







零、前提
虽然是从大门外远远的看这些代码,还是要有一些前提条件的。
鄙人计算机是win10、64位系统,并且已经在计算机上安装/配置好的环境如下:anaconda3、tensorflow、python3.6、tensorboard
如果你还没有安装好环境,可以参考http://blog.csdn.net/yuhouji009/article/details/70856597
如下的代码主要是入门常用的训练识别手写数字,鄙人额外加上了自己的理解和一些其他代码。希望可以给各位带来些许帮助。
一、加载tensorflow
import tensorflow as tf
mnist数据集是一个入门级的计算机视觉数据集。
t10k-images-idx3-ubyte.gz,训练图片集;t10k-labels-idx1-ubyte.gz,训练标签集;
train-images-idx3-ubyte.gz,测试图片集;train-labels-idx1-ubyte.gz,测试标签集。
训练集有60000个用例,同样数量的标签,每个标签值为0~9,每个图片都是28*28像素=784个元素。
训练图内容使用16进制表示的,其中0000 0803表示魔数(魔数就是一个校验数,用来判断这个文件是不是mnist的相应文件)
0000 ea60表示60000容量,0000 001c表示每个图片的行数,0000 001c表示每个图片的列数。之后的内容就是像素值。如下图

上图描述,784个字节代表一幅图。
自动下载/加载mnist训练库(鄙人下载了好久,下载一次之后再使用就不会再下载了):
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
三、tensorboard
原本的代码单纯为了介绍机器语言,鄙人为了后面可以直观的看到tensorboard图,在这里额外添加了用于该功能的内容。这些内容主要以:with tf.name_scope('aaa'):语法格式出现。其中aaa亲测只能支持英文。
四、定义输入
首先是一个些用于该训练的定义了一些数组,分别为x、w、b、y_:
x是一个不知道多少行但是知道有784列的浮点型数组(placeholder表示先不赋值,仅占个坑位);ps:程序开始时,会将图形的点阵赋给x。
w是784行、10列的全零数组;
b是一个由10个零组成的数组;
y_是不知道多上行但是知道有10列的浮点型数组。
with tf.name_scope('input'):
##x是一个占位符,浮点数形式,None表示张量的第一个维度可以任意长度。每一张图展平成784
##维的向量。
x=tf.placeholder(tf.float32,[None,784],name='x')
##用全部为零的张量初始化w和b。因为要学习w和b的值,所以初值可以随意设置
##w的维度是[784,10],因为用784维的图片向量乘以它以得到一个10维的证据值向量。
##b的维度是[10],直接加到输出上即可。
w=tf.Variable(tf.zeros([784,10]),name='w')
b=tf.Variable(tf.zeros([10]),name='b')
######交叉熵:这个模型是好是坏,这个指标成为成本或者损失(loss),成本函数就是交叉熵
##我们用定义一个新的占位符y_
y_=tf.placeholder('float',[None,10])
五、tf.matmul和tf.nn.softma
然后是定义激活函数,以及定义如何使用它,这里会用到tf.matmul和tf.nn.softmax两个函数。
通过 tf.matmul 函数将数组x和w进行乘积,然后通过 tf.nn.softmax函数判断是否该被激活。
计算机系出身的学渣同胞们,看到这里是不是懵逼了,我也是懵逼的(数学系和学霸们若鄙视我请轻鄙视)!
先补习一下数学知识,否则后面会一直懵逼下去,什么是数组的乘积:
数组A为2行3列,数组B为3行1列。那么AB为2行1列的数组。
假设数组A为[[1,2,3],[1,2,1]],数组B为[[1],[2],[3]],那么AB为[[1*1+2*2+3*3],[1*1+2*2+1*3]]即[[14],[8]]
所以tf.matmul(x,w)第一次执行的时候的意思就是:x数组(行数为?,列数为784)和w数组(784行,10列,全零数组)的乘积,结果为?行、10列全零的数组。
tf.matmul(x,w)+b的意思就是这个?行、10列的数组和一个1行,10列的全零数组求和。得出的数组为?行,10列,每行的每个元素和对应的元素进行相加。
tf.nn.softmax函数如下图表示,其取值范围和值的范围如下图所示:
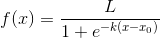
也就是说,通过softmax函数,将数组(tf.matmul(x,w)+b)映射成一个新数组y,其中数组y中的每个元素都是一个0~1之间的常数(我们可以根据这个常数的大小进行多分了任务,如取权重大的一维)。
由于x中的元素无负数,所以通过激活函数得到了一个新数组y,里面的元素都是0.5~1之间的常数,若为0.5则意味该原始元素为0,我们可以认为28*28元素对应的y只有大于0.5才是有效值,才说明该元素位置含有有效信息。
with tf.name_scope('softmax_matmul'):
##tf.matmul表示x乘以w,softmax值在0~1之间,当f(x)的x=0时f(x)=0.5,0.5是中间值
y=tf.nn.softmax(tf.matmul(x,w)+b)六、交叉熵计算
tf.log():将数组y的每个元素求对数。曲线如下图:
tf.reduce_sum():求和,由于求和的对象是tensor,所以是沿着tensor的某些维度求和。在此就是将所有元素求和。
由于数组y的元素都为0.5~1之间的常数,通过tf.log(y),将每个元素以e为底求对数,所以值为(-0.3~0).
y_为?行,10列的浮点型数组,用y_与tf.log(y)相乘。然后求新数组元素的和。
交叉熵是什么:可以参考链接http://www.cnblogs.com/awishfullyway/p/6068565.html
交叉熵有什么用:对比两个概率分布之间的差异性。差异越大则相对熵越大,差异越小则相对熵越小,若两者相同则熵为0。
下文反向传播算法函数将调用该交叉熵,并对w和b进行微调。
交叉熵计算的代码如下:
with tf.name_scope('jiaochashagn'):
#计算交叉熵,其中lg(y)属于-无穷到一个正数之间
cross_entropy=-tf.reduce_sum(y_*tf.log(y))七、计算损失(方差代价函数)
tf.square(y-y_):计算(y-y_)的平方数。
tf.reduce_mean():求该数组中平均值。
y是一组有0.5~1之间的常数组成的数组。y_是一组mnist的元素组成的数组(y_为?行,10列的数组,具体内容是对应x数组的,用来保存真实值的数组)
为什么要计算损失:在训练神经网络过程中,我们需要通过梯度下降算法(反向传播算法)更新w和b,因此需要代价函数对w和b的导数;
可以参考链接:http://blog.csdn.net/fuwenyan/article/details/54767316?utm_source=itdadao&utm_medium=referral
计算损失代码如下:
with tf.name_scope('loss'):
loss=tf.reduce_mean(tf.reduce_sum(tf.square(y-y_)))八、反向传播算法
为了得到更好的w和b,我们使用GradienDescentOptimizer执行梯度下降以降低成本。用非技术的术语来说:当给定当前成本,并基于成本的其他变量(即w和b)的变化方式,优化器(optimizer)将对w和b执行一些小调整(递增或者递减)以使我们的预期更好的契合那个单个数据点
可以参考链接:http://mt.sohu.com/20160822/n465358601.shtml
反向传播算法代码如下:
##使用反向传播算法不断修改变量以降低成本
##以0.01的学习速率最小化交叉熵。
##梯度下降算法(gradient descent algorithm)是一个简单的学习过程,tensorflow只需要
##将每个变量一点一点的往使成本不断降低的方向移动。
with tf.name_scope('train'):
train_step=tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)##这个cross_entropy可以用loss替代
定义初始化变量方式:
##初始化创建的变量
init=tf.initialize_all_variables()绘画开始:
with tf.Session() as sess:
##tensorboard需要用到的内容
##merged=tf.merge_all_summaries()
summary_dir='path/log'
writer = tf.summary.FileWriter(summary_dir,sess.graph)
sess=tf.Session()
sess.run(init)
##开始训练
for i in range(20):
###随机抓取训练数据中的100个批处理的数据点
batch_xs,batch_ys= mnist.train.next_batch(100)
##print('x的值','\n',sess.run(batch_xs),'\n','y_的值','\n',sess.run(batch_ys))
print('run以后的值:','\n',sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys}),
'\n','w的值:','\n',sess.run(w))
##tf.argmax是一个非常有用的函数,他可以给出某个tensor对象在某一维度上的其
##数据最大值所在的索引值。由于向量由0、1组成,因此最大值1所在的索引位置就是
##类别标签,比如tf.argmax(y,1)返回的是模型对于任一输入x预测的标签值,
##而tf.argmax(y_,1)代表正确的标签,我们可以用tf.equal来检验我们的预测是否真
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
##这一行代码给我们一组布尔值,为了正确预测项的比例,我们可以把布尔值转换浮点数
##,然后取平均值。
accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float"))
print('正确率:','\n',sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
代码片段到此就已经全部完成了。之后就是在tensorboard页面里面看一下这个简单的代码的“样子”:
1、打开 anaconda prompt。
2、通过代码:activate tensorflow回车,进入tensorflow模式
3、使用跳转命令进入日志存放的文件,如上文描述,我的log文件放在了J:\office\python\path\log\下。那么我就跳转到path目录下
4、通过代码:tensorboard --logdir=log/运行tensorboard
5、使用浏览器打开127.0.0.1:6006进入tensorboard页面
6、进入“GTAPHS”标签即可。
没错,从机器语言知识海洋的大门外远远看过去:大海全是水,地狱全是鬼,蛤蟆四条腿!















 1380
1380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









