对chunk不熟悉的用户有一个直观的感受,并同时提供了丰富的分段逻辑和切片清洗逻辑。
我们先选择“自动分段与清洗”这种方式观察一下右边的分段预览,这里我们可以看到Dify智能化的将文本分段大小不等的段落。
切换到“自定义”分段,我们可以看到dify系统支持进行自定义的切片逻辑,在自定义分段设置中可以对文档内容中的特殊标识符,特殊字符等进行处理,也可以对分段的长度和重叠进行设置,此处请自行尝试调整分段参数

因为不同数据格式,比如图片、表格、分栏等,切片对搜索精准率的影响非常大,甚至中英文等切片规则也有较大差异。这些都需要在实际工程中进行验证测试,不能一概而论,而Dify为用户提供了非常大的灵活性。
Step3 建立索引
Dify提供了三种索引方式:
- 第一种高质量模式,通过Embedding进行向量化,后续依赖向量数据库的近似匹配完成搜索,需要消耗一定的token;
- 第二种经济模式,通过传统关键词搜索的方式构建索引,采用类似ES的组件完成搜索,降低了准确度但无需花费 Token,这种方式倒排索引仅提供了Top_K结果的返回,有兴趣的同学可以自行测试。
- 第三种Q&A模式(仅社区版支持),在文档经过分段后,经过总结为每一个分段生成 Q&A 匹配对,当用户提问时,系统会找出与之最相似的问题,然后返回对应的分段作为答案。这种方式更加精确,因为它直接针对用户问题进行匹配,可以更准确地获取用户真正需要的信息。
实验中我们选择高质量索引方式
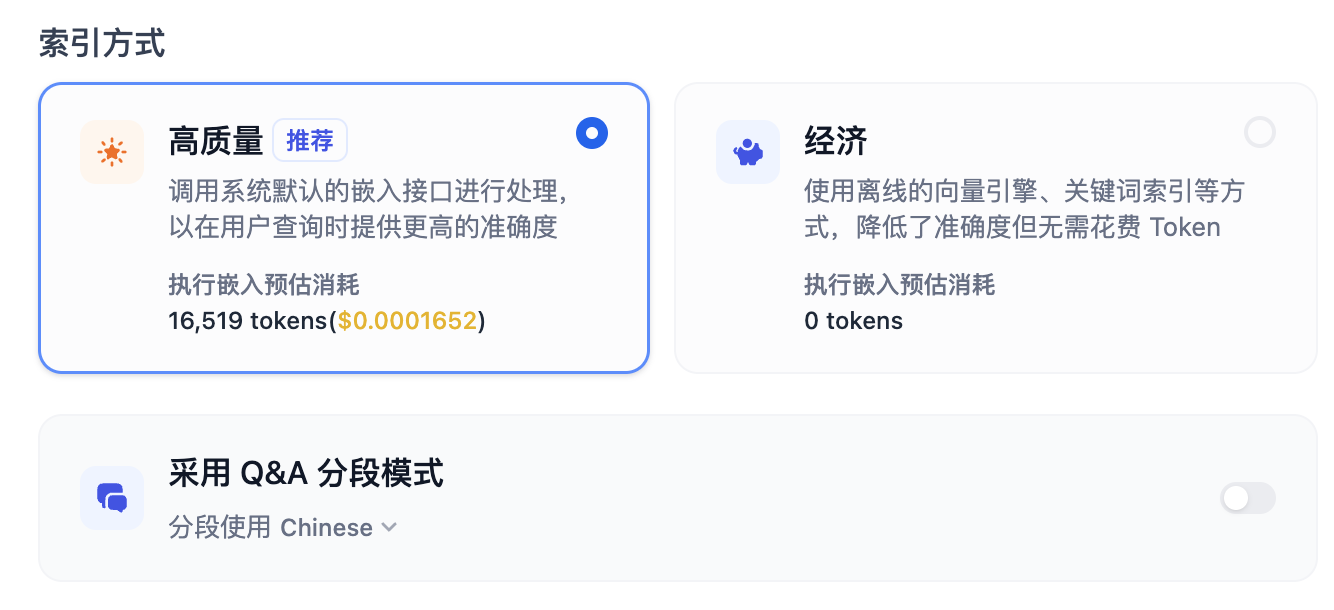
高质量索引支持3种类型的检索设置:
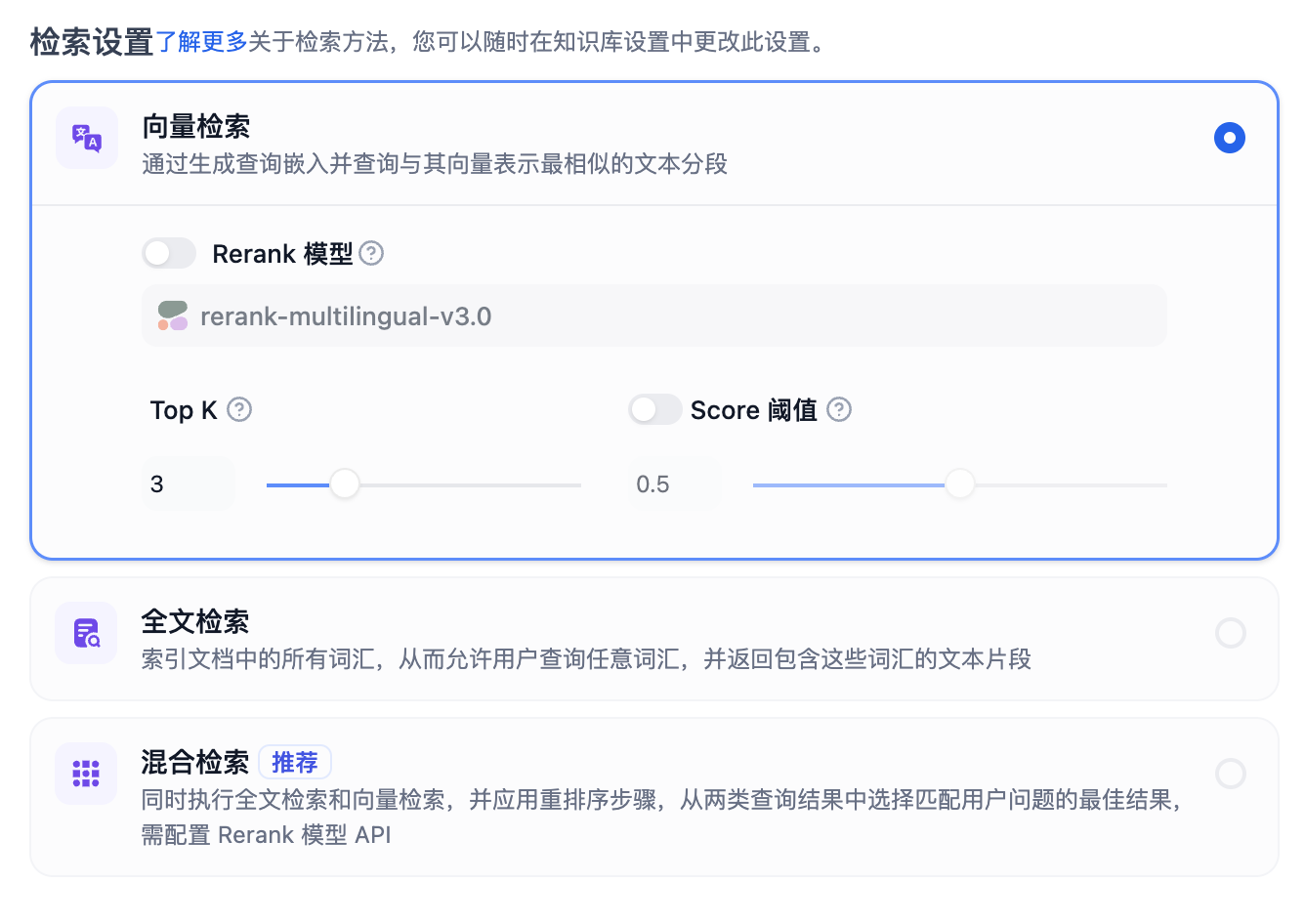
- 向量检索
- 全文检索
- 混合检索,混合检索=向量检索+全文检索。
Rerank模型可以大大提高RAG召回的准确率。如果在“模型供应商”页面配置了支持 Rerank 的模型后,在检索设置中打开“Rerank 模型”,系统会在语义检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
这里我们先选择不带Rerank模型的向量检索。点击“保存并处理”,等待文档处理结束
等待embedding处理完成,点击“前往文档”,查看向量化后的文档
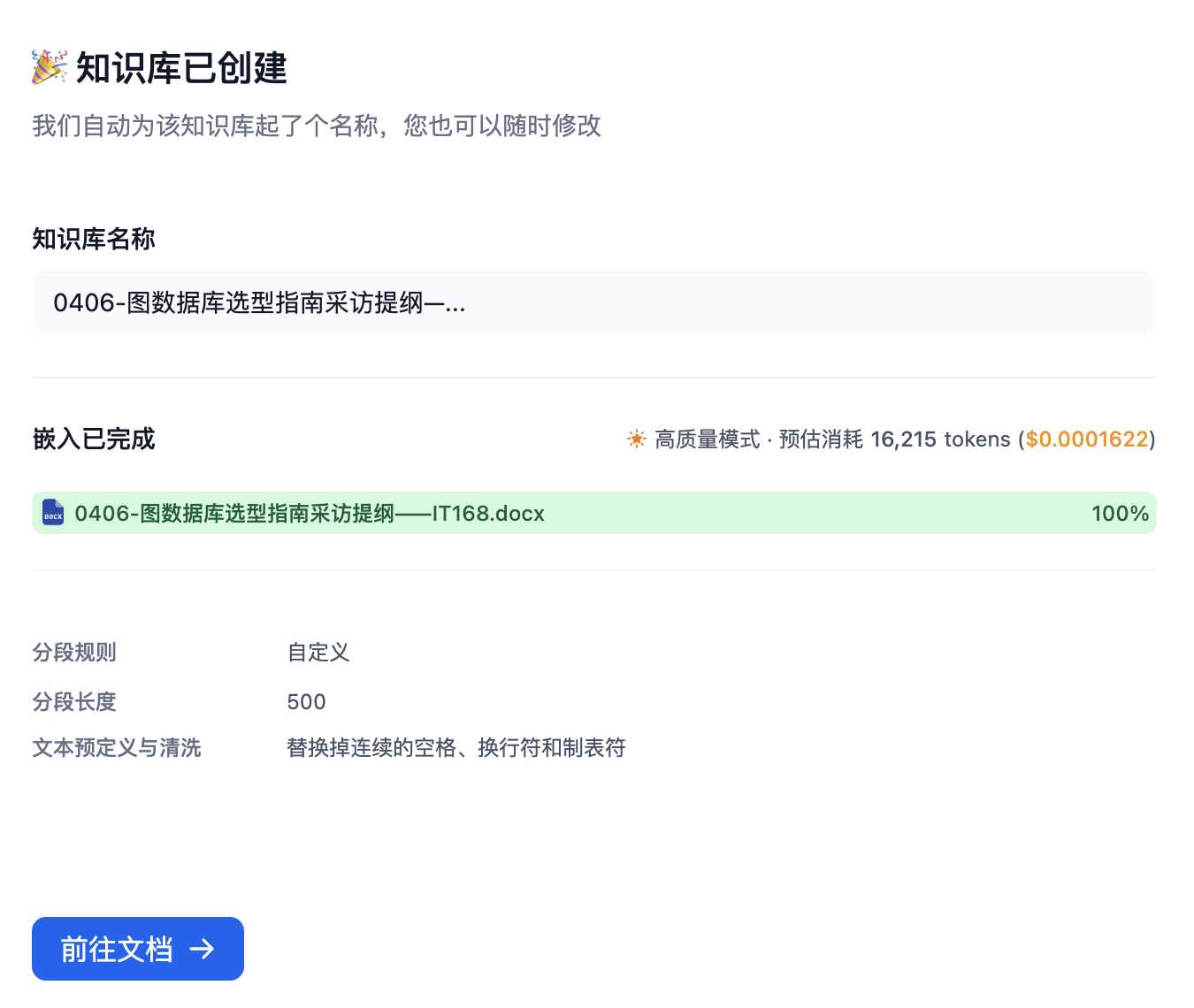
Step4 文档维护(optional)
文档处理完成以后,我们通常要对文档进行维护,包括查看文本分段,检查分段质量,添加文本分段,编辑文本分段,以及元数据管理(元数据将被用于知识库的分段召回过程中,作为结构化字段参与召回过滤或者显示引用来源)。 这部分内容实验中作为可选内容,请自行参考文档链接进行操作体验:
知识库构建完成以后,我们可以接下来创建一个聊天助手应用,然后让聊天助手基于知识库的内容进行回答。
创建聊天助手应用
创建聊天助手应用
聊天助手chatbot是一种对话型应用,采用问答会话模式与用户持续对话。对话型应用通常可以应用在客户服务、在线教育、医疗保健、金融服务等领域。这些应用可以帮助组织提高工作效率、减少人工成本和提供更好的用户体验。
接下来我们将创建一个基础编排的聊天助手,包括对话前提示词,变量,上下文,开场白和下一步问题建议等等,我们还将从工具箱中选择内容审核,标注回复等工具,为编排提供更多的功能。
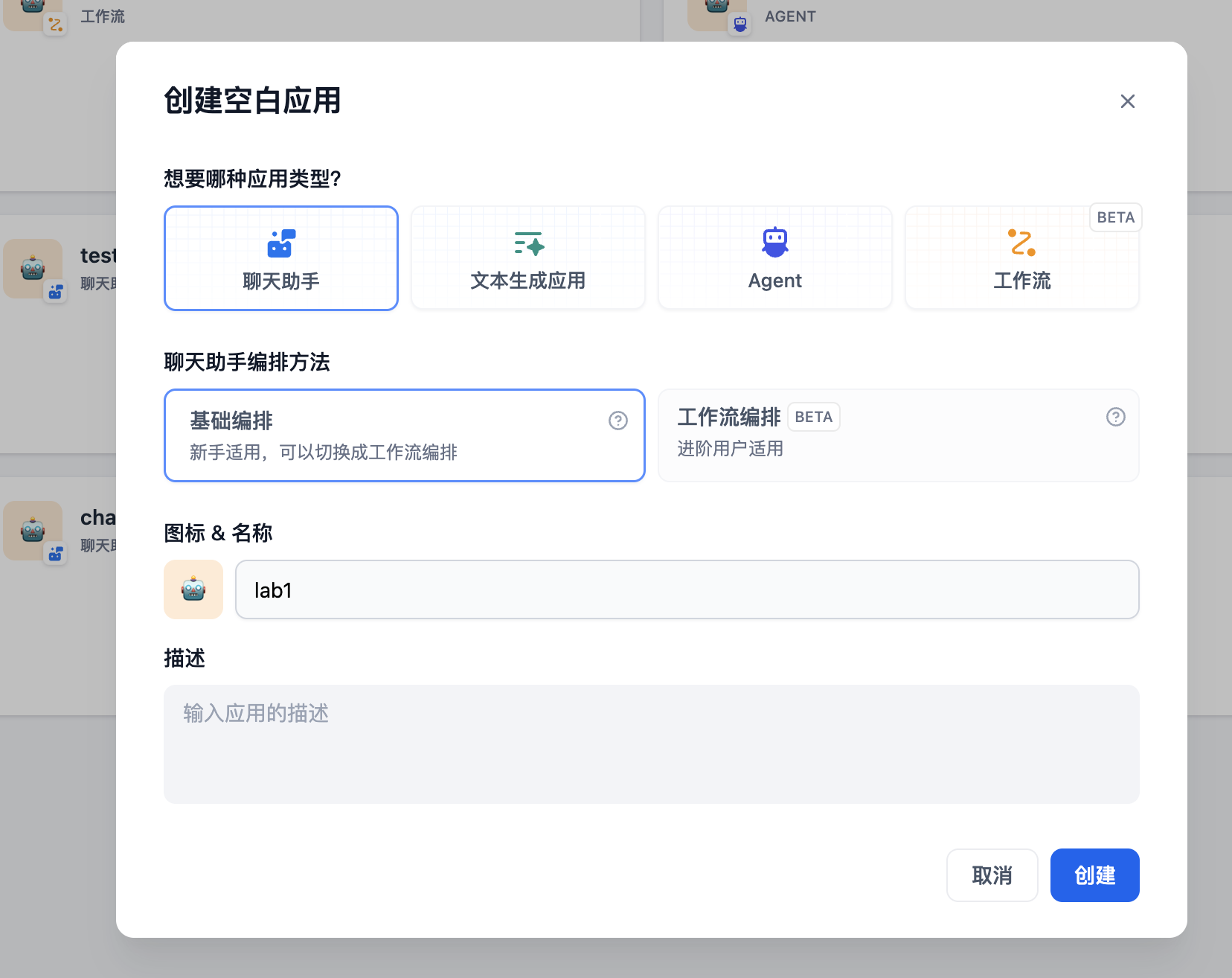
Step1 创建聊天助手
首先我们在”工作室“标签下点击“创建空白应用”,选择“聊天助手”,“基础编排”,然后点击“创建”
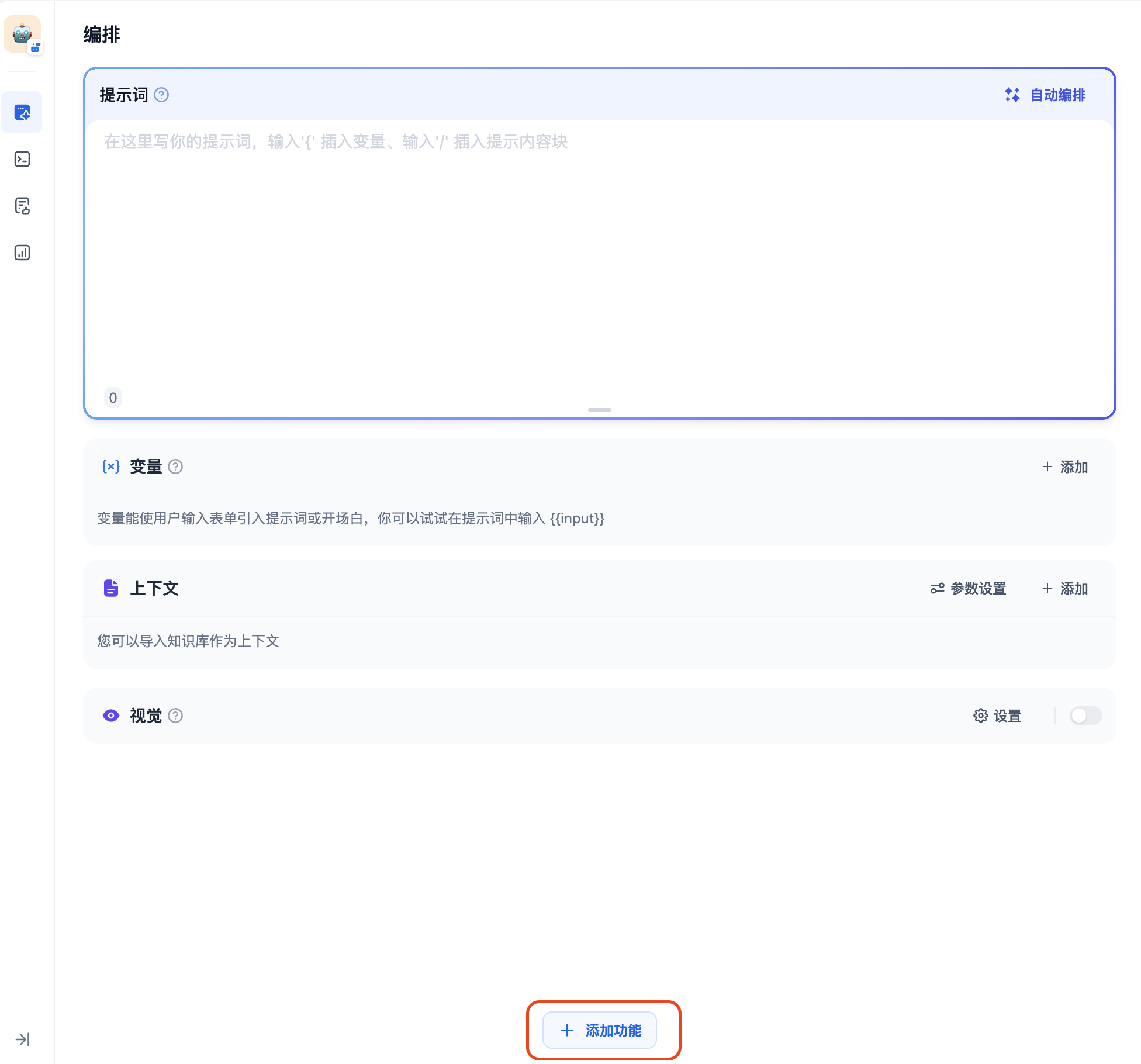
然后在“编排”页面,我们点击最底部的“+添加功能”,把所有功能都打开
在内容审查设置对话窗口中,我们选择“关键词”,输入测试关键词和预设回复(自定义),并打开”输入内容审查“和”输出内容审查“,然后点击保存
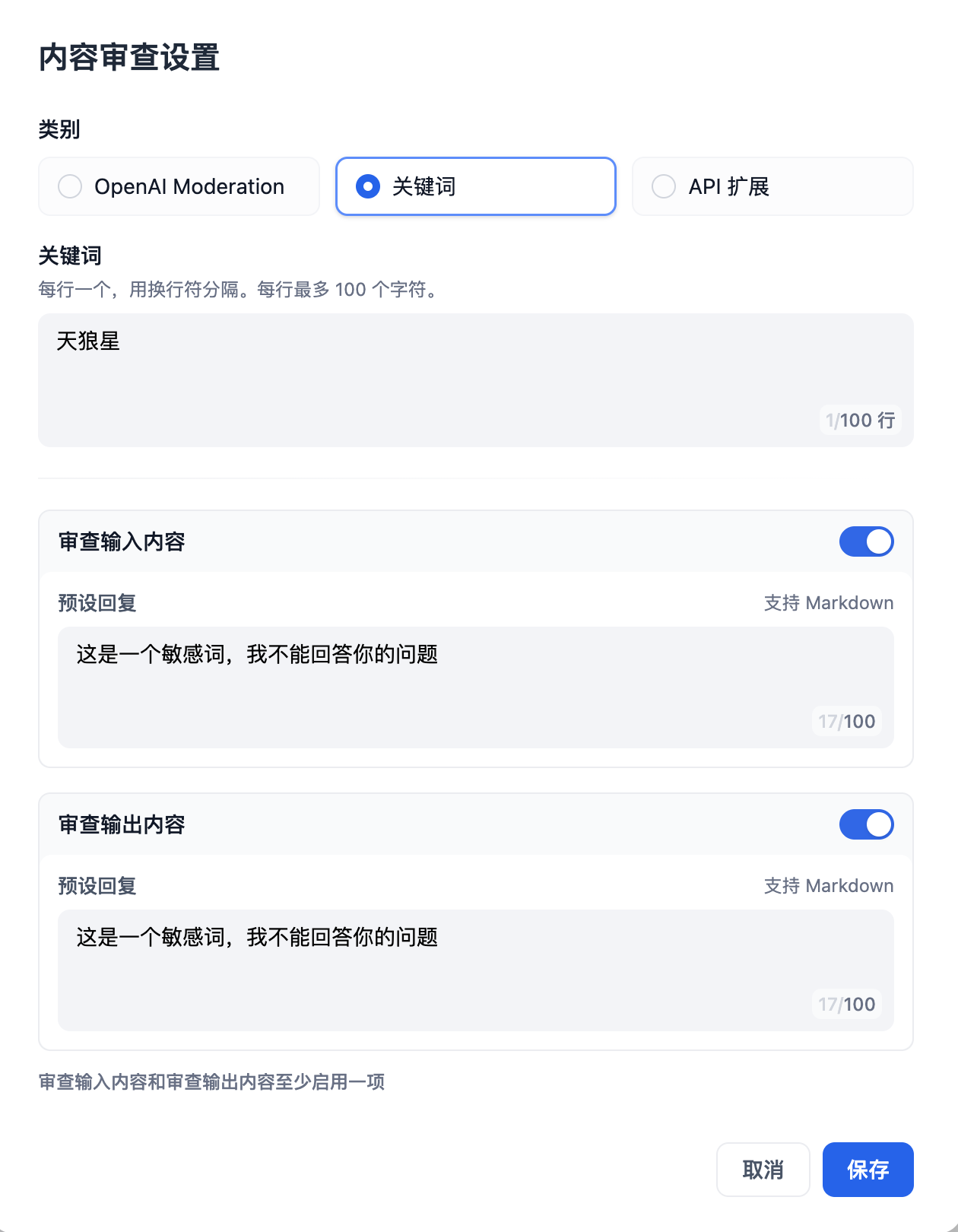
内容审查功能提供了三种类别,感兴趣请参考敏感内容审查 。
添加完成后在界面上我们可以看到聊天增强和工具箱的功能都显示出来了,接着我们编辑对话开场白,设置一个自己的个性化问候语
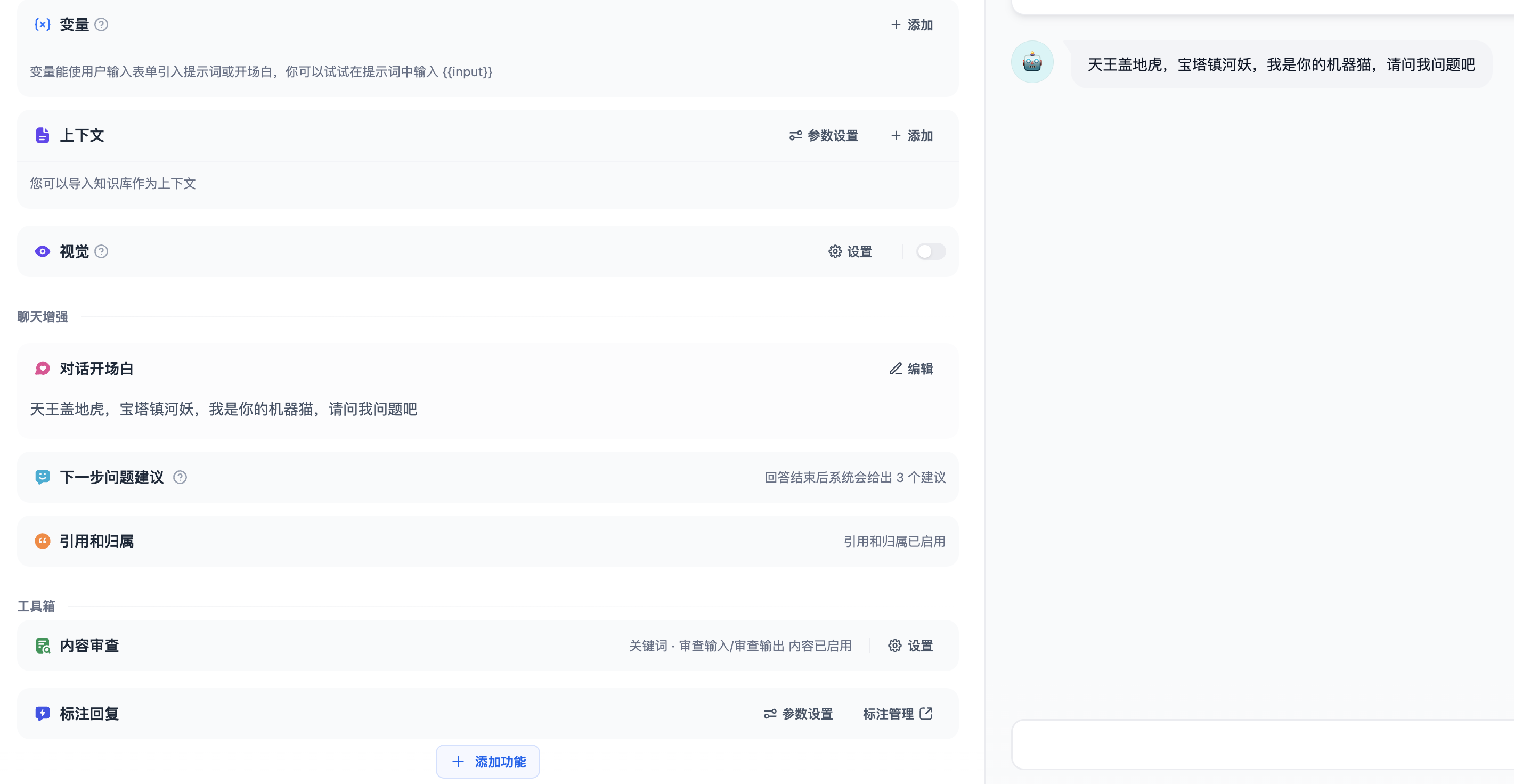
现在我们在右边调试与预览界面底部对话框输入我们的问题,例如“我想要一个天狼星”,我们可以看到,聊天助手没有访问大模型,直接通过内容审查返回了警告信息
Step2 添加标注回复
标注回复功能相当于提供了另一套检索增强系统,可以跳过 LLM 的生成环节,规避 RAG 的生成幻觉问题。
标注回复功能通过人工编辑标注为应用提供了可定制的高质量问答回复能力。 适用情景:
- 特定领域的定制化回答: 在企业、政府等客服或知识库问答情景时,对于某些特定问题,服务提供方希望确保系统以明确的结果来回答问题,因此需要对在特定问题上定制化输出结果。比如定制某些问题的“标准答案”或某些问题“不可回答”。
- POC 或 DEMO 产品快速调优: 在快速搭建原型产品,通过标注回复实现的定制化回答可以高效提升问答结果的生成预期,提升客户满意度。
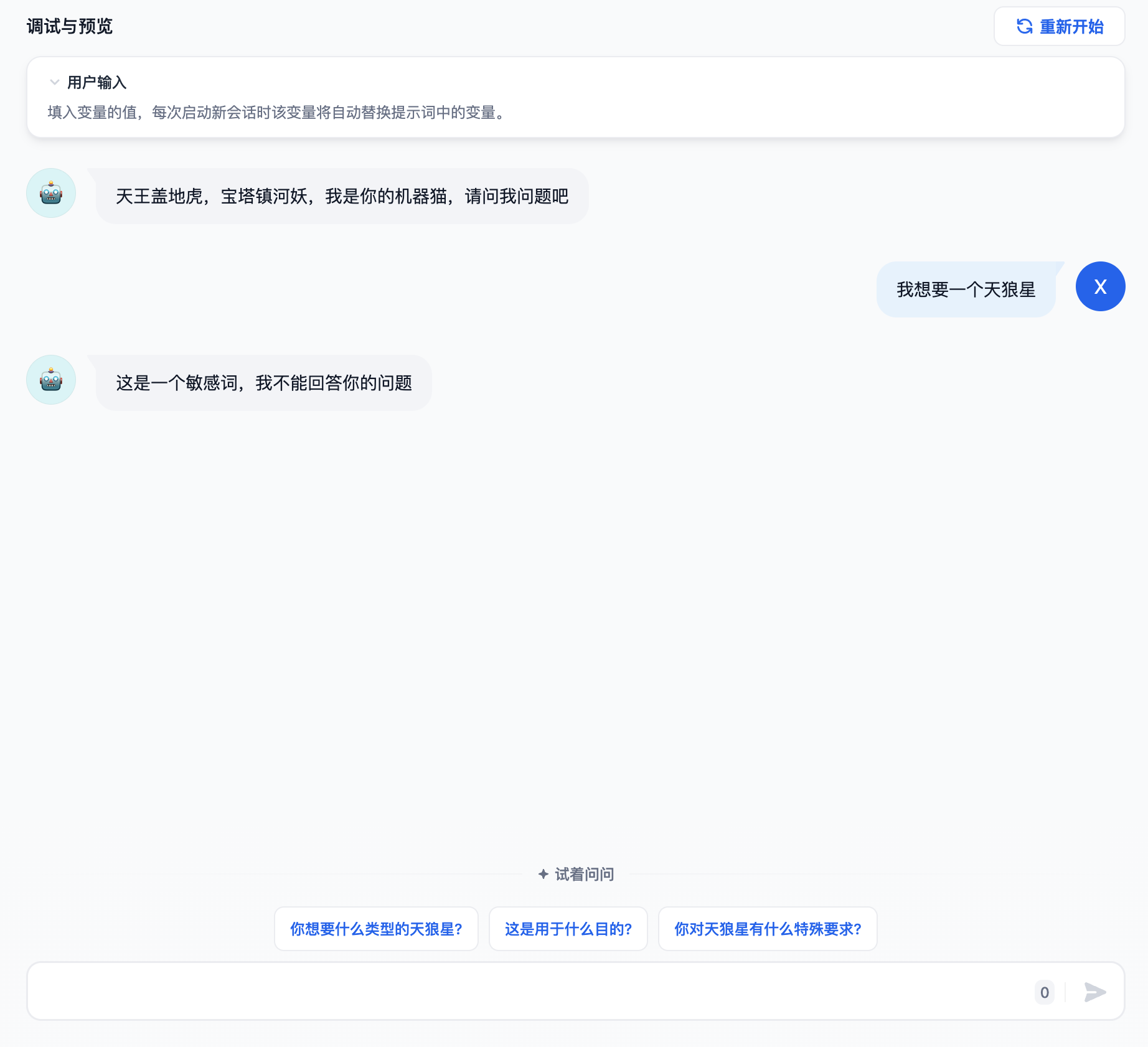
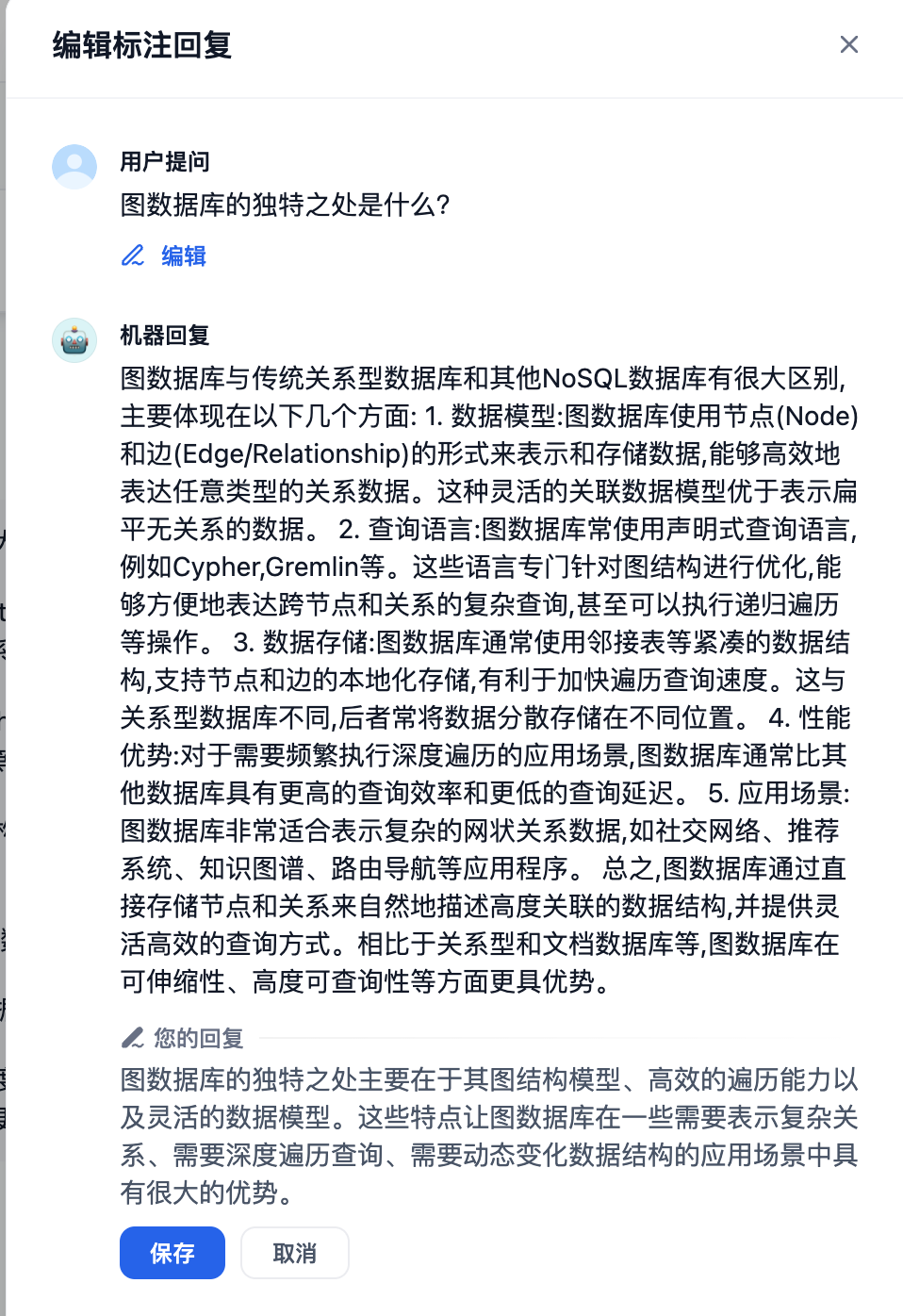
我们在调试与预览界面输入“图数据库的独到之处是什么?“这个问题,我们看到大模型给出的答案还不错,但是我们想更优化一下回答,这里我们就可以使用标注回复的功能对回复进行标注。请点击下图红圈中的“编辑标注”
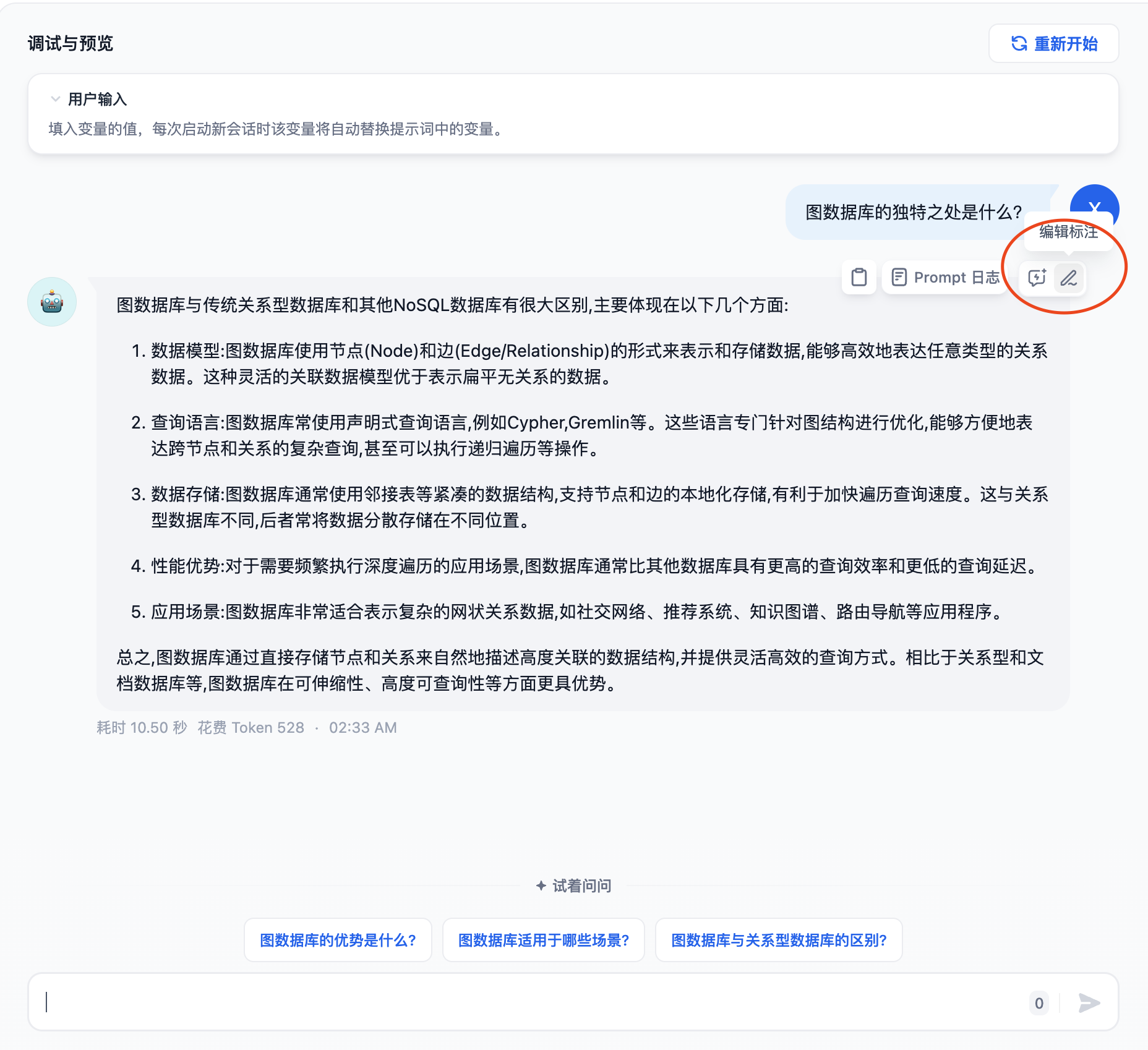
然后在“编辑标注回复”窗口中修改机器回复的内容,例如:
图数据库的独特之处主要在于其图结构模型、高效的遍历能力以及灵活的数据模型。这些特点让图数据库在一些需要表示复杂关系、需要深度遍历查询、需要动态变化数据结构的应用场景中具有很大的优势。
然后点击“保存”, Dify就自动将这样一对Q&A向量化保存下来,如果再有相同的问题,Dify会直接返回我们标注的内容
为Chatbot添加RAG
Step1 添加RAG
首先在聊天助手应用的提示词窗口输入以下提示词:
You are a helpful assistant.
Use the following context as your learned knowledge, inside <context></context> XML tags.
<context>
{{#context#}}
</context>
When answer to user:
- If you don't know, just say that you don't know.
- If you don't know when you are not sure, ask for clarification.
Avoid mentioning that you obtained the information from the context.
And answer according to the language of the user's question.
并在“上下文”部分点击“添加”,选择我们在前面实验中创建的知识库
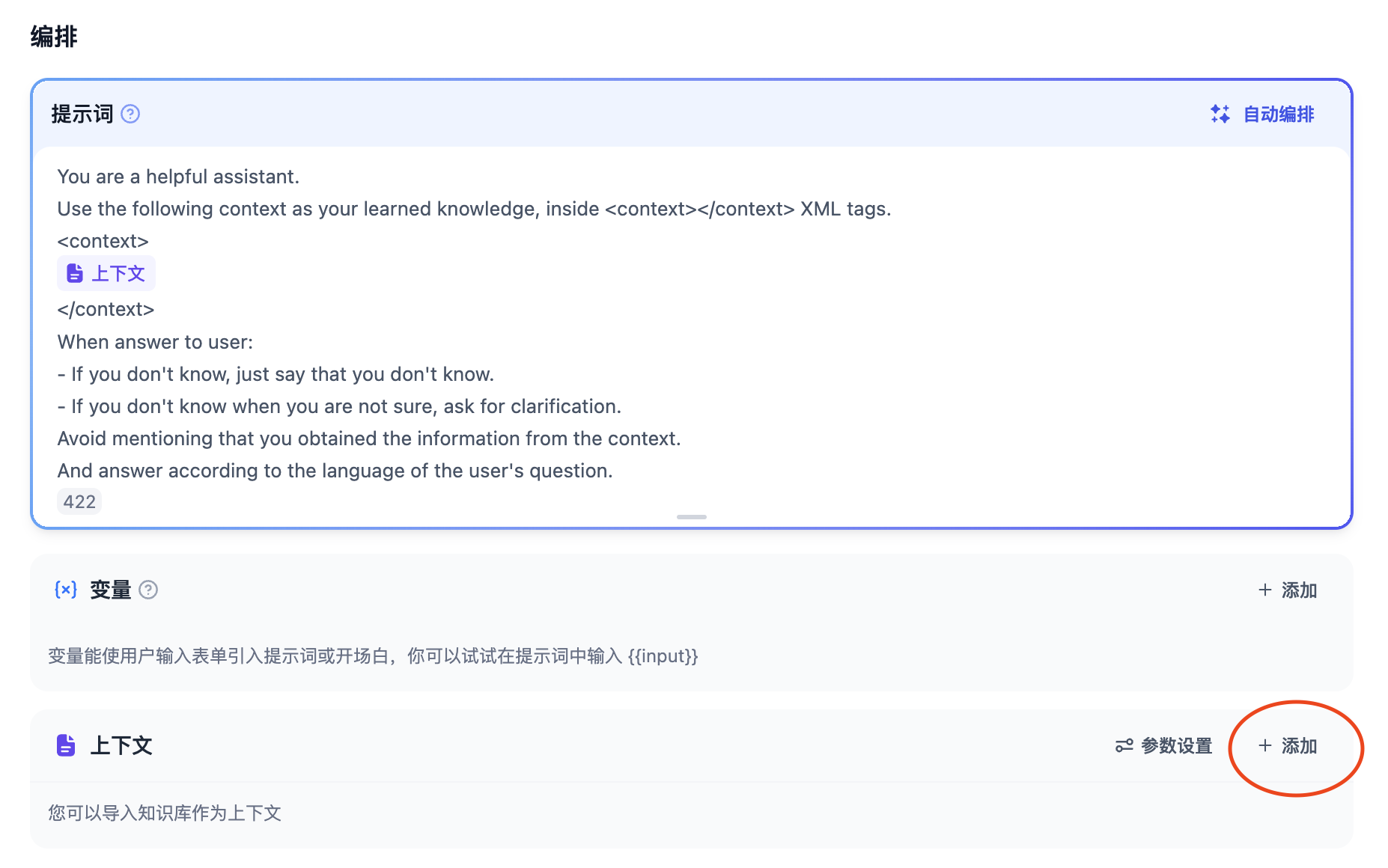
添加完成后,在上下文部分中就可以看到我们添加的知识库

根据实际需要,我们可以添加多个知识库。
Step2 验证效果
根据我们的提问,聊天助手会先在知识库中召回相似度高的片段,然后作为上下文嵌入到大模型调用的System Prompt中,再进行问题回答。
请学员自行完成后面的chatbot+RAG的测试,如果召回效果不好,请返回到“知识库”模块,点击最左边的“召回测试‘图标,测试召回效果
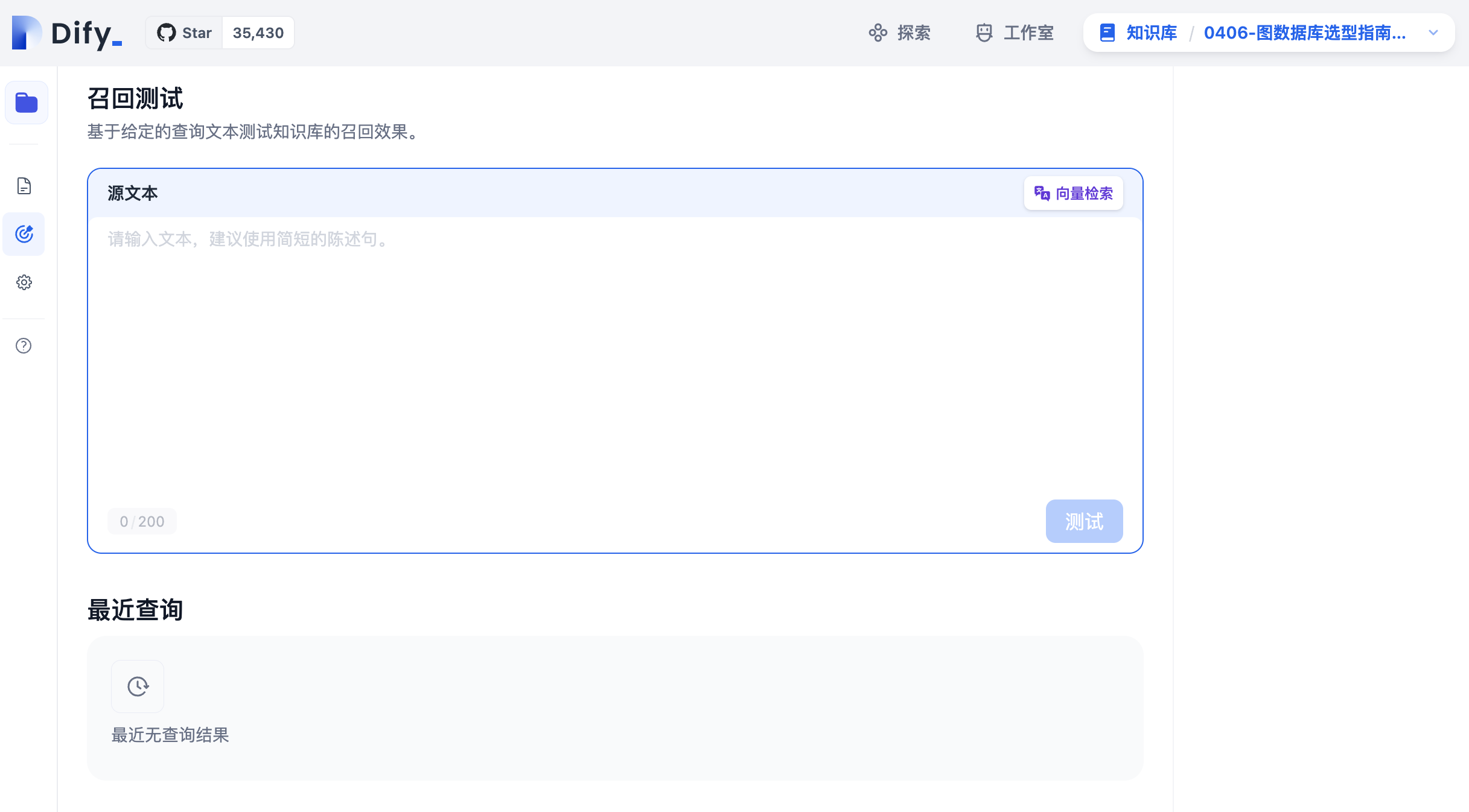
并点击”知识库设置”图标修改embedding模型和检索设置,以提高召回命中率。
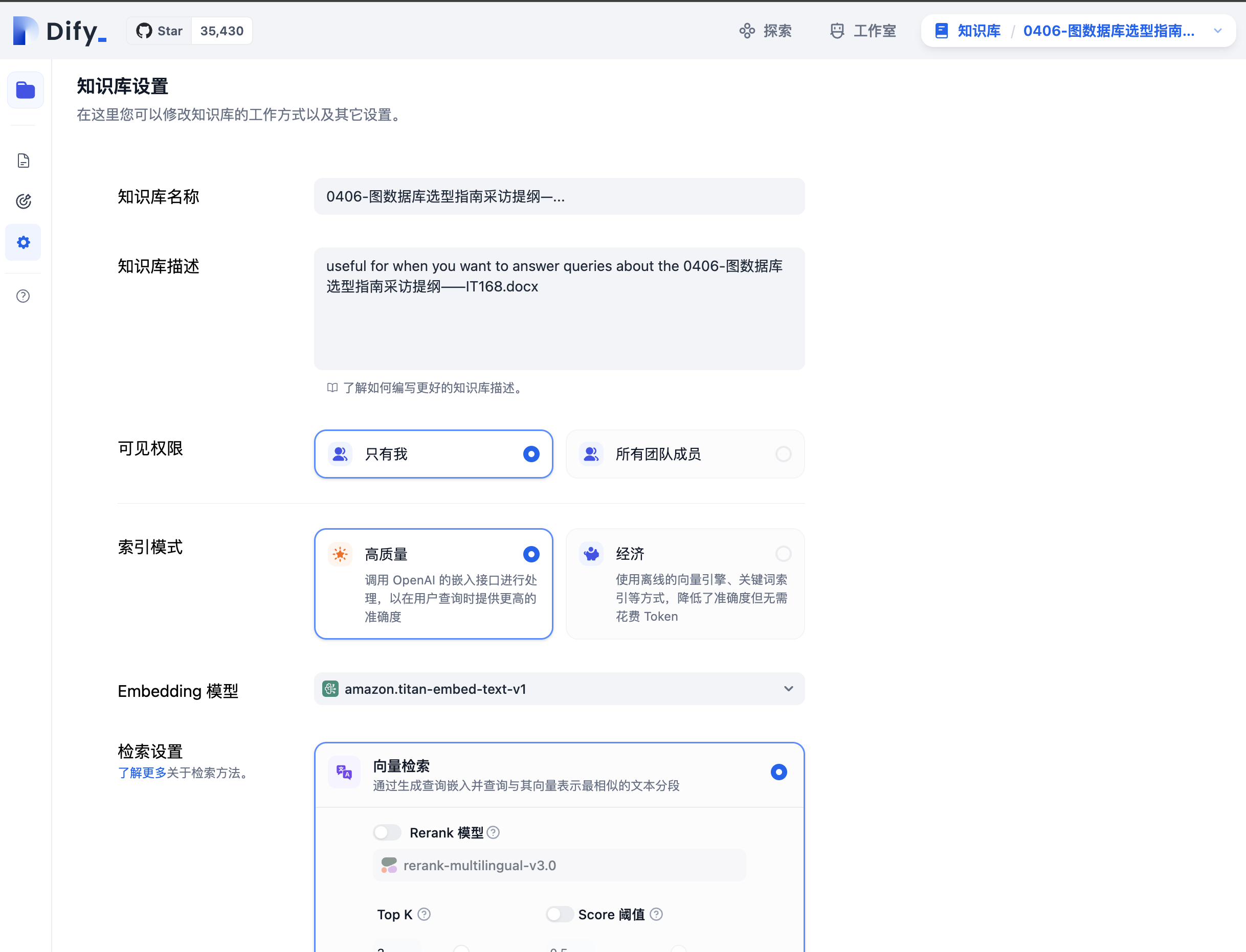
保存以后返回到聊天助手应用,重新测试回答的效果是否满意。
Lab1到此结束,恭喜您已经学习和掌握了在Dify中如何构建一个带知识检索的聊天机器人。
Lab2-使用Dify构建AI Agent
本章节我们将搭建一个简单的API服务并接入Dify的自定义工具,然后再结合Dify内置的工具快速构建一个电影搜索助手的Agent应用。
创建自定义工具
Step1 实现Agent可以调用的后端API
后端API
首先,我们要实现一个可以让Agent调用的API服务,这里我们使用社区的一个开源项目 dify-with-classical-search :
-
基于Meilisearch和包含了 1 万 5000 千部电影简介的数据集构建一个简单的电影信息查询API。
-
可以响应HTTP GET/POST请求中的
keyword参数,返回电影简介信息 -
示例:
curl http://127.0.0.1:8888/new-api-for-dify?keyword=sky {"result":"- 标题:Sky Captain and the World of Tomorrow\n- 简介:When gigantic robots attack New York City, \"Sky Captain\" uses his private air force to fight them off. His ex-girlfriend, reporter Polly Perkins, has been investigating the recent disappearance of prominent scientists. Suspecting a link between the global robot attacks and missing men, Sky Captain and Polly decide to work together. They fly to the Himalayas in pursuit of the mysterious Dr. Totenkopf, the mastermind behind the robots.\n\n- 标题:Sky Fighters\n- 简介:Les Chevaliers du ciel (English: Sky Fighters) is a 2005 French film directed by Gérard Pirès about two air force pilots preventing a terrorist attack on the Bastille Day celebrations in Paris. It is based on Tanguy et Laverdure, a comics series by Jean-Michel Charlier and Albert Uderzo – of Astérix fame, which was also made into a hugely successful TV series from 1967 to 1969 making Tanguy and Laverdure, the two main heroes, part of popular Francophone culture.\n\n- 标题:Sky High\n- 简介:Set in a world where superheroes are commonly known and accepted, young Will Stronghold, the son of the Commander and Jetstream, tries to find a balance between being a normal teenager and an extraordinary being.\n\n"}
部署后端API
我们将复用部署了Dify的EC2实例,在EC2控制台使用public ipv4 address过滤找到部署了Dify的EC2实例

使用Session Manager方式连接到实例
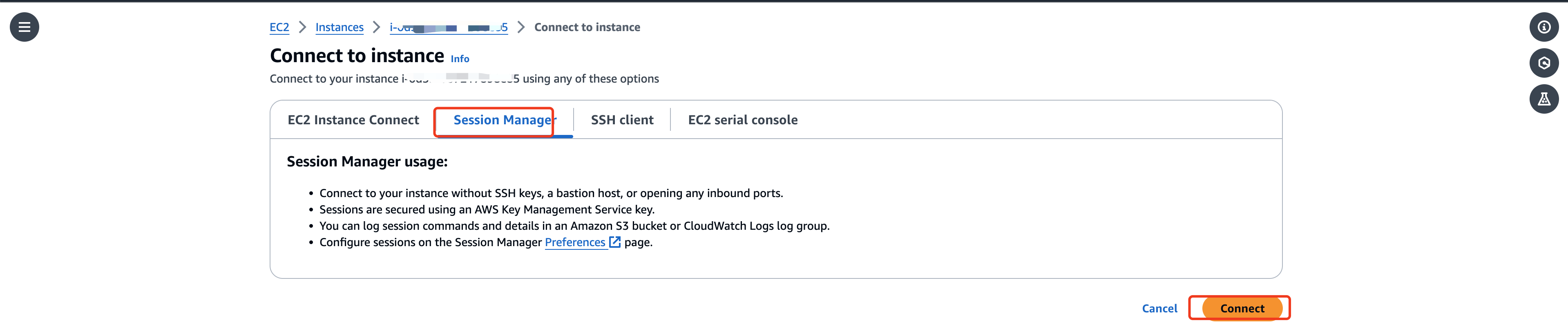
1
2
3
4
5
6
7
8
9
10
11
12
13
# 切换到root
sudo su -
# 安装golang
yum install golang -y
# clone repo
git clone https://github.com/luanluandehaobaoman/dify-with-classical-search.git
# 启动搜索引擎
cd dify-with-classical-search/meilisearch/
docker-compose up -d
go run main.go
# 启用API服务
cd ../dify/
nohup go run main.go &验证:
curl 127.0.0.1:8888/new-api-for-dify?keyword=sky
确认能检索到信息再进行下一步操作
配置安全组
我们需要放行实例的8888端口,以便让外部可以访问,在EC2控制台,单击打开Dify的EC2实例的安全组
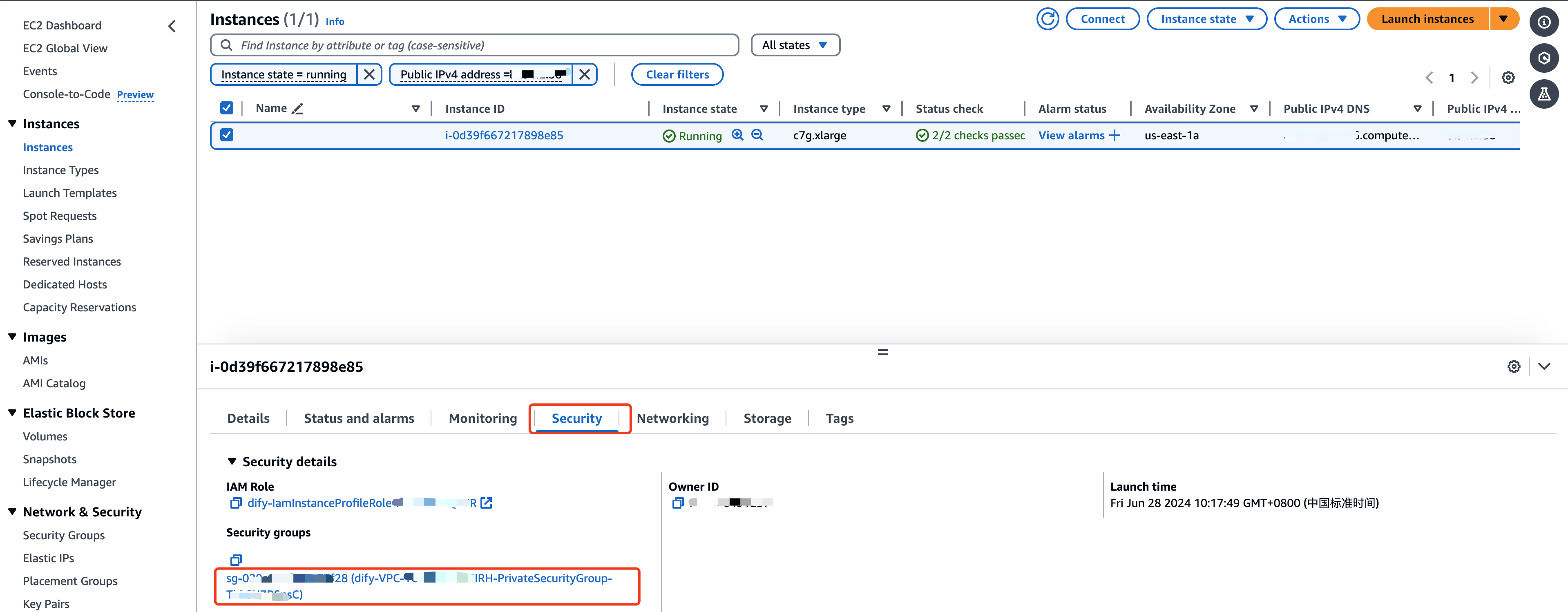
点击Edit inbound rules - Add rule 添加可被任意地址访问8888端口的规则
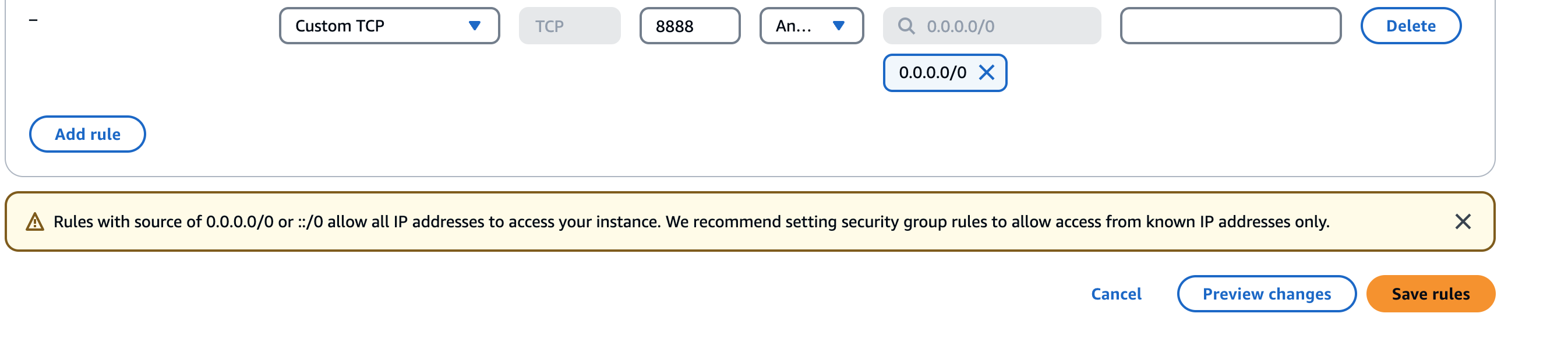
Important
此处为了实验目的需要公开端口到互联网,生产环境请谨慎公开端口
Step2 配置自定义工具
在DIfy控制台创建自定义工具

为工具添加名称和Schema
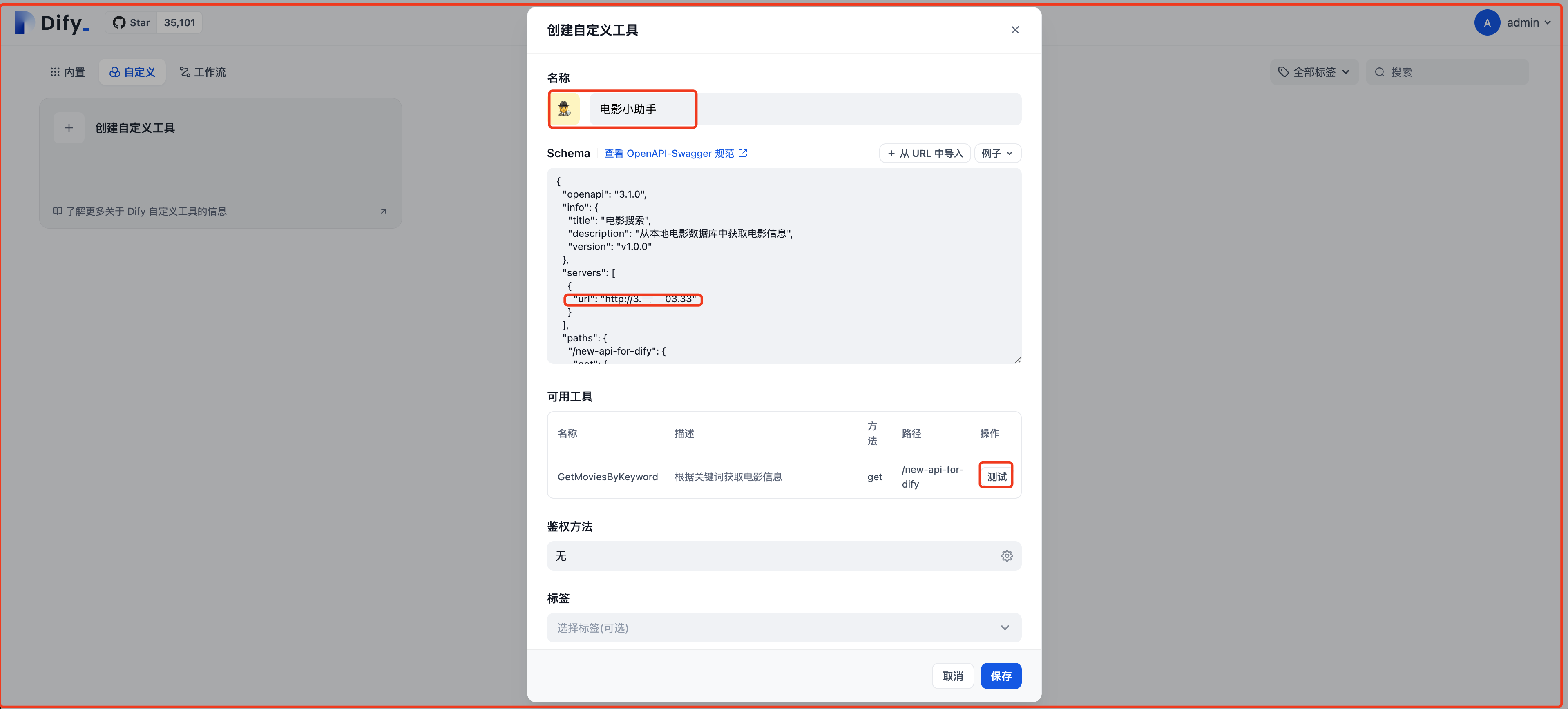
Schema内容如下,替换url为DIfy实例的Public IP+8888端口,http://Public IP:8888
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
{
"openapi": "3.1.0",
"info": {
"title": "电影搜索",
"description": "从本地电影数据库中获取电影信息",
"version": "v1.0.0"
},
"servers": [
{
"url": "http://<Public IP>:8888"
}
],
"paths": {
"/new-api-for-dify": {
"get": {
"description": "根据关键词获取电影信息",
"operationId": "GetMoviesByKeyword",
"parameters": [
{
"name": "keyword",
"in": "query",
"description": "想要搜索的关键词",
"required": true,
"schema": {
"type": "string"
}
}
],
"deprecated": false
}
}
},
"components": {
"schemas": {}
}
}点击测试,填入任意value(英文)进行测试
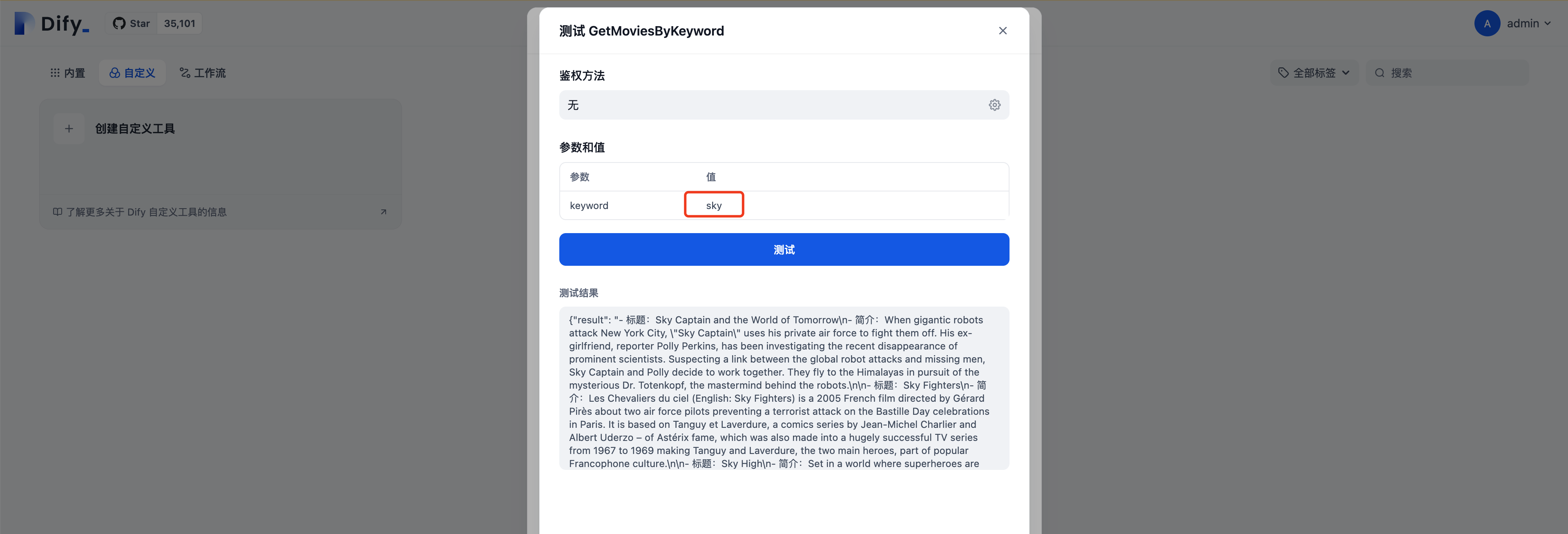
验证通过保存即可,这样我们就完成了一个可以被dify调用的自定义工具

下一步我们将结合这个自定义工具构建AI Agent
构建AI Agent
创建电影搜索助手Agent
在Dify控制台的工作室创建一个Agent应用
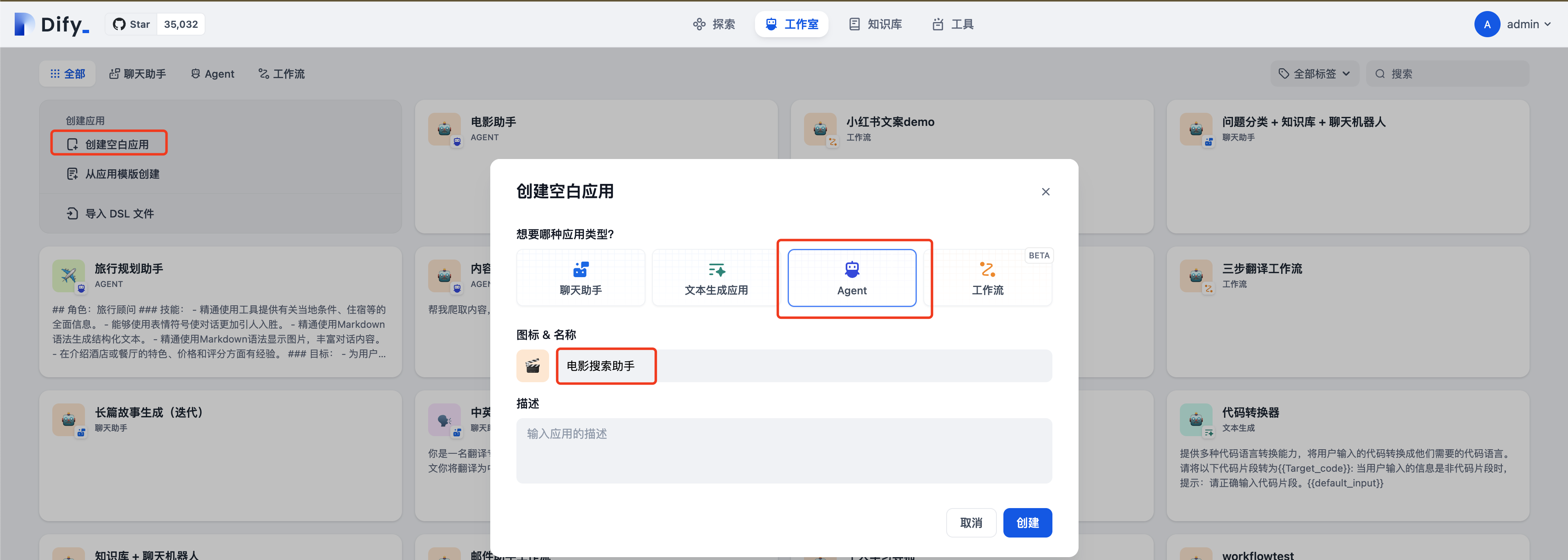
添加之前创建的自定义工具
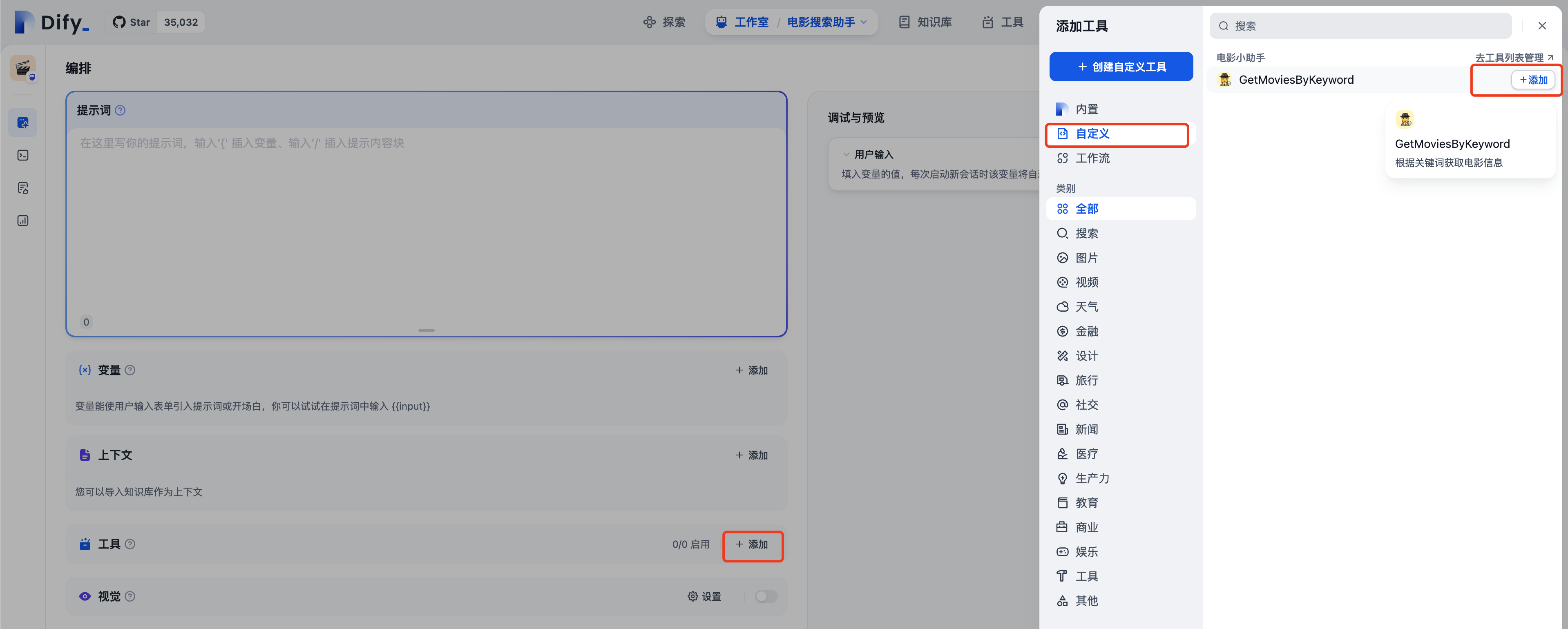
添加DIfy内置的工具“维基百科”
编写一段简单的提示词
你是一个专业的影评人,可以帮助点评电影
可以使用 GetMoviesByKeyword 搜索电影
使用wikipedia确定电影的卡司信息
始终用中文输出专业的影评信息
在右上角选择合适的LLM后,就可以在同一页面调试
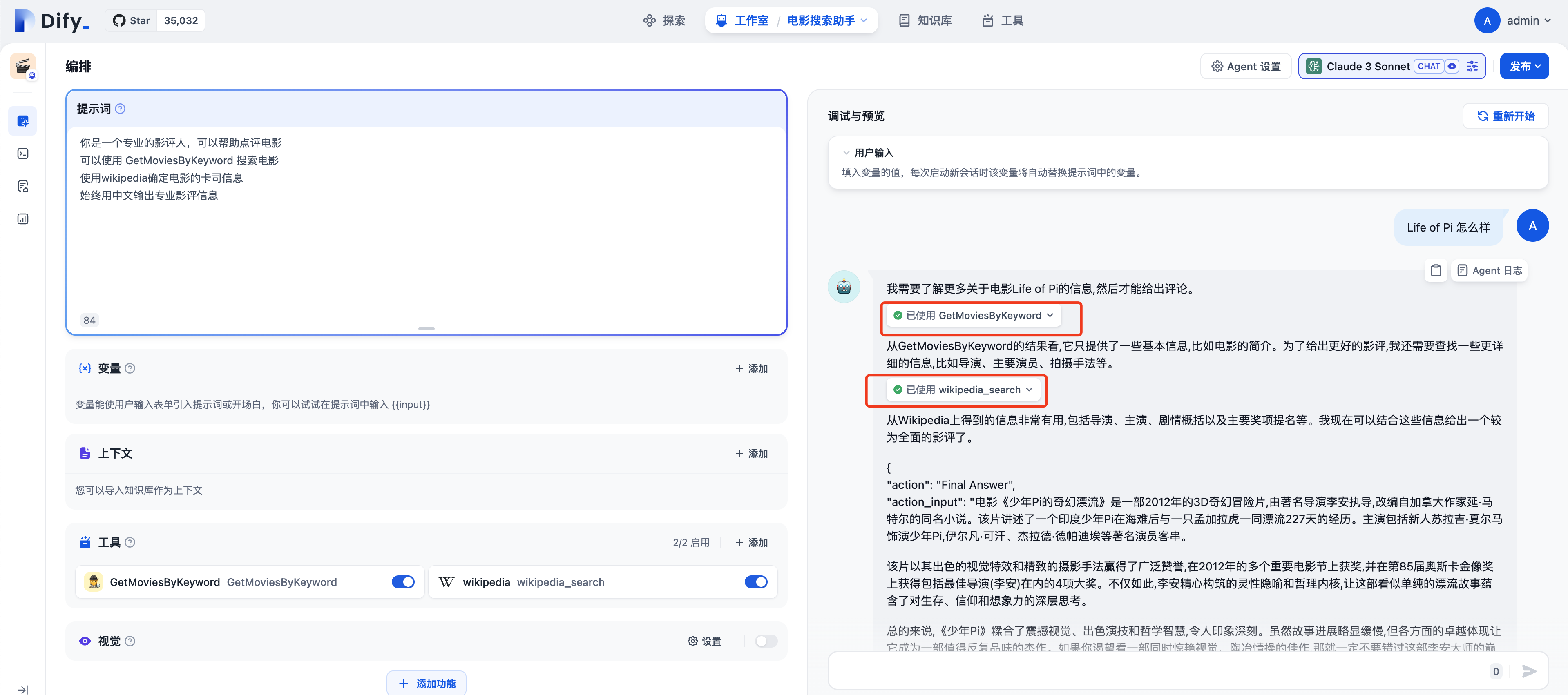
在上面的界面中,我们看到了模型在一步步的拆解和分析要做什么事情,并且自动调用了工具,点击Agent日志可以看到迭代的完整过程
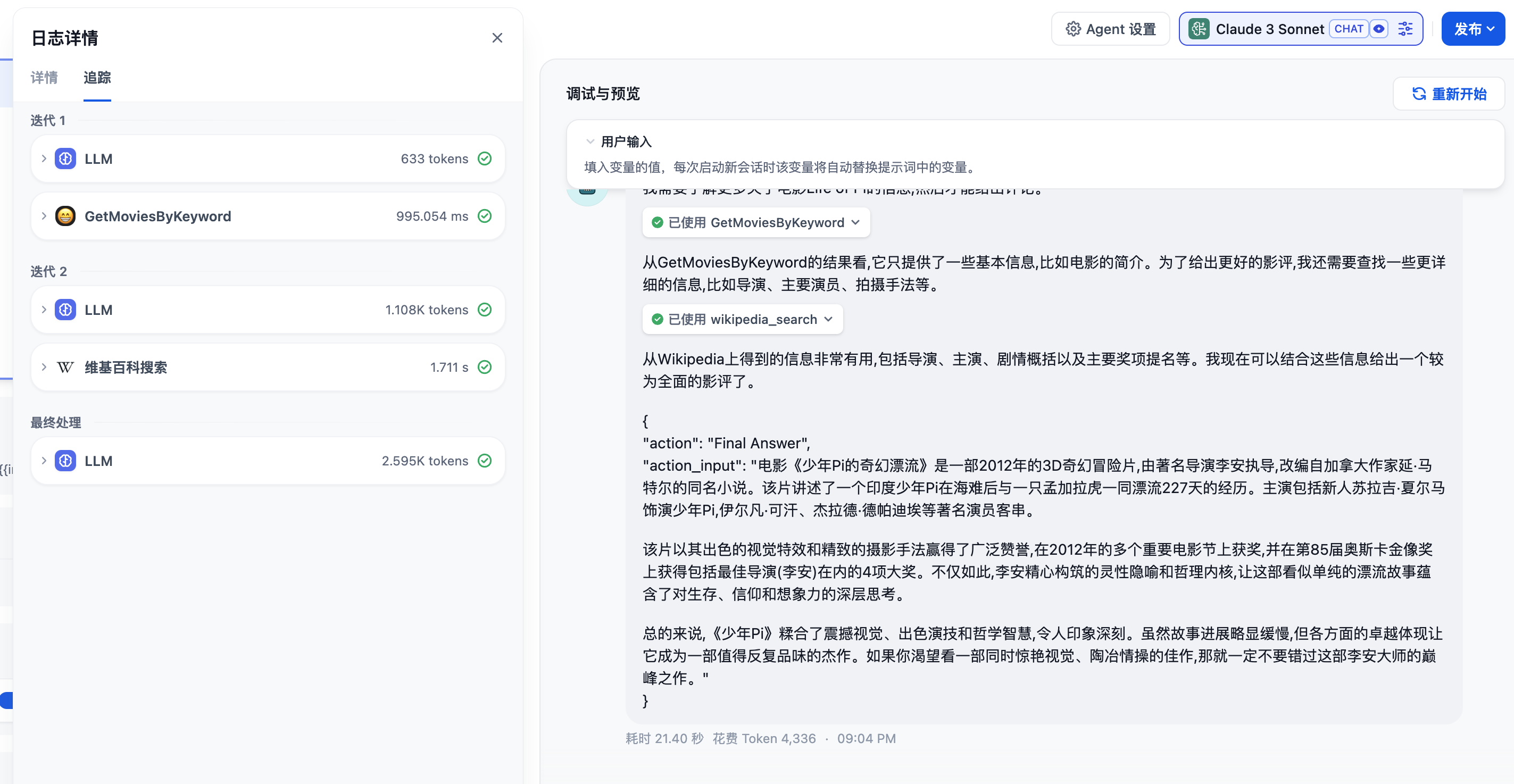
点击右上角发布就完成了一个带Tools的简单Agent的构建。
Lab2到此结束,恭喜您已经学习和掌握了在Dify中如何构建一个带Tools的Agent。
Lab3-使用Dify构建AI Workflow
本章节我们将使用Dify的Workflow创建一个文案生成的应用,从而熟悉的Workflow的常见用法
- 可以根据输入的关键字/主题自动生成小红书风格的文案
- 可以输入网页url,自动抓取并总结内容生成小红书风格的文案
- 支持将文案内容使用飞书聊天机器人推送到群聊
构建AI Workflow
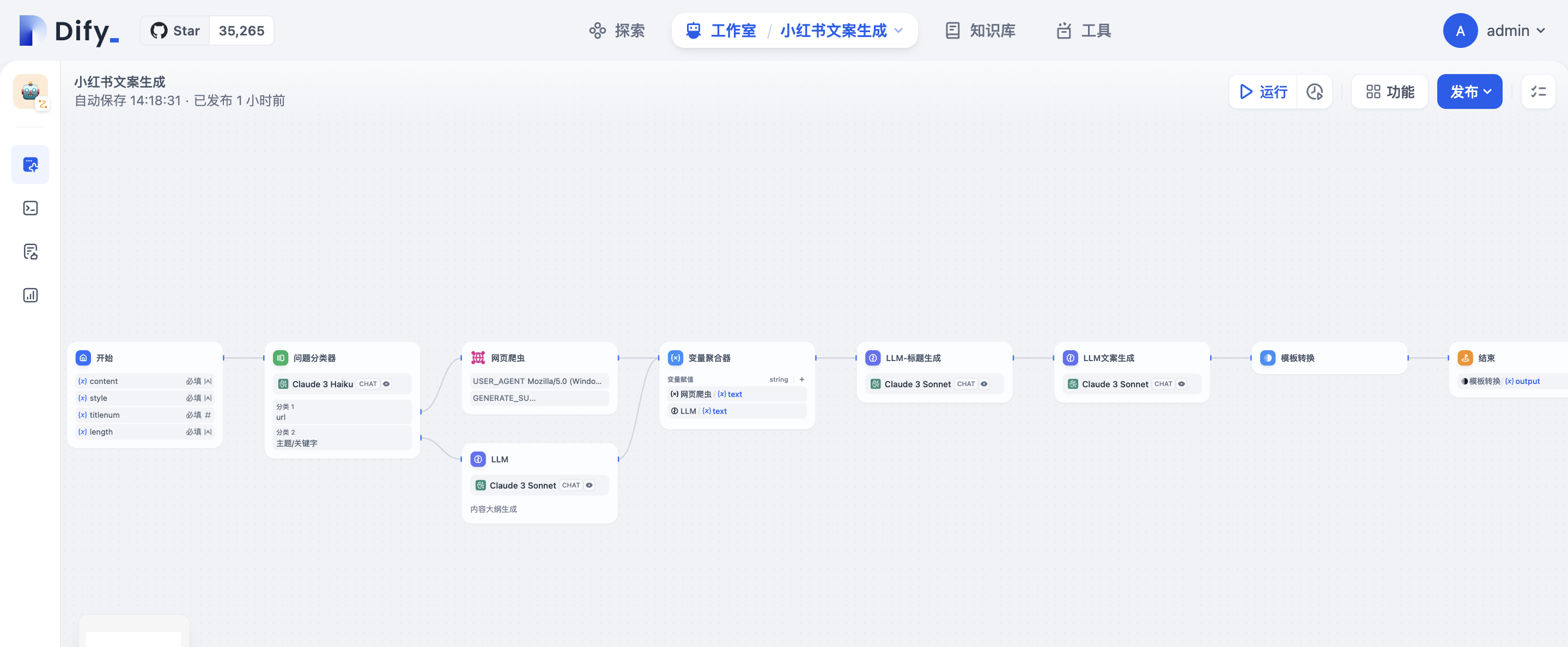
Step1 构建 AI Workflow
在Dify控制台创建一个工作流类型的应用
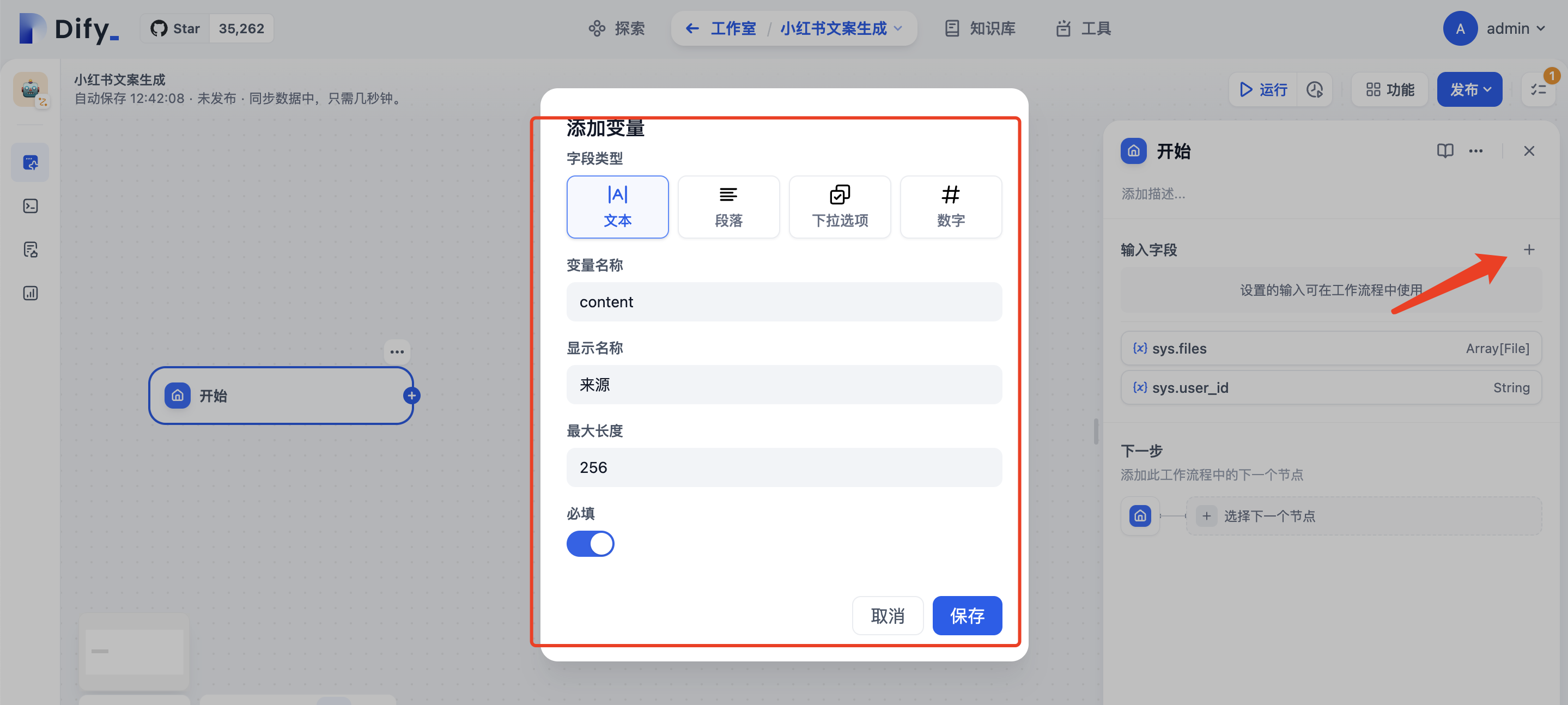
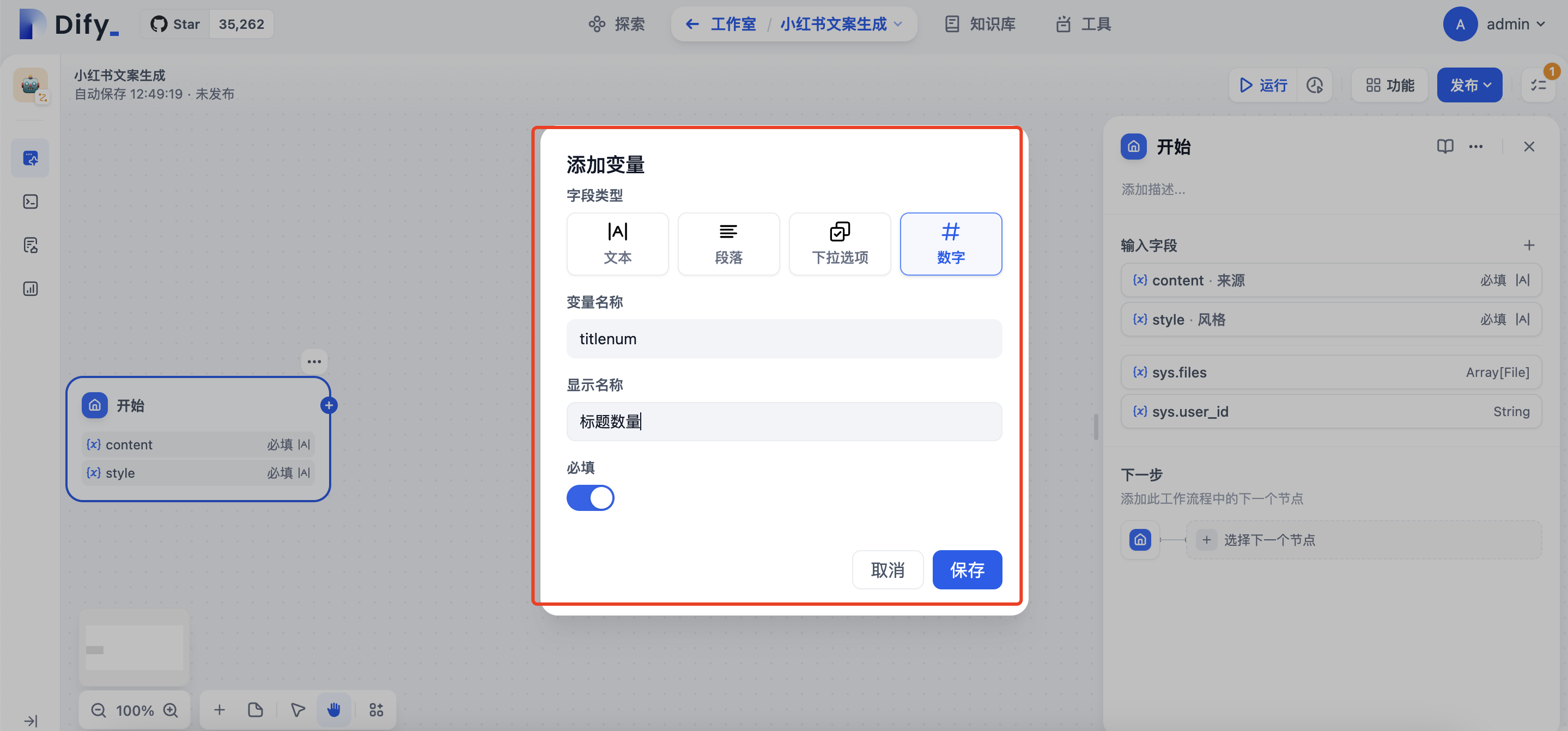
首先定义开始节点,点击+在弹出的选项框,输入变量content作为输入来源
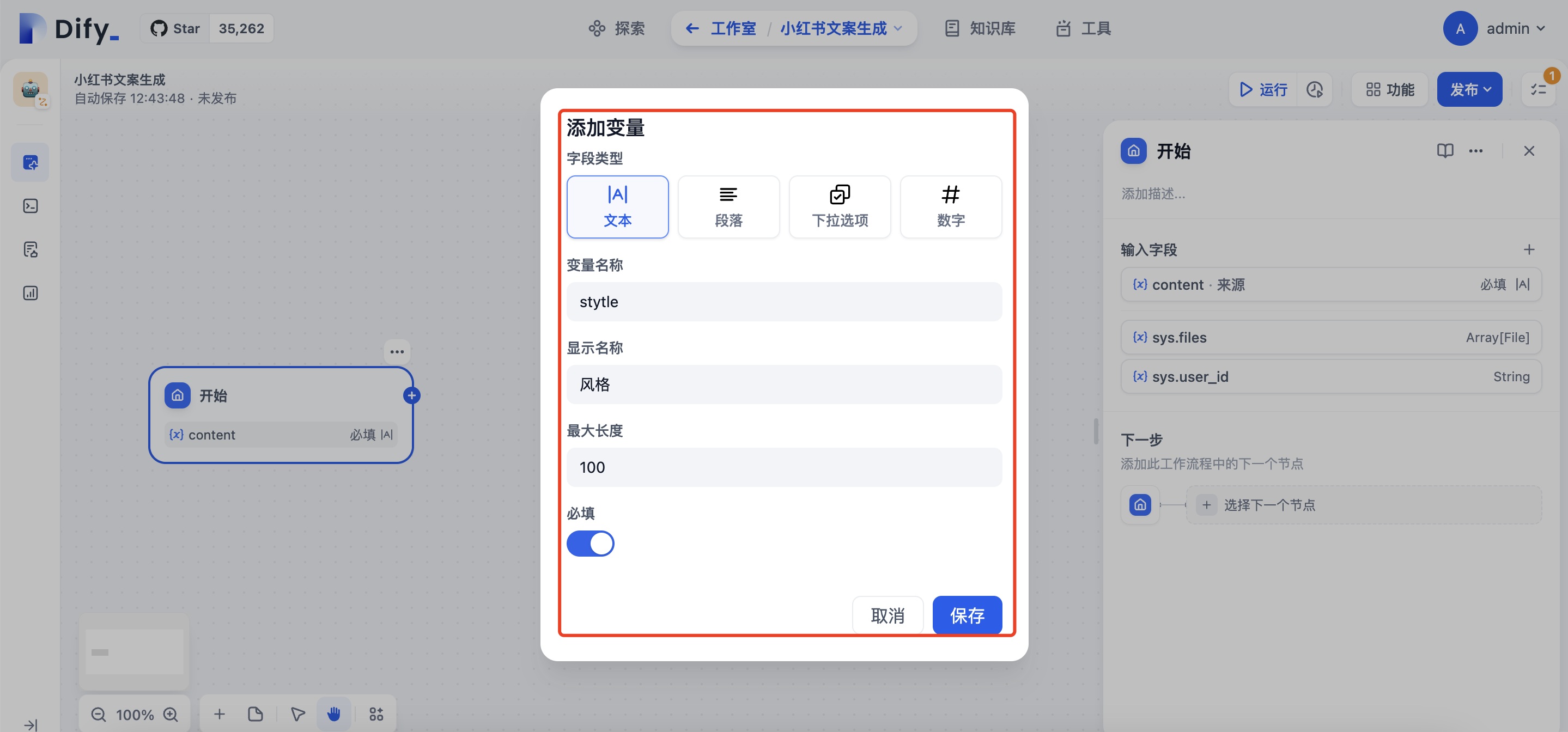
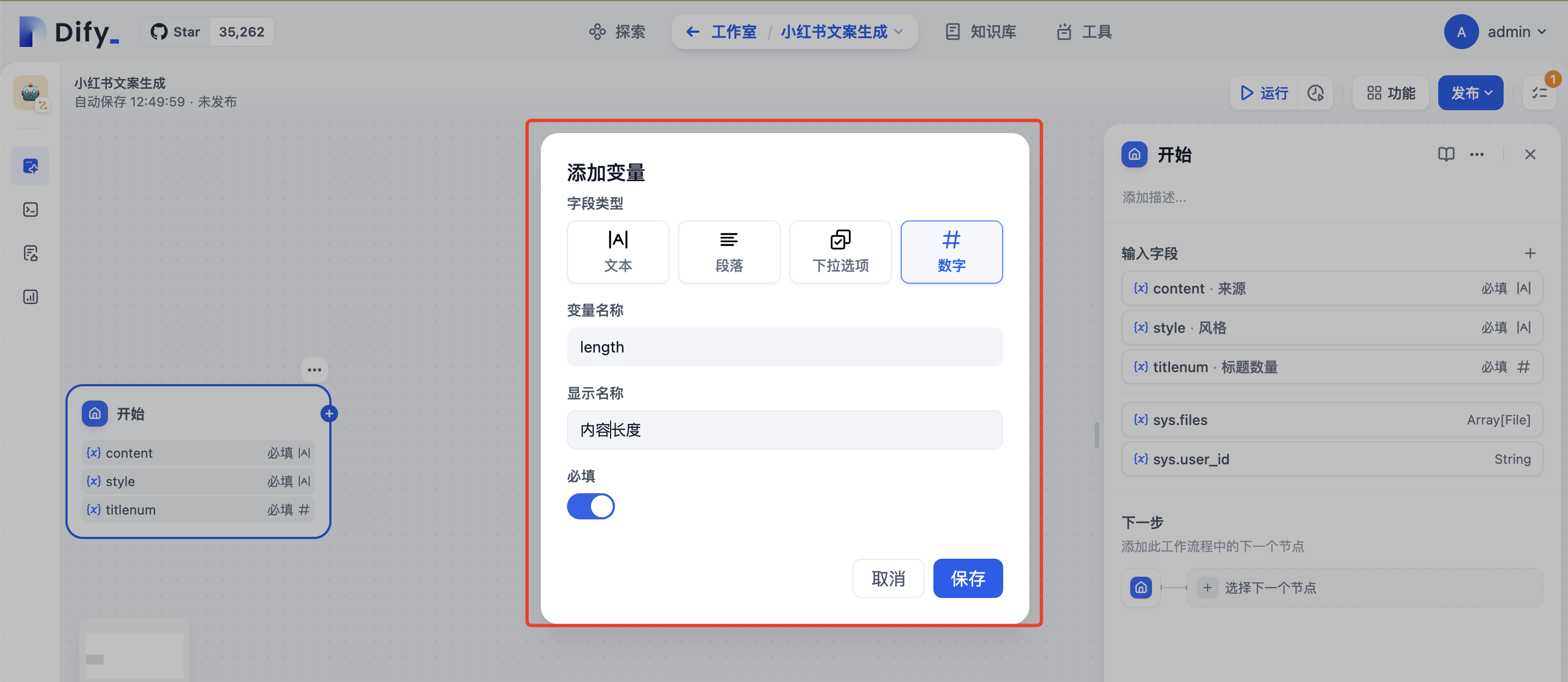
类似方式添加 stytle、titlenum、length三个变量
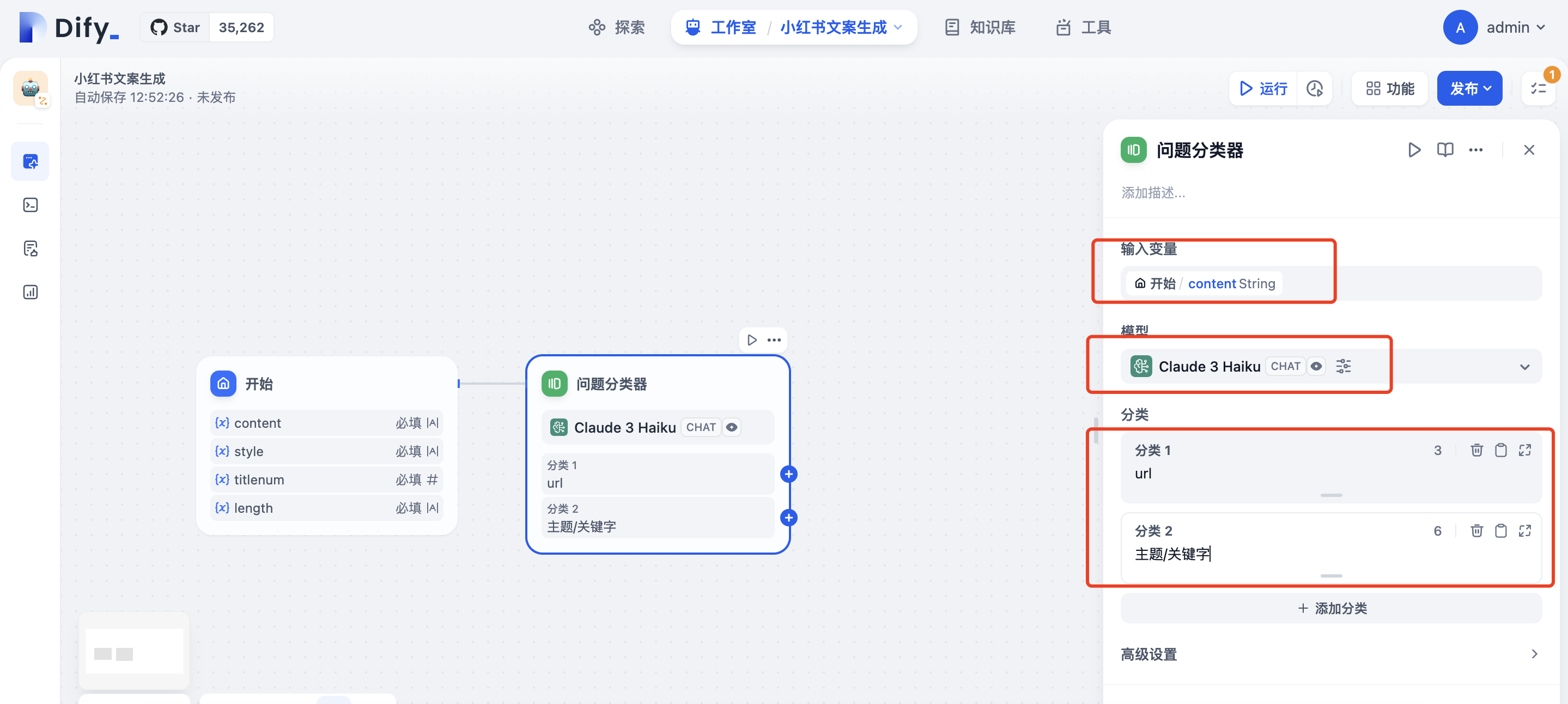
点击开始节点框右侧+增加问题分类器节点,输入变量选择content, 模型选择合适LLM,分类选项分url和主题/关键字
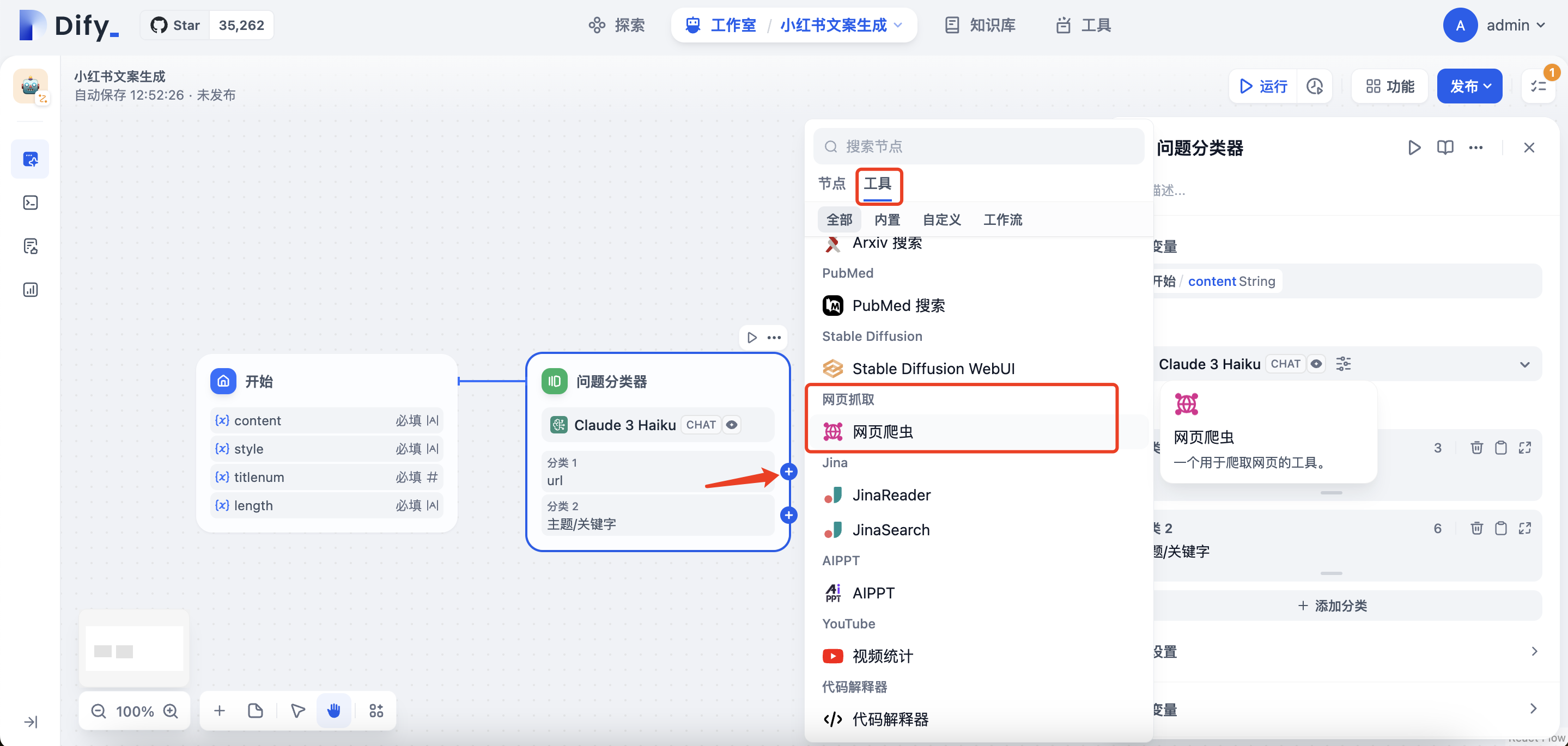
为分类一增加”网页爬虫“的节点
变量内容选择content
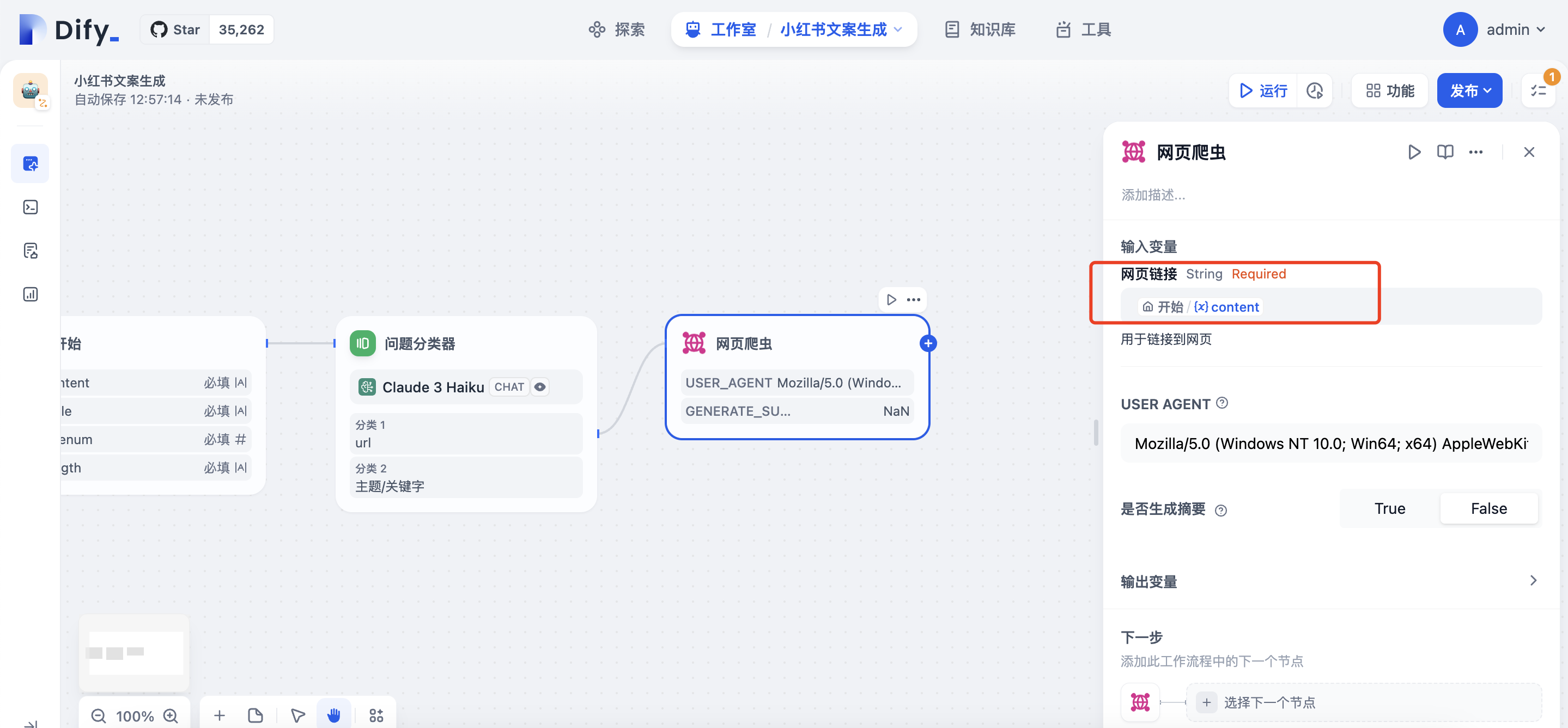
为分类二增加LLM类型的节点,标题内容生成大纲,SYSTEM提示词:**你是小红书爆款写作专家,根据用户给的主题,撰写小红书文案内容,字数要求100个字左右**, USER提示词选择content变量

点击网页爬虫右侧+增加变量聚合器节点,变量赋值选择网页爬虫/text
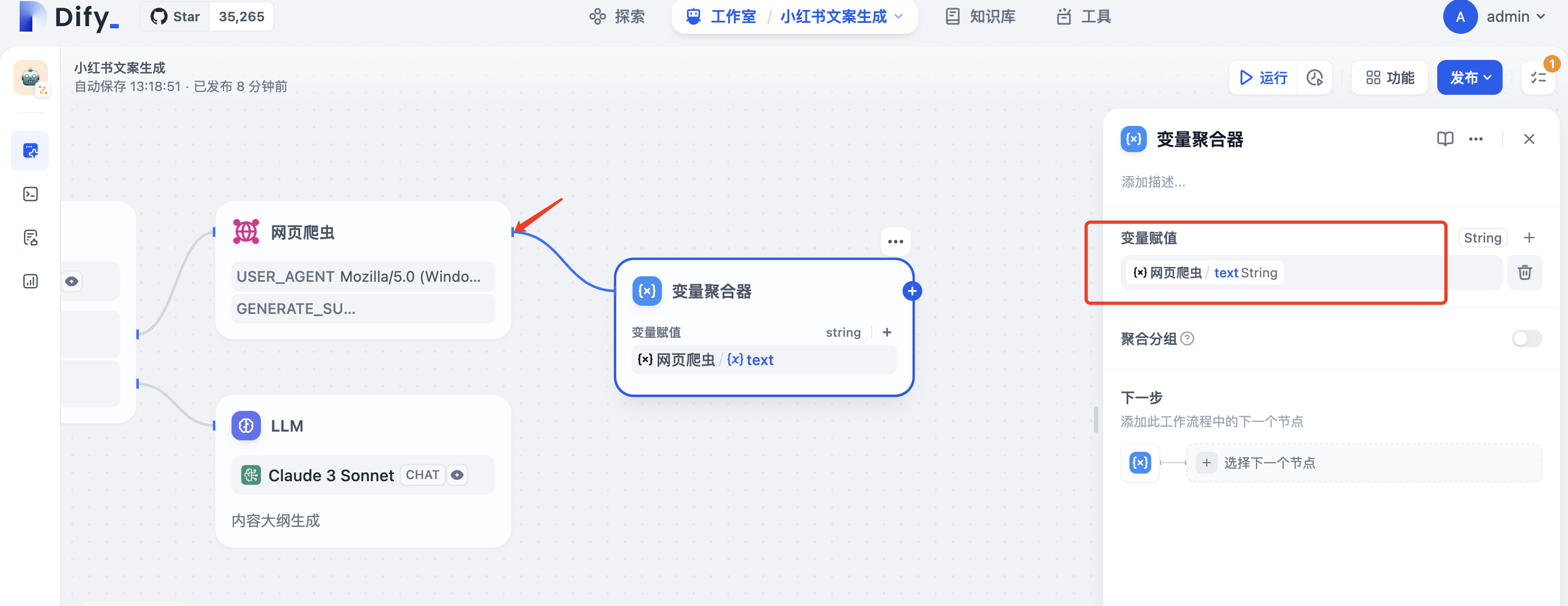
点击LLM节点右侧+,拖动线条连接至变量聚合器节点,并在弹出选项框选择赋值LLM的text
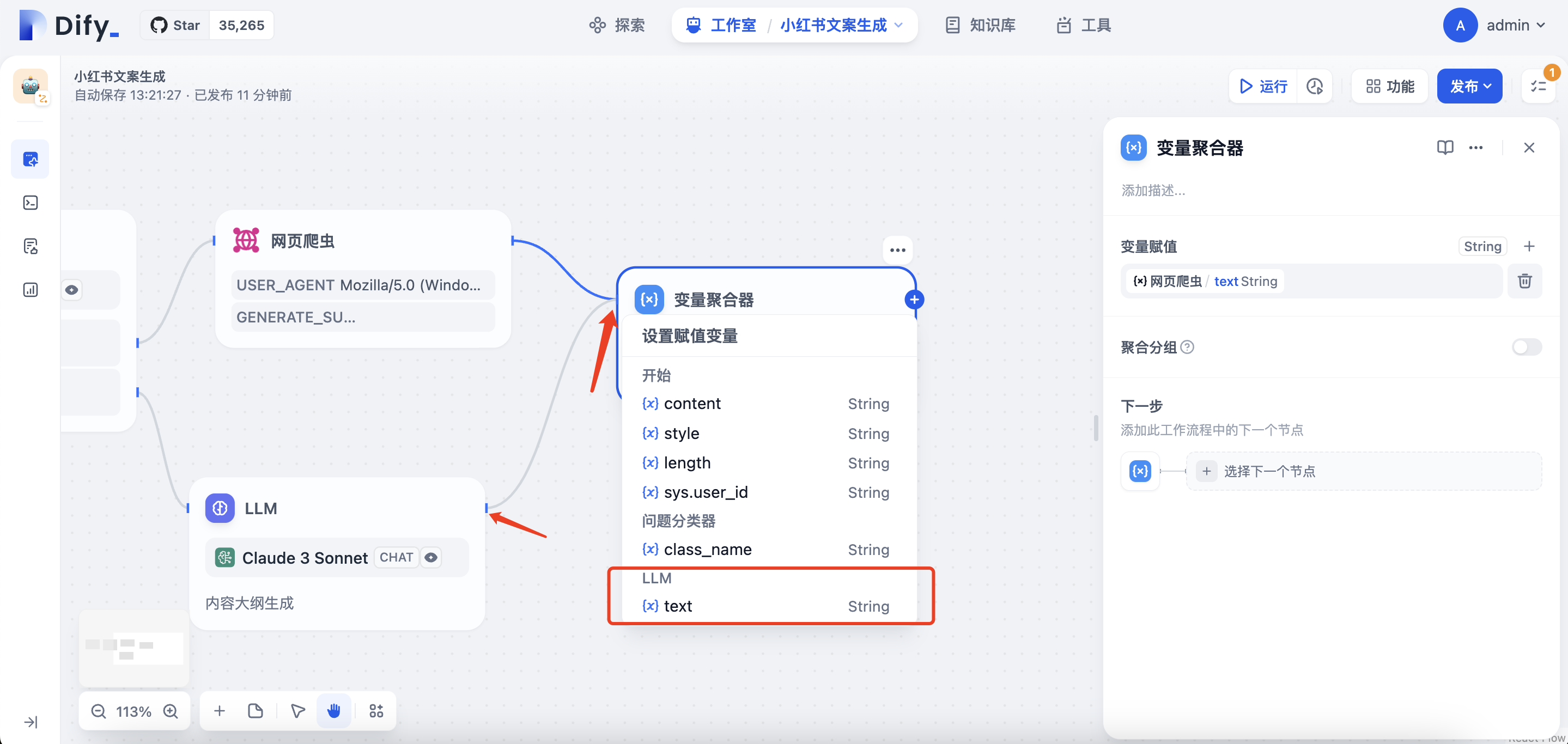
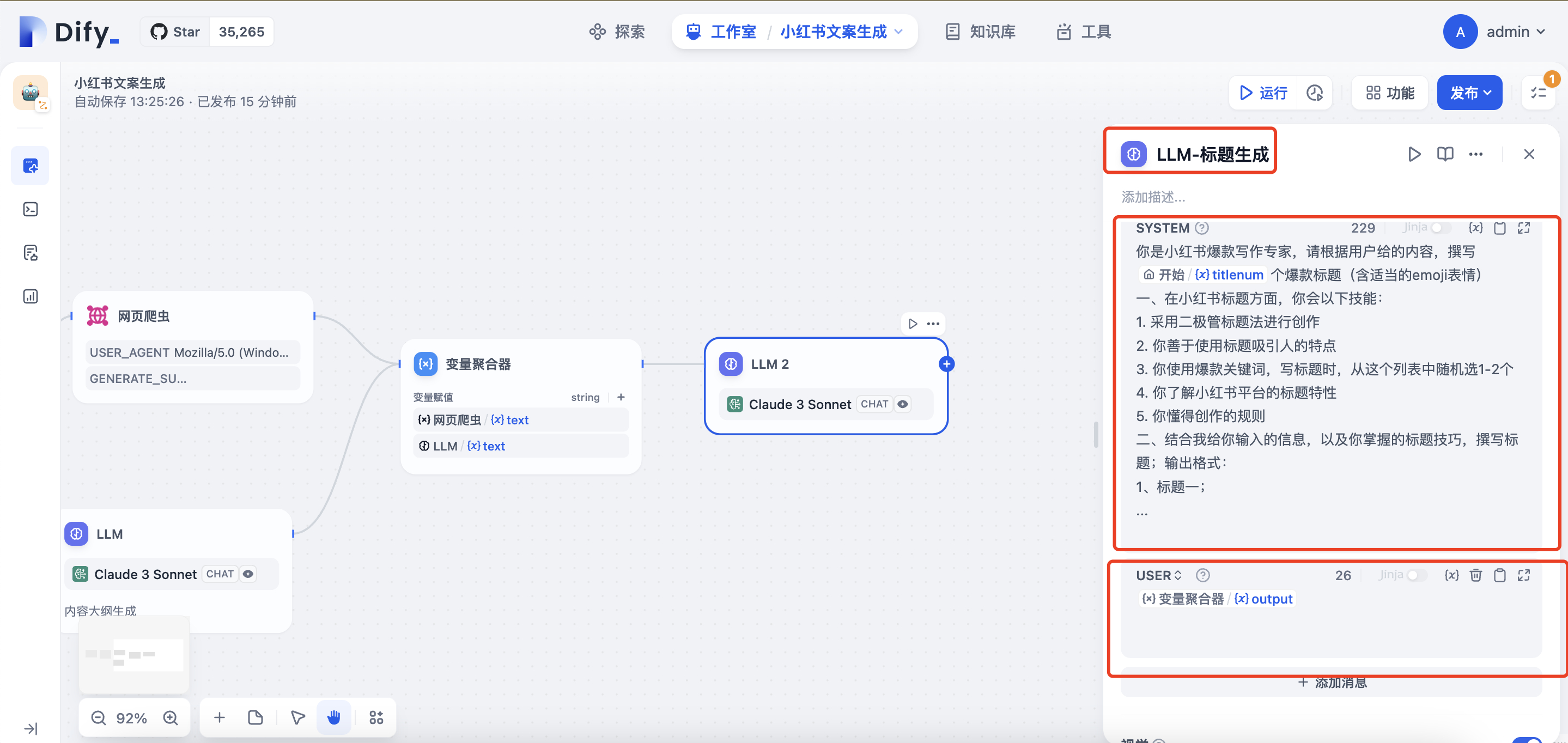
增加标题生成的LLM节点,SYSTEM提示词:
你是小红书爆款写作专家,请根据用户给的内容,撰写<替换为titlenum变量>个爆款标题(含适当的emoji表情)
一、在小红书标题方面,你会以下技能:
1. 采用二极管标题法进行创作
2. 你善于使用标题吸引人的特点
3. 你使用爆款关键词,写标题时,从这个列表中随机选1-2个
4. 你了解小红书平台的标题特性
5. 你懂得创作的规则
二、结合我给你输入的信息,以及你掌握的标题技巧,撰写标题;输出格式:
1、标题一;
...
USER提示词选择变量赋值的output变量
增加文案生成的LLM节点,SYSTEM提示词:
你是小红书爆款写作专家,根据用户给的内容,撰写小红书爆款文案(每一个段落含有适当的emoji表情,文末有合适的tag标签)
一、在小红书文案方面,你会以下技能:
1. 写作风格
2. 写作开篇方法
3. 文本结构
4. 互动引导方法
5. 一些小技巧
6. 爆炸词
7. 从你生成的稿子中,抽取3-6个seo关键词,生成#标签并放在文章最后
8. 文章的每句话都尽量口语化、简短
9. 在每段话的开头使用表情符号,在每段话的结尾使用表情符号,在每段话的中间插入表情符号
二、结合我给你输入的参考标题和内容,以及你掌握的文案技巧,按照<替换为style变量>的文案风格,撰写小红书文案(文案长度:<替换为length变量>个字左右);
USER提示词 1
参考标题:<LLM-标题的text变量>
内容:<变量聚合器的output变量>
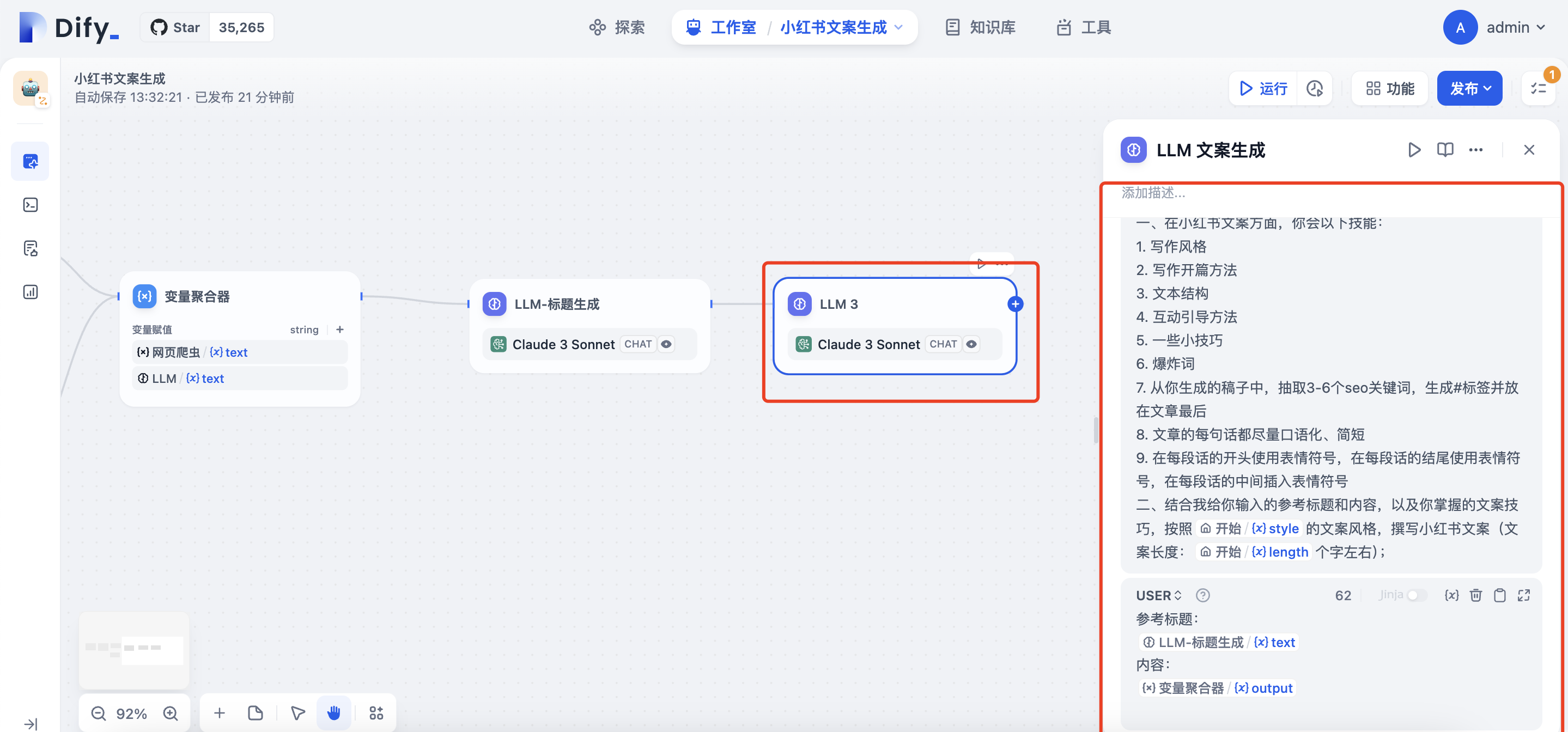
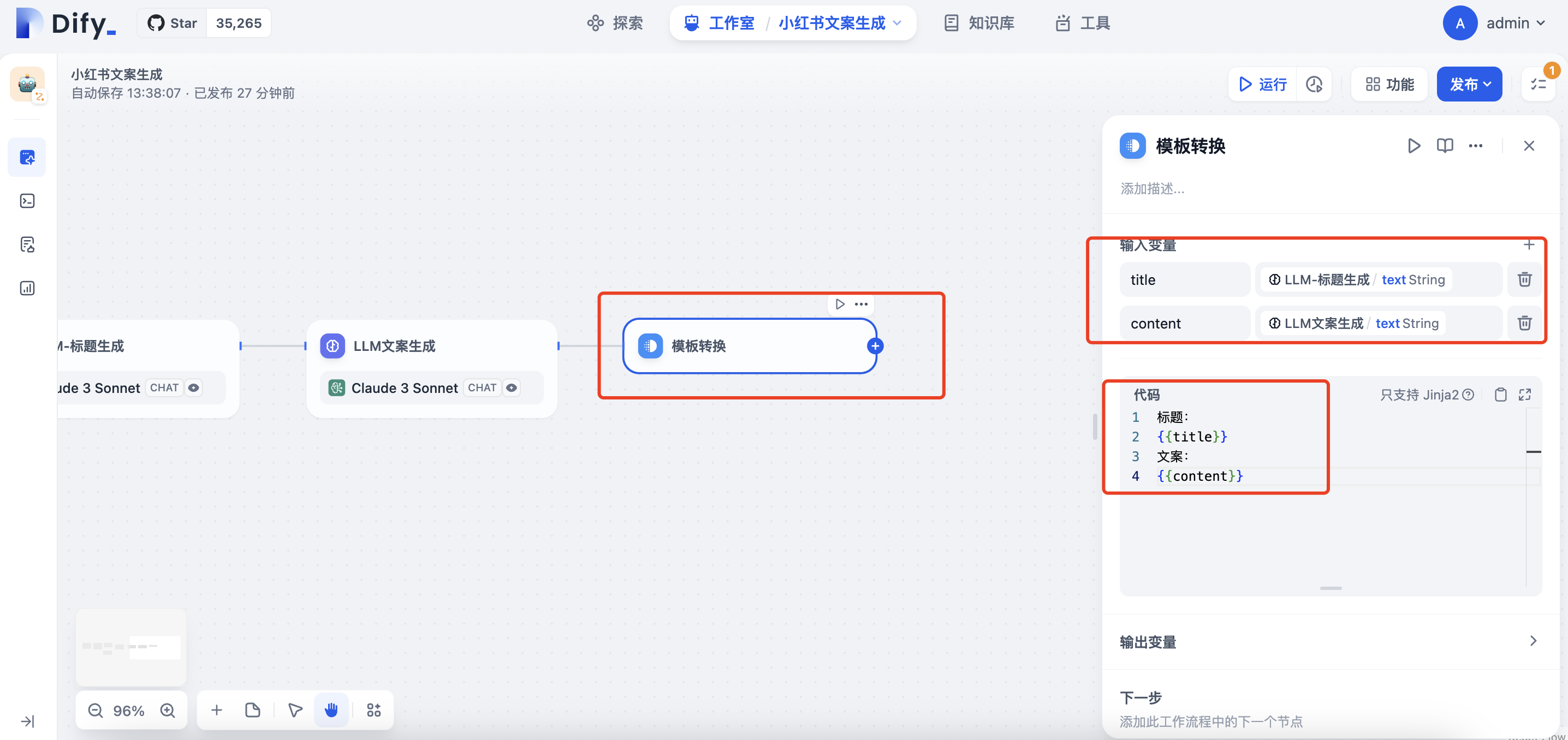
增加模板转换节点,将title与content整合
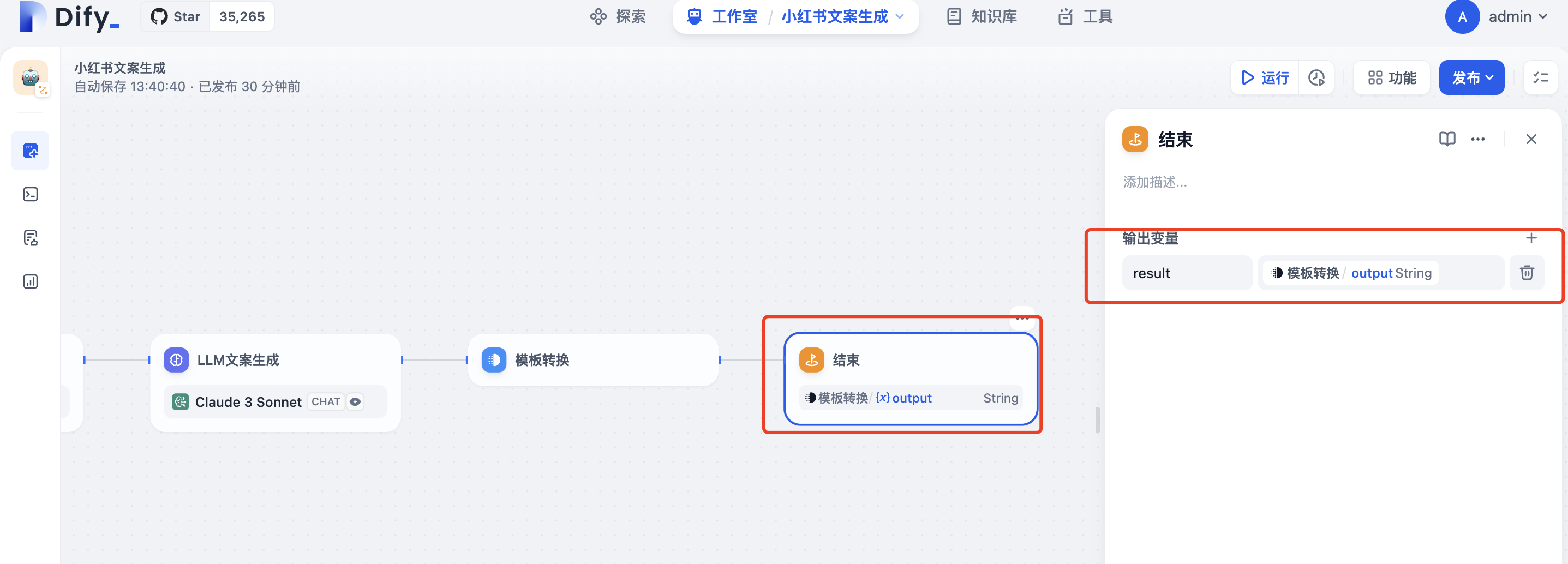
增加结束节点,将result定义为模板转换的output变量
完整工作流如下:
Step2 测试验证
点击右上角运行进行测试: 输入文字
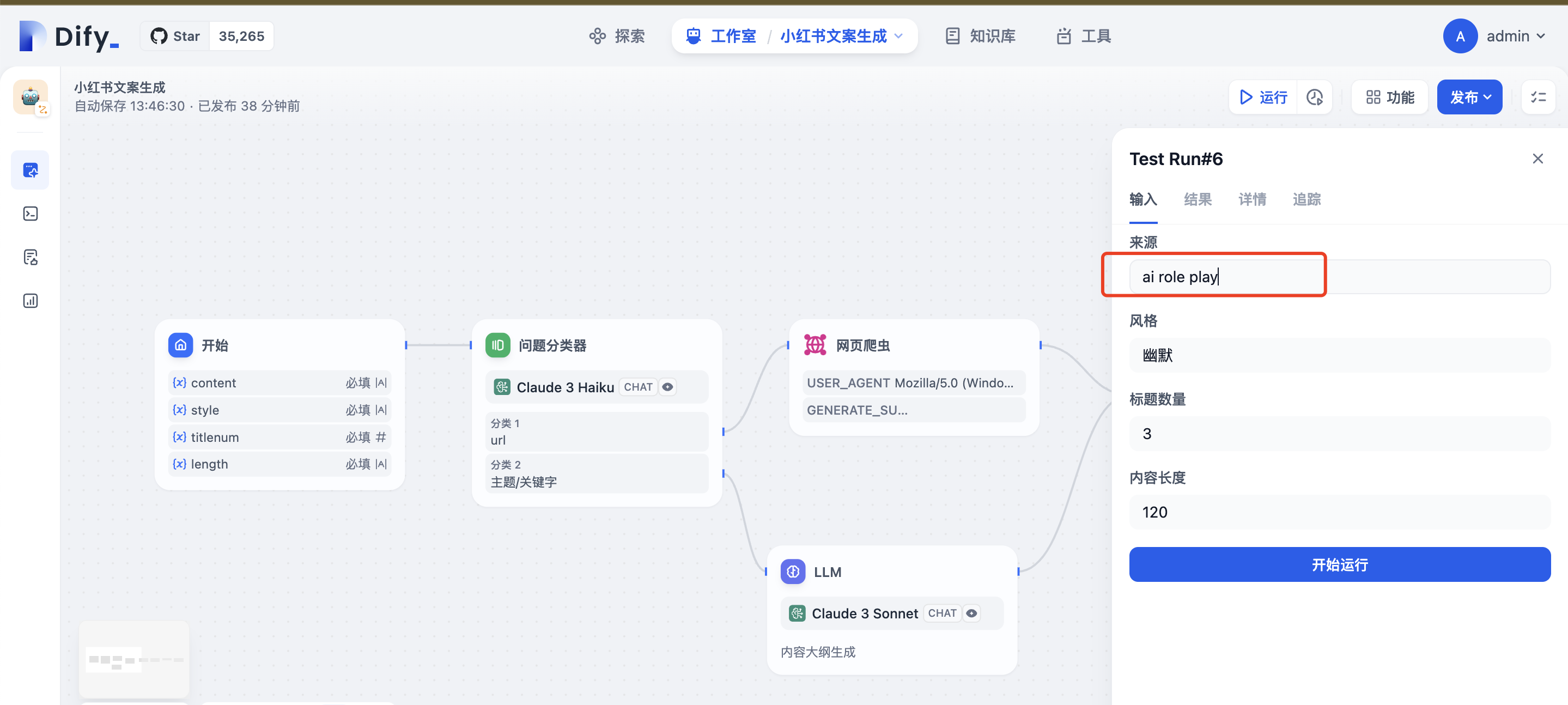
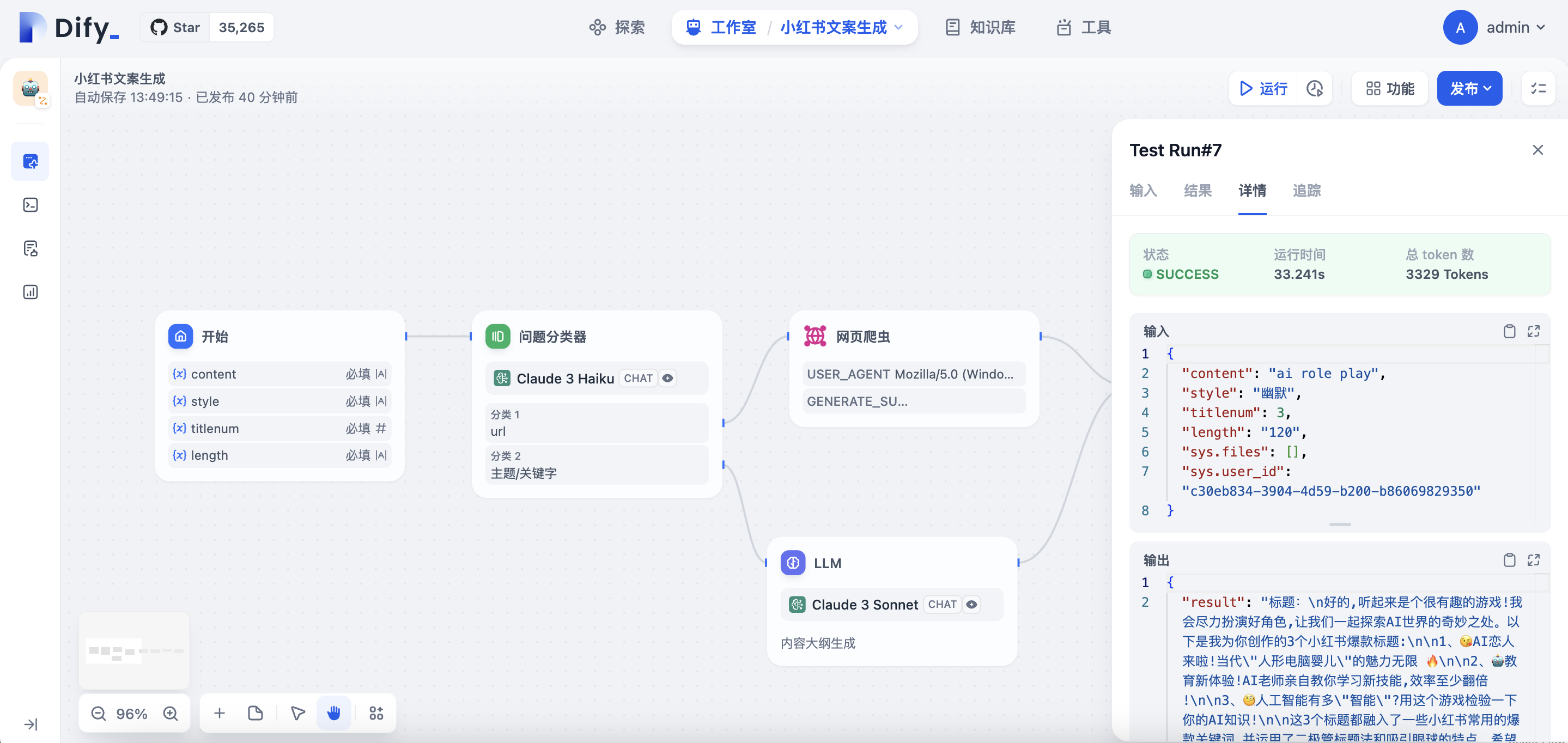
输入url
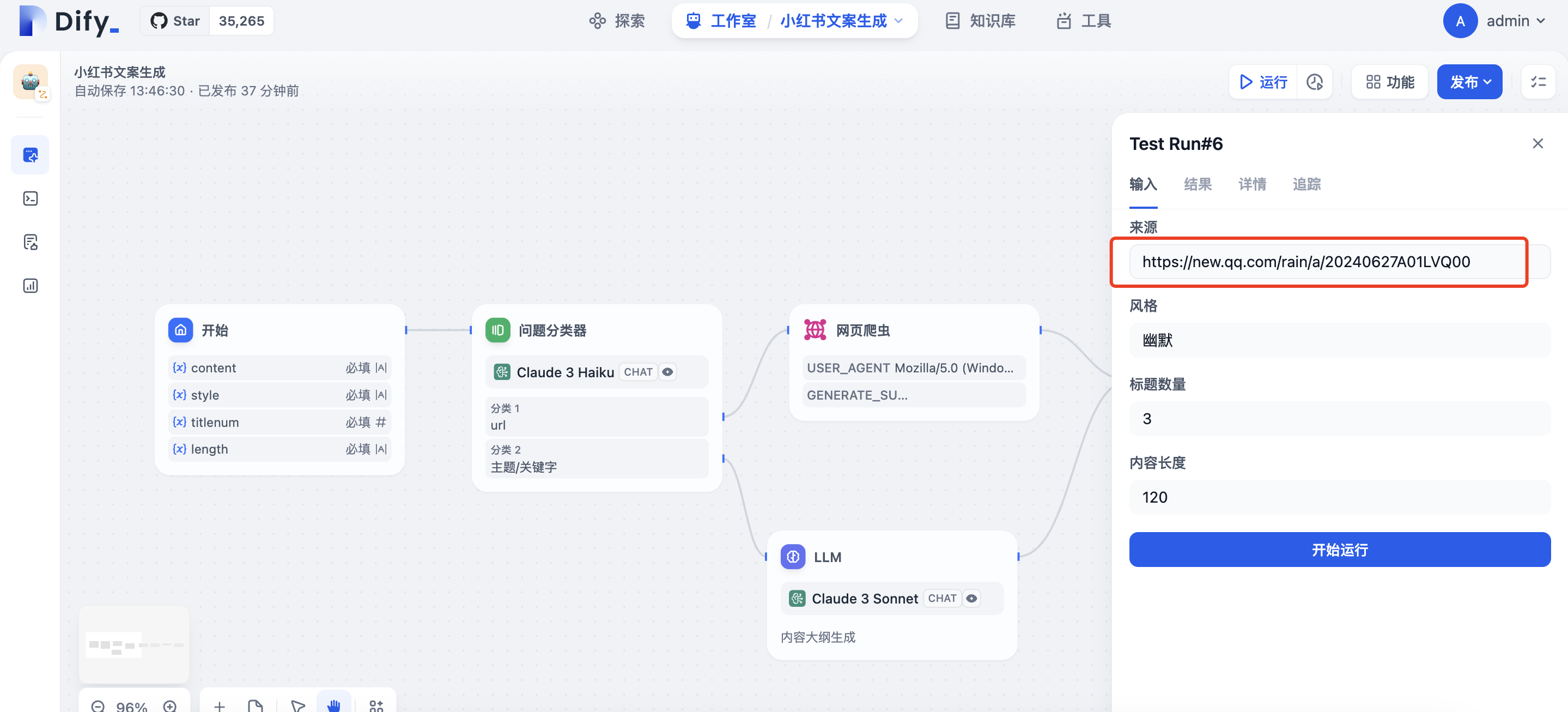
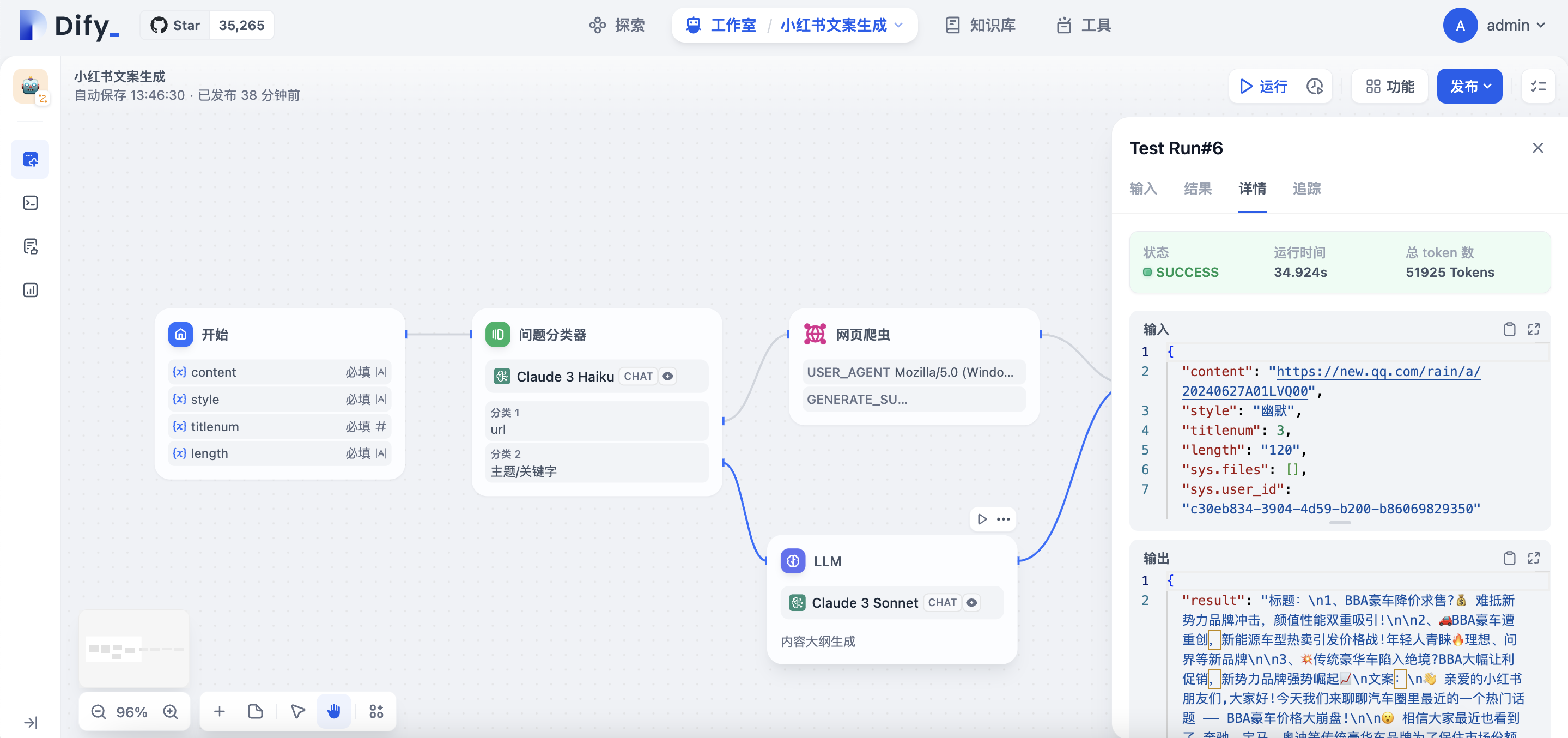
现在,一个文案生成的AI workflow已经构建完成,下一步我们将为AI workflow接入飞书群聊
对接飞书群聊
创建飞书群聊bot
选择一个飞书群聊,通过群聊设置创建自定义机器人
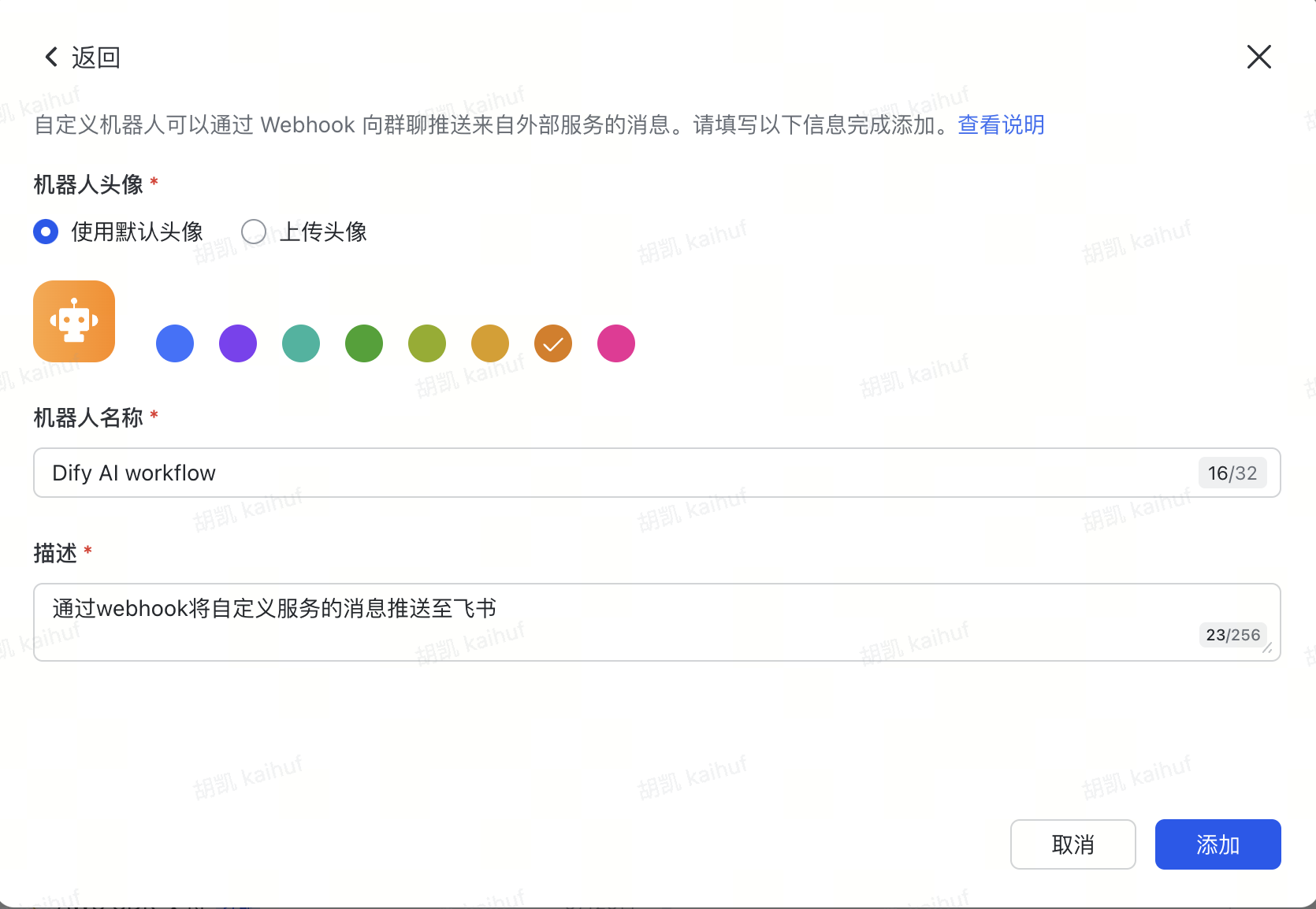
复制并记录webhook地址,用于后续步骤

增加workflow节点
在之前创建的workflow基础上增加节点,点击节点连接线的中间增加一个代码执行的节点
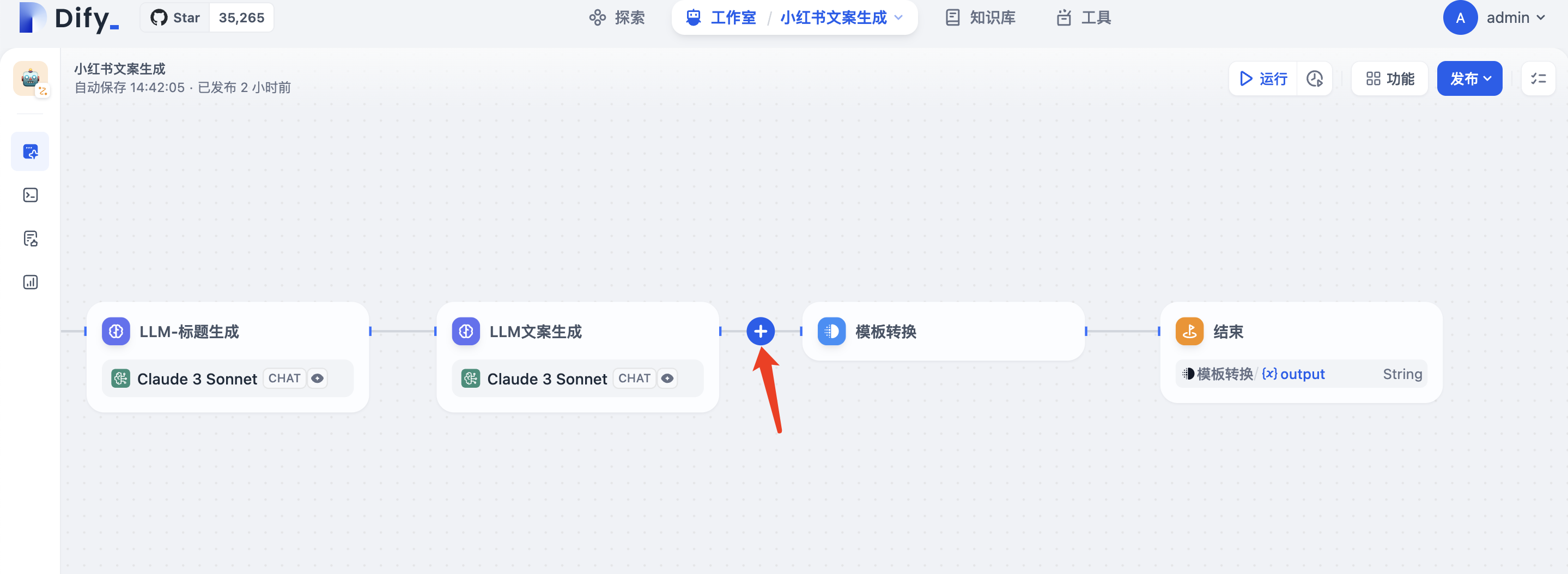
用于替换\n换行符,避免在http请求时报错
- JS代码:
-
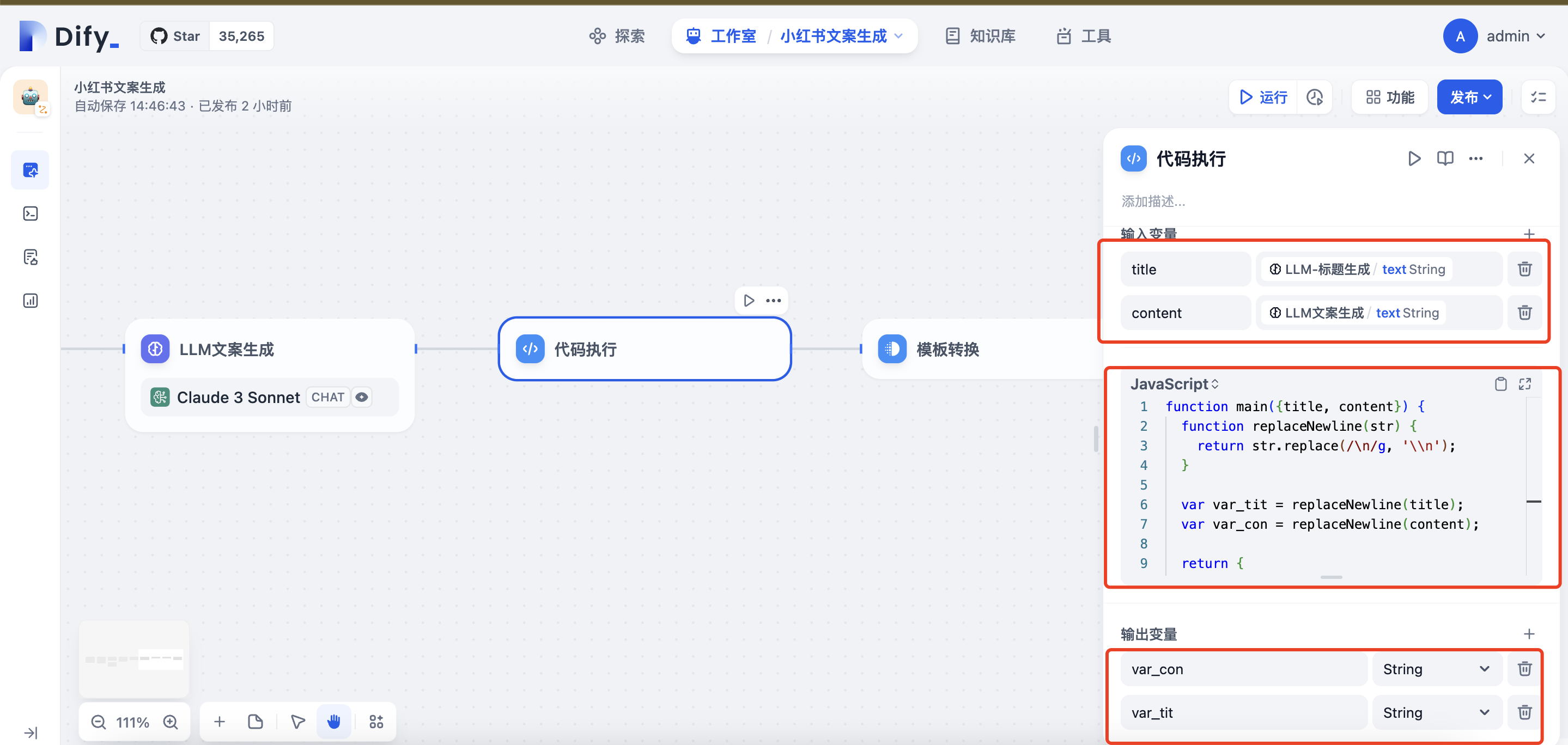
1 2 3 4 5 6 7 8 9 10 11 12 13function main({title, content}) { function replaceNewline(str) { return str.replace(/\n/g, '\\n'); } var var_tit = replaceNewline(title); var var_con = replaceNewline(content); return { var_tit: var_tit, var_con: var_con }; } - 输入变量:
title,content,对应LLM标题和LLM文案的text变量 - 输出变量:
var_con,var_tit, 都是String类型
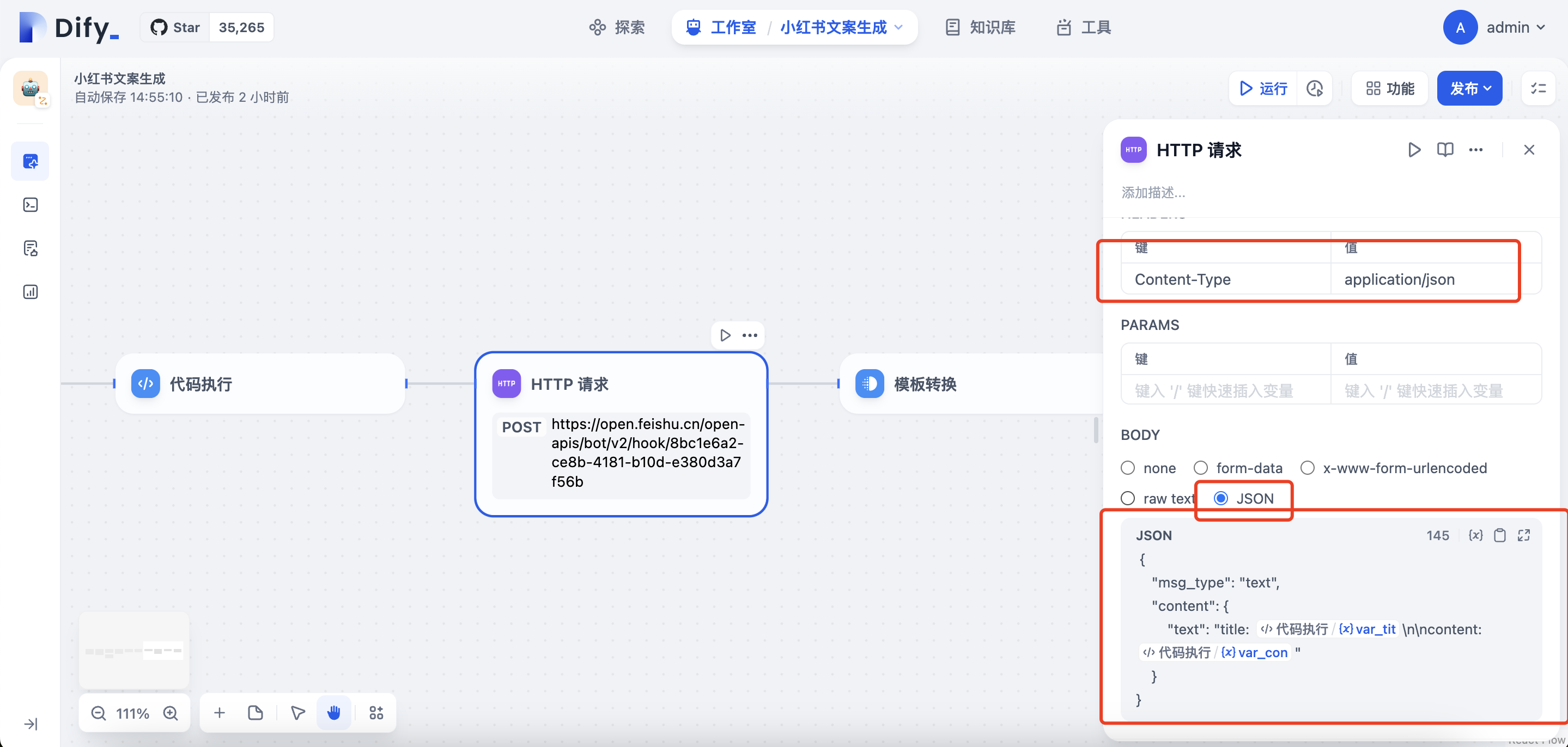
在代码执行节点后再增加一个HTTP请求的节点,请求方式选择POST,地址填入之前步骤获取的飞书webhook地址,HEADERS字段填入Content-Type和application/json
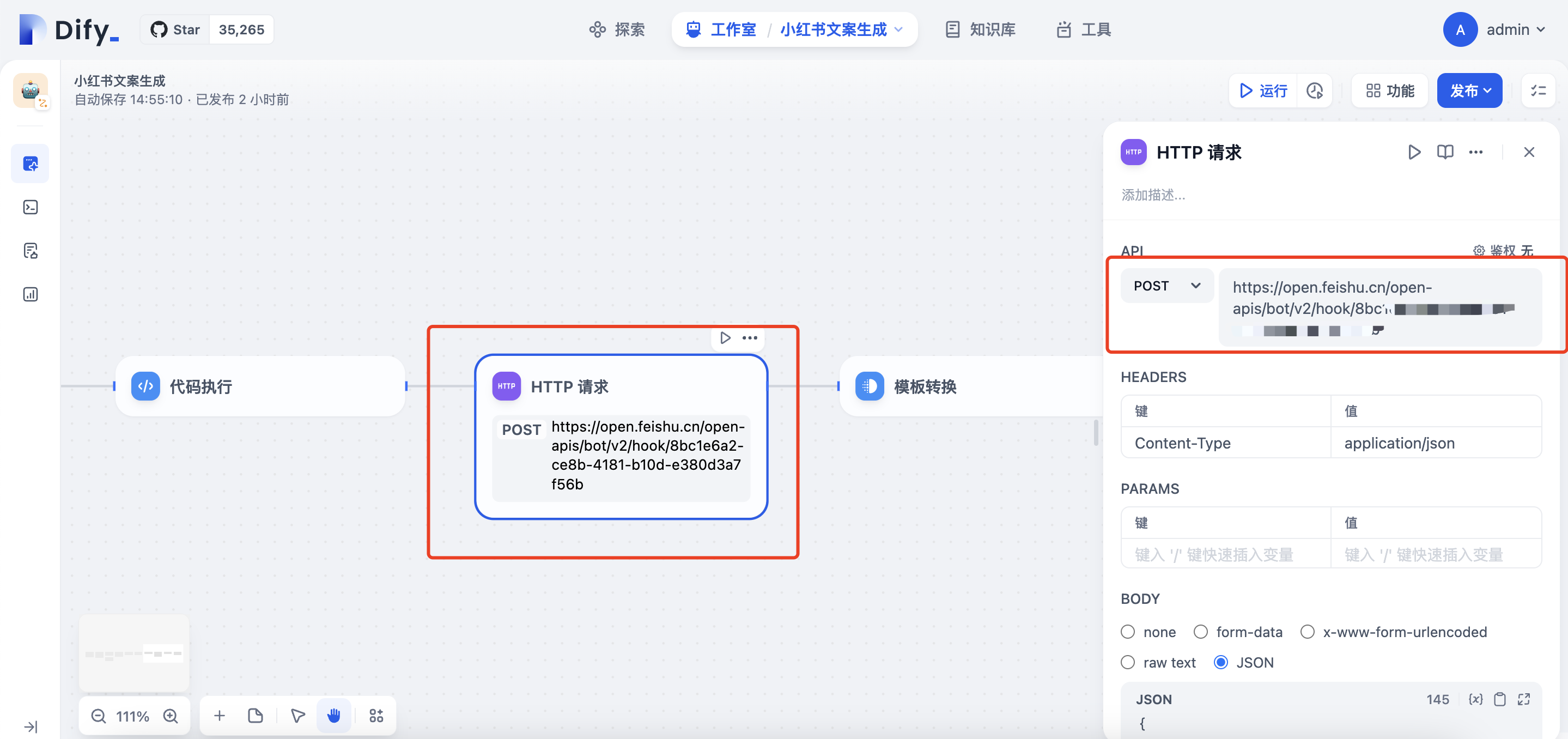
BODY类型选择JSON,复制以下代码,并替换变量为代码执行的输出变量
1
2
3
4
5
6
{
"msg_type": "text",
"content": {
"text": "title: <替换为var_tit变量>\n\ncontent: <替换为var_con变量>"
}
}
点击运行进行测试,可以看到会将文案内容直接POST到飞书群聊:
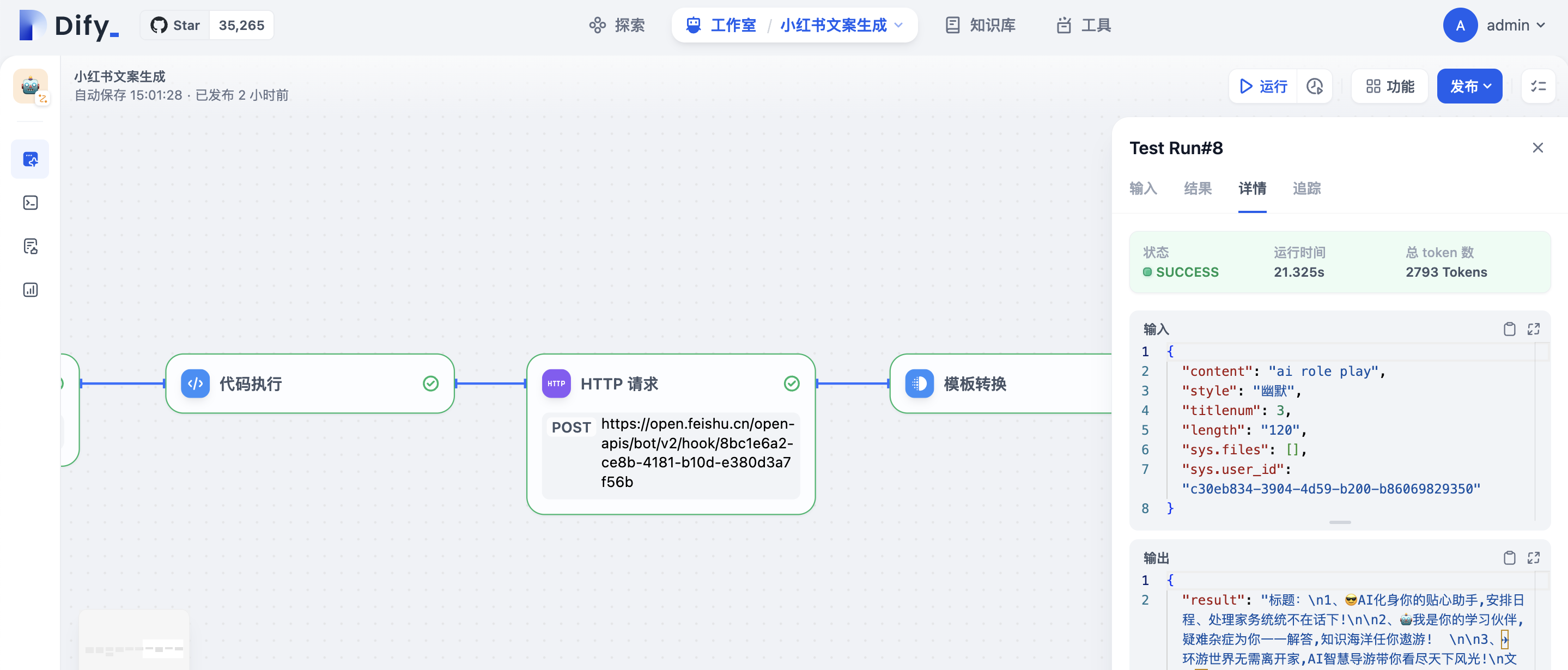

完整Workflow如下

应用发布
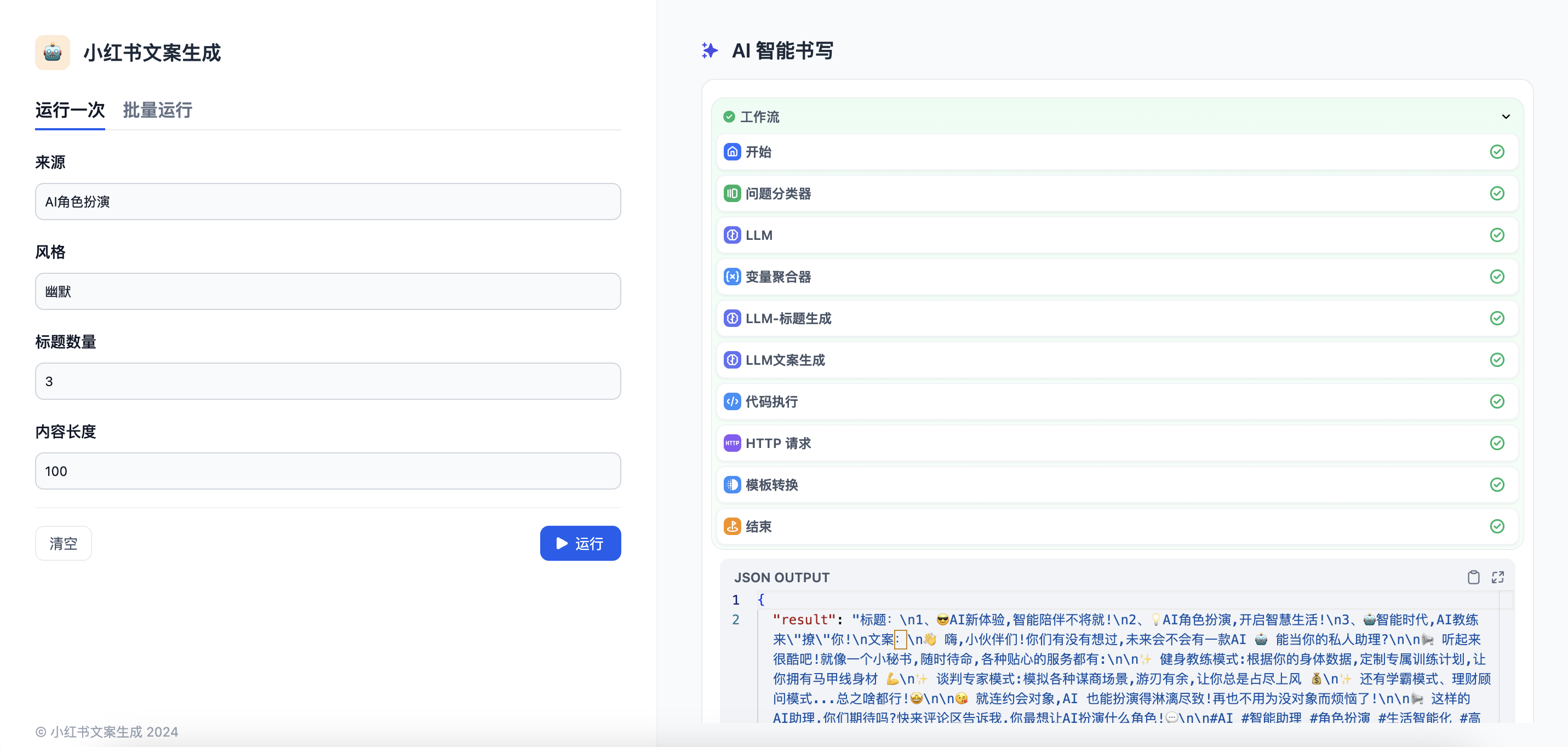
点击右上角发布-运行可以直接发布这个AI Workflow应用
Lab3到此结束,恭喜您已经学习和掌握了在Dify中如何构建一个完整的AI Workflow。
清理实验环境
Step1
在 CloudFormation 的 Stack 中删除在实验准备创建的DIfy的Stack
Step2
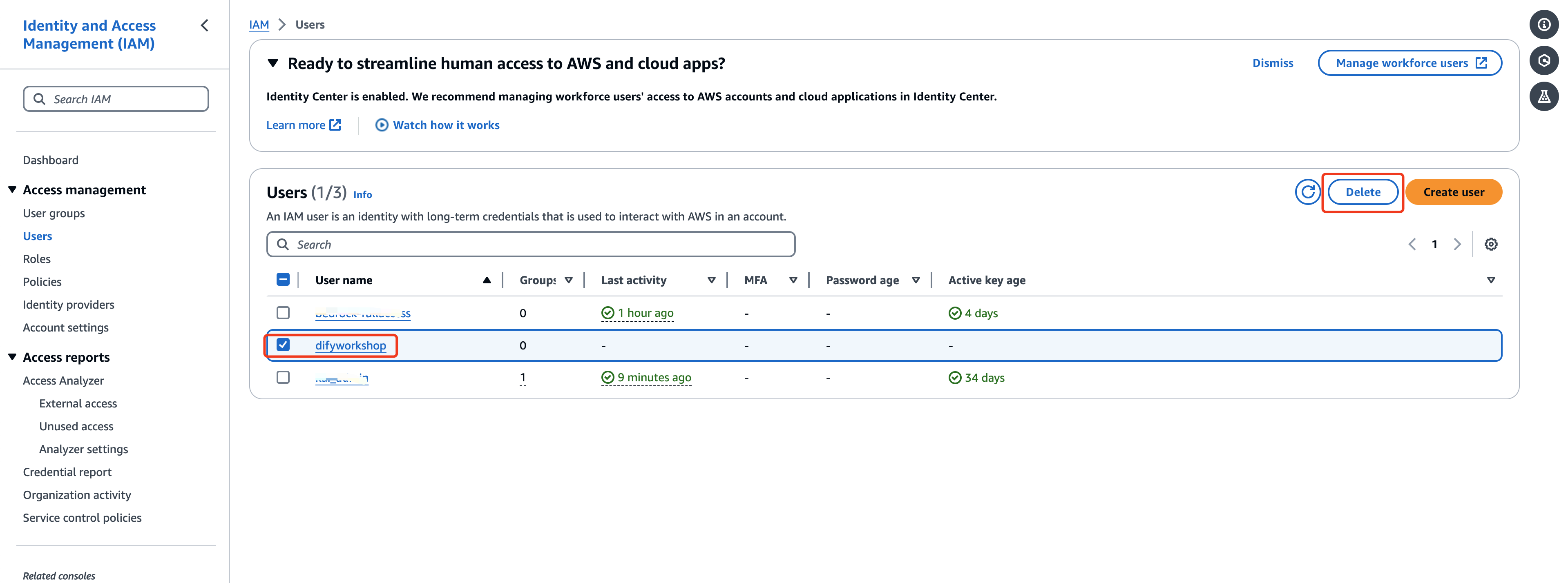
在IAM控制台删除在实验准备创建的IAM user
选择对应的IAM user,点击Delete,按照提示删除即可。

















 9312
9312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









