




说明
结构上的整理和实验陆续进行了3个月左右,目前对现有的结构进行一次梳理和计划。希望2021年之前把结构相关的问题基本弄完(还是更愿意搞算法)
1 目前的结构思路
整体结构上的目标有如下几点:
-
1 对管理(开发)者提供操作上的便利。包括启动、停止服务;监控整个网络的资源情况;权限的修改等等
-
2 对用户提供便利。
- 超级用户(S):超级用户需要方便的进行频繁/大量的设置,数据上传,备份等;还需要进行大规模的数学计算。
- 商业用户(B):商业用户需要针对某些业务问题的功能,功能清晰、使用方便、服务稳定。
- 一般用户(C ):可以高效的阅读、获取知识。以及一系列生活相关的功能,例如听音乐。
-
3 方便随时转为正式商用。
-
4 有用、可靠、高效、灵活。
- 服务提供的功能有用
- 服务是可靠的
- 计算非常高效
- 调整起来很灵活
-
5 开发和维护相应功能的成本极低。
设计上排除考虑的情况:大量的并发请求(吞吐),从功能上,该系统并不打算面向大量用户(<5万用户)。
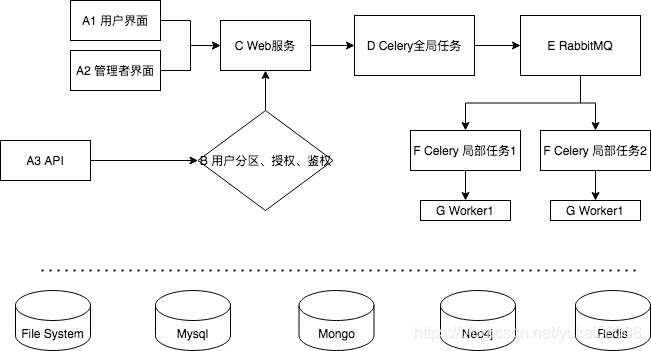
A 外部访问方式
H5的方式用于简单的人机交互。从应用层面将一系列的操作和服务进行封装和优化,使得用户可以通过点击拖拽完成常用任务。
H5的方式还区分系统的消费者和生产者。管理者的视角和普通用户不同,最好单独起一套交互界面。普通用户的界面将会根据用户的角色、喜好进行个性化的优化展示。
API的方式则适合与生产上的大规模调用。
B 分区、授权、鉴权
用户的基本情况应该包括了
+ 分区:哪些功能区是可以对用户开放的(不开放的化网页就不会展示)
+ 授权:除了功能区,还有具体的权限,有效期等
+ 鉴权:确保是用户在使用
除此之外,还应当包括以下内容
+ 用户:所属群组
+ 信用点:服务都是以信用点来支付的
+ 充值:信用点用光后用户需付费
+ 提醒:邮件、短信、微信提醒
C Web服务
除了Web服务本身,还要对Web服务提供负载均衡、流量缓冲等的支持。毕竟理论上希望支持不超过5万用户的服务,考虑一定的并发也是有压力的。
D Celery全局任务
与各资源保持心跳。整个网络内有几台机器,每台机器的CPU、GPU、内存和硬盘的即时情况(甚至包括cpu温度等信息)。每个任务有几台机器可以提供服务,例如m1_app1, m2_app1表示目前有两台机器提供app1的服务。
任务的冗余分配计划。为了防止单点失效,全局任务会将相同的任务发给几个机器同时计算,并设置超时时间。这里会涉及怎样的结果认为准确有效,如果失败或者超时了怎么办?
资源性能评估以及优化分配。计算每个任务完整的时间、状态,评估每个资源的性能。
E 消息队列
算网会设计大量的计算,特点是数据量可能偏大,但是消息数量不会特别多。
RabbitMQ比较适合做这个任务。另外,消息的序列/反序列化使用pickle, 因此要么由服务器发起固定的计算任务,或者由超级管理发布定制任务,但是不允许用户发起定制任务。
未来如果考虑信息安全,可能还会进行一些校验,防止篡改。
F 局部任务
局部任务目的是整合一台计算机上所有可用的资源,较快的完成任务。例如使用多核进行计算,或者将一些异步请求进行协程。
可以进行矩阵运算的尽量交给GPU,剩下的交给CPU。
G 工作者
函数和应用就写在这里。所有的函数都以注册的形式添加到Celery下辖的任务包里,这个过程是动态的。
必须使用Git。如果是信息安全等级低的,使用公网Git;否则走私网Git。
开发完成后,进行push和合并,然后在各worker执行拉取和更新。
这样每个任务不仅有名称(函数名称),还必须有版本号。
如果worker接到任务后发现没有此函数,那么就尽心git pull进行更新。
函数注册使用的主键是代号, func1 …。 函数名称是昵称,是func1键值的一个属性。同样,版本也是func1的属性。
- func1
- name
- version:版本
- description:描述
- create_time
- update_time
- developer_name
- developer_contact
- developer_cell
- data:函数对象
- content:函数文本
从应用角度看的三层结构
从上到下依次为交互层、调度层、应用层
1.交互层
产品的易用性。
这层的任务是使结果得以简洁美观的展示,用户可以通过web方便的进行操作。
从用户的角度:
- In: Bootstrap风格的页面;静态表;图表;video(这个会链到B站); audio
- Out: 点击,普通表单
- Interactive: datatables
2.调度层
系统层面实现可靠、灵活、高效的基础。
原来计划以RabbitMQ为基础,进行分布式的可靠服务,现在看来不行。真应了“成熟的产品和套件80%的功能都是好的,就是你要的20%功能有点问题”。
现在计划以Flask+apscheduler 进行调度(相当于原来RabbitMQ的服务器), mongo作为持久化队列, apscheduler的Blocking或者Backend方式作为Worker(一个启动后就不准改了,另一个可以开放任务调整)。
中间的查询或者数据收集等IO密集的工作将使用asyncio+aiohttp完成。
这样就实现了一个真正分布式异步任务调度系统,可控性和可追溯性比我用Pika+RabbitMQ的方式要好的多,例如:
- 1 不用管Worker和MQ Server之间的心跳。通过默认的whoami队列(存在于mongo的集合),服务端可以知道哪些worker在线。
- 2 worker取几条数据通过数据库查询实现,一定生效。例如worker从mongo对应的集合(相当于信道)进行筛选,排序,然后取n条。(limit n)
- 3 动态调整任务。worker以固定的规则取数,所以只要直接修改任务的优先级或者is_enable字段,就可以调整任务的执行顺序。
- 4 可追溯。通过一些代码上的微调,我可以让每个worker的几个动作可以被追溯到。
将来如果并发大了,可以使用redis,会更快一点。总体上我觉得mongo可以了。
调度层需要的两个工具
- 1 异步并行调度系统
- 2 有限状态机(确保所有的功能、资源都在状态机控制之下)
3.应用层
这个是价值的核心。大概有几步:
- 1 商业价值转换为计算机模型/算法问题
- 1 问题的抽象
- 2 人工执行现状
- 3 智能实现的预估
- 2 快速开发框架
- 1 基于图结构
- 2 project & schema
- 3 多分支探索
- 4 编排逻辑(非hard code)
- 3 可靠性框架
- 1 服务类别与策略
- 2 基于调度系统的实现
- 3 解释与追溯的构建(想象一个场景:客户说出了一个bug, 你可以打开电脑,甚至只用手机,可以在5分钟内定位并解决掉问题)
应用层的几个特征:
- 1 建模基架
- kaggle竞赛
- 2 微型引擎
- 编排式编程
- 3 深度学习
- 图像
- 自然语言
- 4 图结构
- 一切结构表达为图
- 5 概率图
- 核心推理能力(空间、时间)
2 下一步计划
按结构进行完善,目前第一个点是前端页面的快速生成,第二个点是celery的异步任务体系搭建。
- 1 前端页面的快速生成。目前已经探索了基于2层jinja的模板生成方法和基于bootstrap4的简单行列布局。接下来要进一步把这个变的方便。
- 2 celery异步体系。目前功能测试ok,但是还没有转为实际使用。
2.1 NOV
以下三点希望11月份能搞完。
- 1 梳理并完善前端页面的快速生成模式。以完成一个portal作为目标。
- 1 portal是按照新模式生成的,意味着随时可更改。
- 2 具有一个datatables后端交互页面
- 2 算网建设的继续演进。
- 新增一台机器(m4)
- 新机器的配置全部通过脚本完成。装机过程
- 在新机器上设置iptables, 只允许本地局域网和一个公网ip通信,其他全部拒绝。
- 3 Celery本机任务框架。
- Celery的项目框架搭建。
- Celery的任务动态注册。
- 打包为容器。
回顾一下十一月的情况:
-
1 任务一:完成一个portal,失败。勉强迅速梳理了一下一点点文档系统的东西,算是挽尊吧。
-
2 任务二,新增一台机器(m4),成功。效果比预想的还要好,cpu长期运行无压力。
-
3 任务三,Celery本机任务框架,失败。基本的任务搭建是成功的,但我正好有一个基于Kashgari(基于TensorFlow和Keras的一个实体识别的封装包)的BERT任务。一执行任务就无反应了。我认为这样的任务框架是不可靠的。后来还尝试了直接使用RabbitMQ和Pika的搭配,也失败了(心跳问题以及任务大结果的结果无法输出问题)。
好处是,我基本放弃了Celery和RabbitMQ,确定自己做一个基于Mongo的分布式任务系统。
十一月份额外的礼物,考了两个认证(花了我大约12个working day的时间,嗯,我一个月大约有30个working day)

2.2 DEC
以下三点希望12月份能搞完。
- 1
为Web Server增加markdown和bi页面模板。
原来跨度有点大,想一步到位:直接由图生成H5元素。现在觉得还是要退一步,先人工,再智能。即先做多一些重复性的工作,再进行提取。
- 2 算网建设的继续演进。
- 新增一台机器(m5),带3060Ti(完成)
- 配置和使用CUDA(完成)
- 计算测试(完成)
- 通用Numpy转Pytorch张量计算
- 机器学习运行时间对比(Pytorch)
没想到还要做多一遍,基础扎实点
3 Celery的全局框架- 1 冗余分发机制 未完成
- 2 资源状态收集 未完成
- 3 性能统计(需要在消息上增加元数据)未完成
这个任务改为自建分布式任务系统。先把apschedular搞好,后面结合flask服务和mongo的东西就比较简单了。
回顾一下12月的情况:
- 1 m5装好了,CUDA也用起来了,美中不足的是新驱动跑tensorflow1.x的时候由cuBLAS错。
- 2 简易的portal也搭了一个,只是连接几个主要的服务。
- 3 datatables搞的差不多,还有一个参数化创建表格的修改。(使用Jquery直接访问每个单元格)
- 4 apschedular确认可以用,还差没有结合flask做动态的管理。
- 5 转向使用mongo和neo4j的准备工作差不多了。
- 6 使用m4建立统一的代码仓库
- 7 单机配置和脚本的仓库文档化,以后装机和配置会更快
总体算还是意料之外,情理之中吧。
2.3 JAN
以终为始, 重新安排一下各块技术栈的推进协调,大体上如(建模杂谈系列51- 用户权限设计)提到的:
- 第一步:完成一个最小化的完整服务单元
- 第二步:进行工具和结构的优化,提供「好服务」
所以一月份的目标就是启动一个完整的服务单元。分解为以下三个目标:
- 1 建立授权/鉴权服务。这个服务将为所有的算网内服务提供统一的服务,该服务使用neo4j进行权限的管理,并使用mongo进行日志记录。
- 2 完成基于datatables的前后端交互。通过这种方式,实现h5页面方便的和后端进行较多的操作。主要将用于我将所有的结构性工作转向图库。
- 3 完善portal的内容分类和引导。portal需要集成所有微服务,并且要进行框架性的引导,确保未来的记录方便又有序。

















 5006
5006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









