










目录
一、整体说明
这篇论文在横向方面,主要是需求和工程角度,说明了最新的LLM-based Agent的前沿技术和研究讨论。
二、具体解读
1、作者

2、介绍
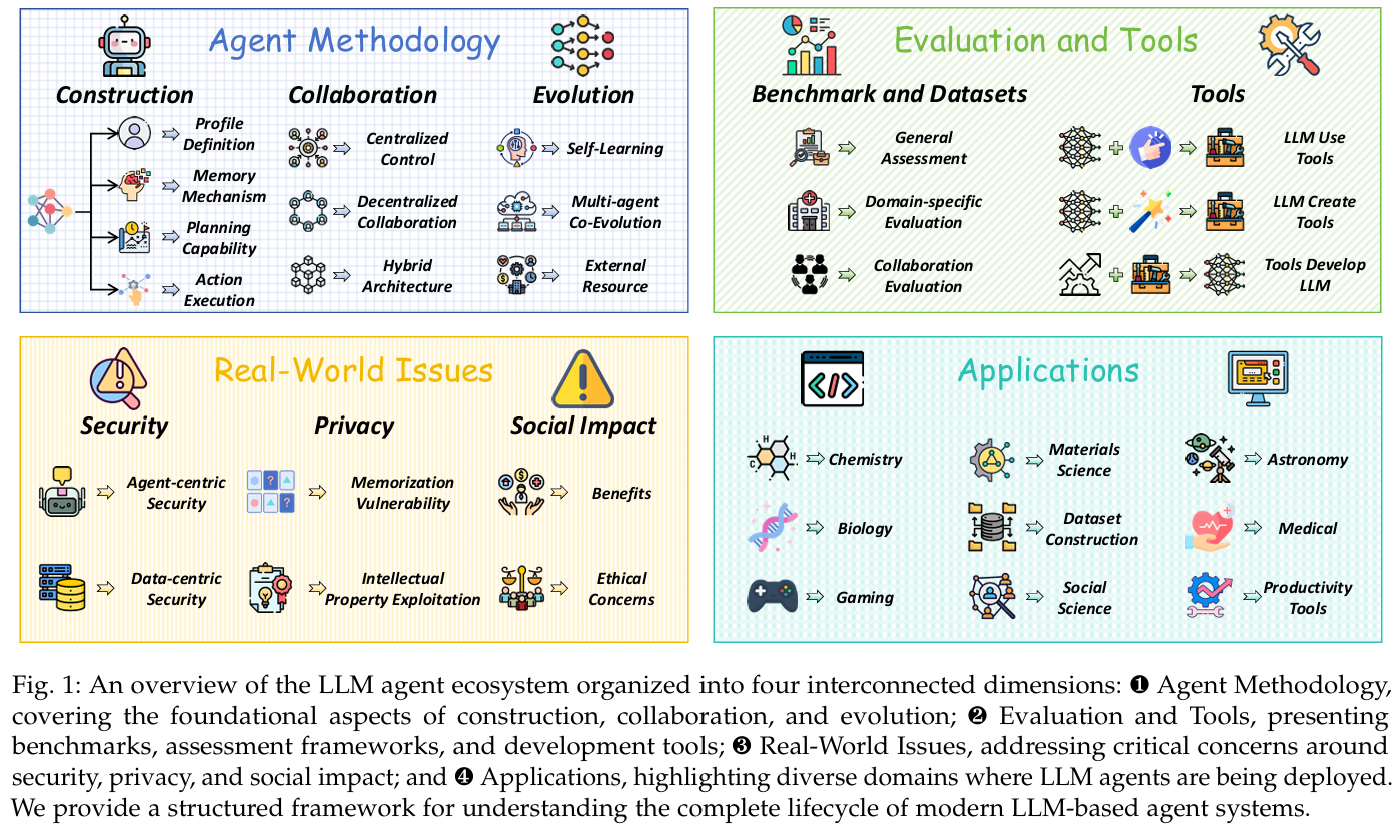
Agent的相关技术是伴随着LLM技术的进步而发展的。由LLM推动的技术进步改变了原有的技术范式,很大程度上是由于LLM可以作为通用任务的处理器。
3、方法
(1)构建
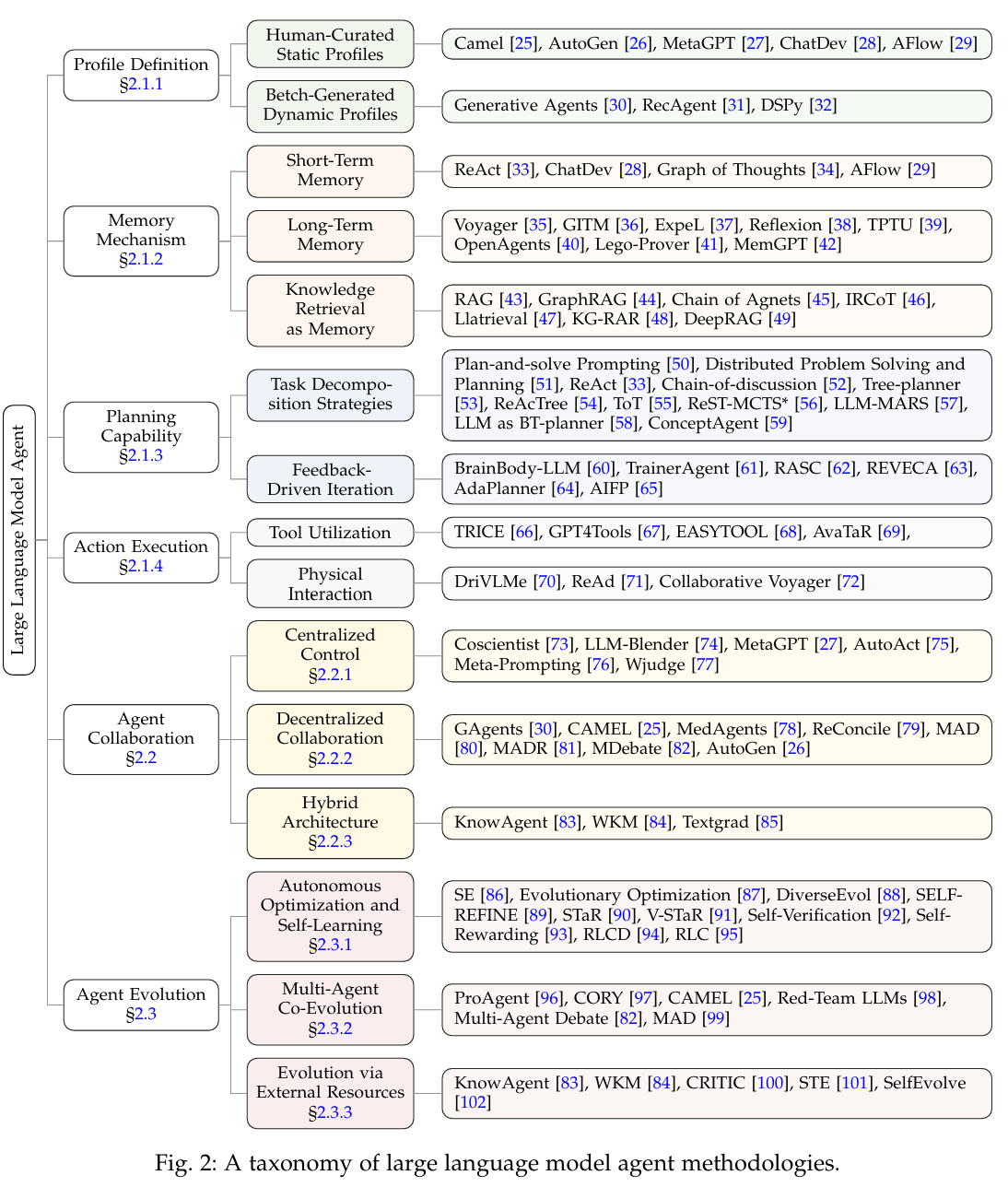
(a)配置文件
配置文件的作用有2点,1是定义agent的内在属性,2是规定agent的行为模式。
配置文件有2种:
- 静态文件。由人工设置,有明确指定。通常设置的是静态结构化角色,通过结构化对话,完成指定任务。
- 动态文件。这里指的是批量产生的文件。通过参数初始化设置,模拟多样化社会行为,以进行人类社会行为研究。
(b)记忆
Agent的短期记忆即Agent的部分状态,与LLM的技术很相关。Agent的外部记忆通常是外部数据,使用的是非当前Agent进行推理的LLM的技术。短期记忆相关的实现与具体LLM相关很大,而外部记忆是可以与LLM独立的另一套技术。
记忆有3种:
- 短期记忆。通常指context,直接与交互式交流相关,使用非常广泛。这与LLM相关性较大,LLM存在上下文限制,具体实现需要限制交互深度,以及可能需要实现额外的信息压缩机制。
- 长期记忆。Agent的推理轨迹。将短暂认知转换为长期记忆有3种方法:
- 程序技能知识库。
- 成功/失败模式体验库。
- 工具合成框架。
- RAG。外部知识库。使用外部知识的方法有3种:
- 文本语料库或结构化知识图谱。
- 交互式检索。进行外部查询。
- 推理集成检索。推理和动态知识获取交织在一起。
(c)规划
在面临复杂问题,LLM的规划能力就变得十分重要。LLM需要高精度浏览复杂任务,思考问题的场景。
- 任务分解策略。任务分解是规划能力的基本方法。任务分解的目的是,通过一种方法,一个复杂的任务可以变成一系列的易于管理的子问题。分解策略有2种:
- 单路,链。基础版本,Plan and Solve范式,zero-shot CoT,子任务由预定的顺序执行。这种方法简单但缺乏灵活性,过程不能有偏差,否则会发生错误累计。改进方法,动态规划,只生成下一个子问题,步骤中接收反馈动态调整。或者另一种改进,集成方法,多条CoT,最后结合,提高稳健性,也能够做出更准确的决策。
- 多路,树。允许LLM进行回溯,回到以前的状态,从而实现试错和纠错。实际中还可以进一步使用更好的算法做出更明智的决策,现实场景也可以结合RL进行调整。
- 反馈驱动迭代。Agent从执行的过程中收到反馈,进行调整。反馈的来源有:
- 环境。
- 人工。交互或提前准备的数据。
- 自省。
- 多智能体。
(d)行为
行为涉及2个方面:
- 工具使用。使用工具的能力涉及工具使用决策和工具选择。
- 物理交互。这是具身LLM相关的方面。
(2)协作
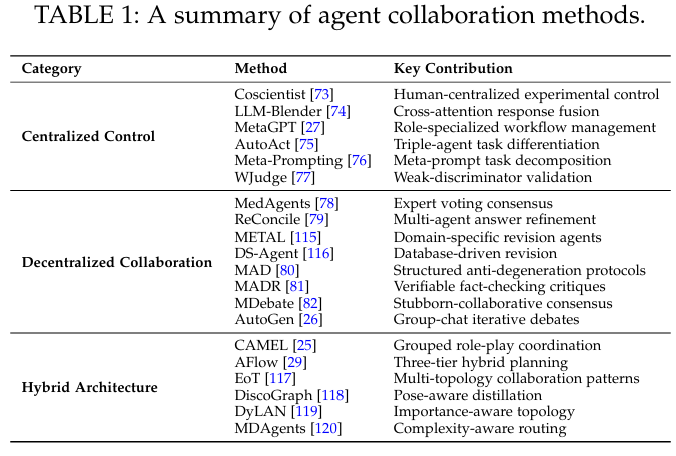
multi-agent是现在的主流。基本架构有3种,集中、分散、混合。这些影响在决策、通讯、任务分配方面。
(a)集中控制
分层协调机制。中央控制器分配任务、进行决策,其他agent只与中央控制器进行通信。集中式架构存在的问题是,控制节点处理所有的通信、任务调度、争用解决,该控制节点可能成为瓶颈。
具体的范式有:
- 显式控制器。标准流程。
- 差异化系统。将控制的Agent进行分解,例如划分为计划、工具、反思。
(b)去中心
解决集中式架构的中心控制节点成为瓶颈的问题。通过自组织协议,节点间直接交互。
具体的范式有:
- 基于修订。Agent观察其他节点的生成,迭代优化共享输出。这种架构中节点可以不是agent,支持混合优化策略。
- 基于通讯。更灵活的组织结构。允许直接参与对话和观察其他节点推理,适合动态场景建模。
(c)混合
组合集中和分散架构,平衡可控性和灵活性,用于异构任务需求。
具体设计范式有:
- 静态系统。预定义协调规则。预定义的固定模式用于组合不同的协作模式。具体实现大多是通过分层次实现的。
- 动态系统。自我优化拓扑。通过实时性能反馈,动态调整协作结构。
(3)进化
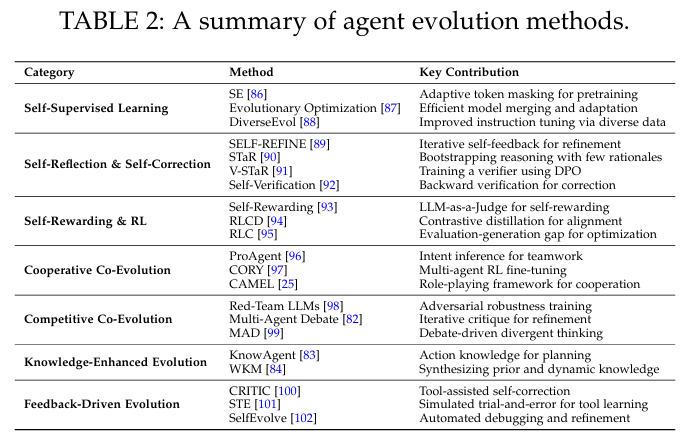
Agent发展的机制,支持自主改进、多智能体交互、外部资源集成,以实现在复杂环境的适应性、推理能力、性能。
(a)自主优化和自学习
没有外部监督的情况下进行改进,动态探索、适应、优化输出。
- 自我监督学习和自适应调整。这指的是LLM,对于LLM训练时的方法改进。
- 自我反省和自我纠正。迭代优化输出,自我验证和自我优化,回顾性评估和纠正。
- 自我奖励和强化学习。使用RL的方法,自我奖励或外部奖励,增强LLM的适应性。
(b)多智能体协同进化
Agent通过和其他agent进行交互进行改进。
- 合作和协作学习。知识共享、联合决策、协调。具体实现过的方法有,推断其他agent意图和更新信念来动态适应合作,将RL微调扩展到协作式多智能体框架中。
- 竞争和对抗的共同进化。对抗性互动、辩论,战略竞争。发展更强的推理能力、弹性、战略适应性。
(c)通过外部资源进化
- 知识增强进化。整合结构化外部知识、改进推理、决策。
- 外部反馈驱动进化。利用工具、评估人员、人类外部反馈来改进行为,迭代式提高性能。
4、评估和工具
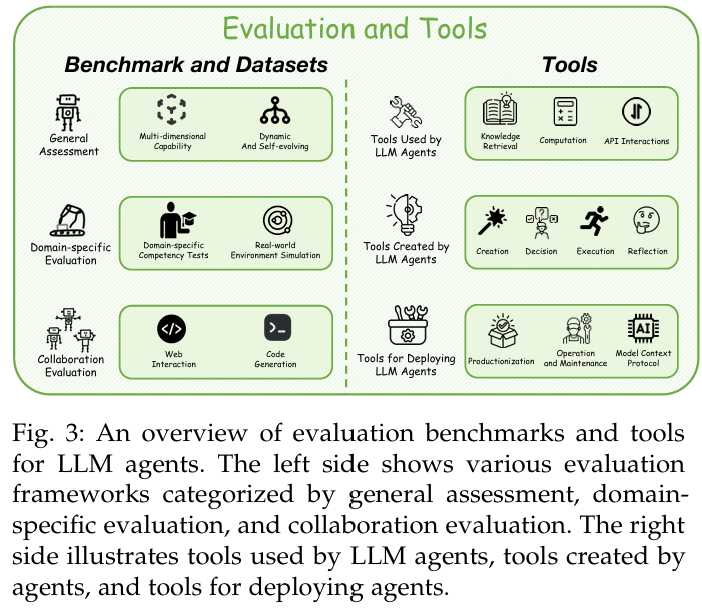
(1)评估基准和数据集
由于动态性,agent相关的测试不仅仅为数据集,很多测试需要具体的环境。
(a)一般评估框架
简单的要求是成功率,复杂一些的是全面认知分析。目前的研究进展集中在:自适应和可解释性,捕捉:推理深度、环境适应性、任务复杂性。
- 多维度能力评估。分层范式,分析维度有:推理、规划、问题解决。
- 动态和自我进化评估。未来的范式,通过自适应生成和人类ai协作来自动创建。
(b)特定领域评估系统
特定领域知识和环境限制,量身定制。双轴框架,垂直能力测试,专业场景;水平验证,真实模拟环境。
- 特定领域能力测试。情景驱动。已有:医疗保健、自动驾驶、数据科学、旅行规划、机器学习工程、安全。
- 真实世界模拟。真实交互环境。
(c)复杂系统协作评估
智能体系统向组织复杂性发展,评估框架也对应进行改进。
- 多智能体系统测试。
(2)工具
(a)LLM使用的
一些特定任务,LLM需要使用的工具,主要是为了实时信息和准确计算。
- 知识检索。LLM不知道的信息,访问实时信息,如搜索引擎。
- 计算。LLM需要处理精确计算。python解释器和数学计算器。
- API交互。调用外部服务。
(b)LLM创建的
LLM的代码解决方案。解决方案链(CoS)。4阶段框架,创建、决策、执行、反馈。
(c)部署LLM
维护和数据采集。
- 产品化。生产环境相关,经典的:autogen、langchain、llamaindex,dify。
- 运营和维护。保证训练过程良好,生产过程可靠。观察和监控。经典的:ollama。
- 模型上下文协议。标准化应用程序如何给LLM提供上下文。MCP开放协议。
5、现实世界问题
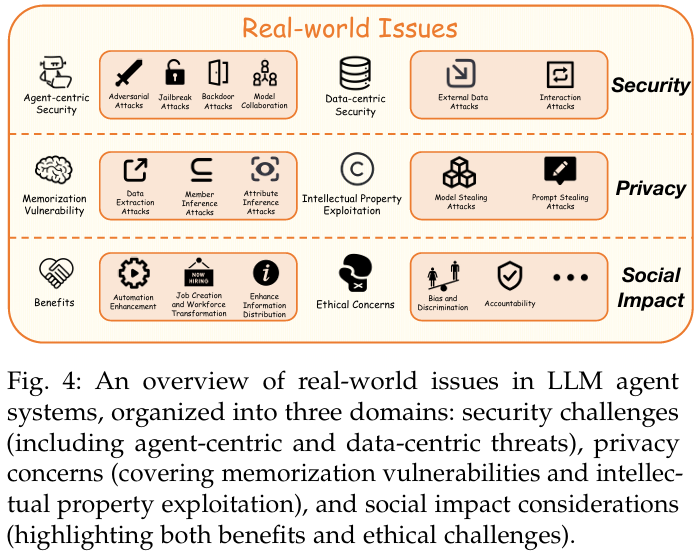
(1)以Agent为中心的安全性
- 对抗性攻击和防御。
- 越狱攻击和防御。
- 后门攻击和防御。
- 模型协作攻击和防御。
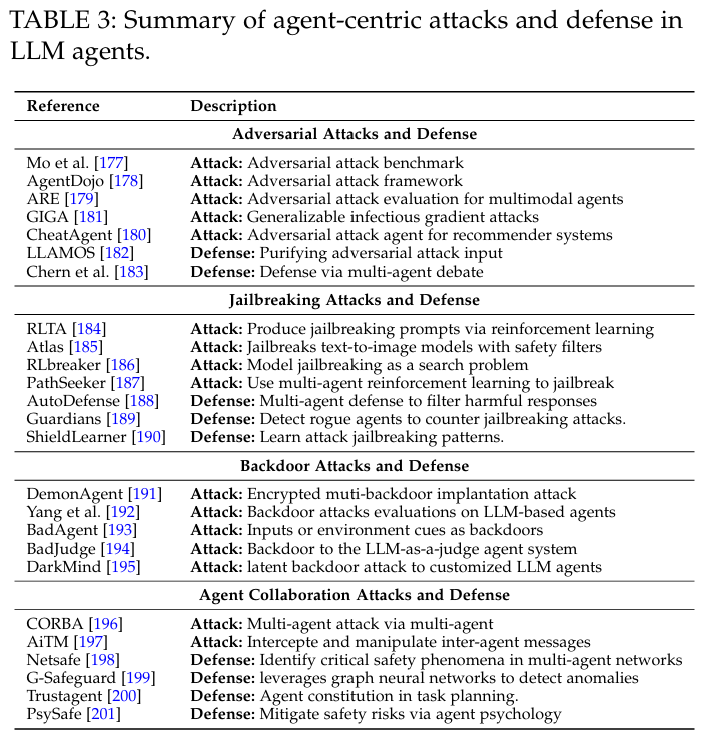
(2)以数据为中心的安全性
污染LLM agent的输入数据。
- 外部数据。用户输入伪造、黑暗心理引导、外部数据来源。
- 交互。用户与agent之间、agent之间、agent与工具。
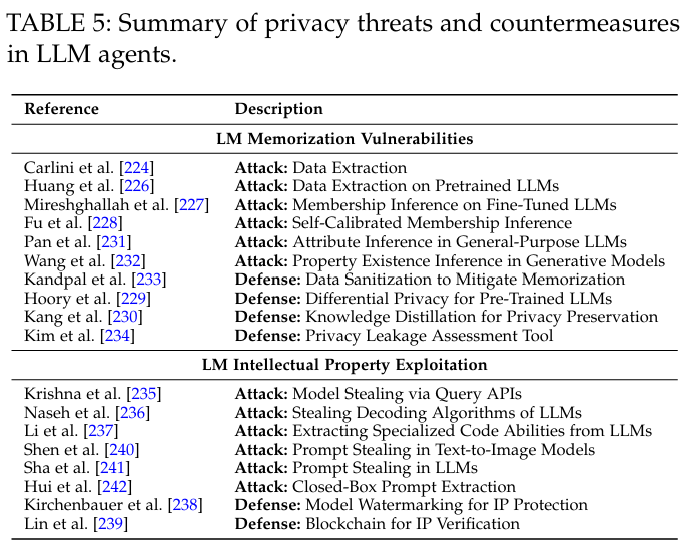
(3)隐私
- 记忆泄露。数据提取、成员推理、属性推理。
- 知识产权。模型设置、prompt。
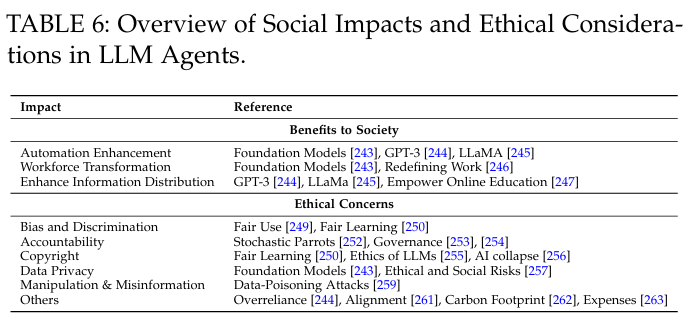
(4)社会影响和道德
- 对社会的好处。自动化任务、就业和劳动力转型、信息传播。
- 道德问题。偏见、问责、版权。
6、应用
(1)科学发现
LLM可以结合不同专业知识。
- 跨学科。
- 化学、材料、天文。
- 生物。
- 科学数据集构建。
- 医疗。
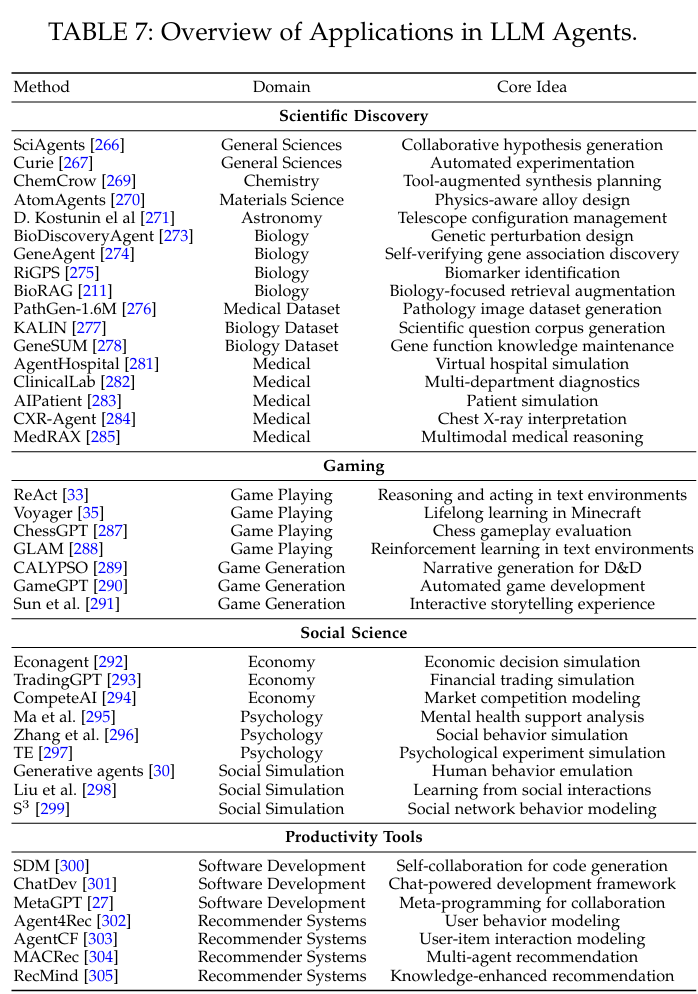
(2)游戏
- 玩游戏。角色扮演,可以作为玩家,也可以作为NPC。
- 游戏生成。创建动态和交互式游戏内容。
(3)社会科学
- 经济。分析财务数据,模拟金融活动。
- 心理学。模拟心理实验。
- 社交模拟。模拟社会行为。
(4)生产力工具
- 软件开发。
- 推荐系统。模拟用户行为。
7、挑战
(1)可扩展性和协调性
计算需求高,协调效率低下,资源利用低。未来的方向自然是分层设计,以及分散规划。需要更好的通信协议、调度机制,实现实时决策和系统稳健性。
(2)记忆限制和长期适应
需要保持多轮对话连贯性,知识纵向积累,需要有效的记忆机制。LLM对于上下文的感知有限,但需要将足够的信息集成到prompt中。未来的方向是分层记忆架构。
(3)可靠性和科学严谨性
LLM的知识不全面也不新,不是结构化数据库的替代品。LLM的随机性质,对于prompt敏感。需要额外的验证机制。
(4)多轮次、多智能体动态评估
目前的评估方法基于静态数据库和单轮任务。
(5)安全部署的监管
偏见和歧视。
(6)角色扮演场景
LLM数据来源于web语料库,对于人类认知的不完整理解,使得LLM可能模拟的角色不具有完全的代表性,因而对话缺乏多样性。
三、总结
这是一篇很棒的关于LLM-based Agent的综述。论文以方法论这个统一的视角,说明了Agent各个角度的细节。论文同时维护一个github的仓库,该仓库持续更新Agent相关的最新论文。
论文的主要有用的内容是agent方法、评估的部分,现实问题偏社科一些,应用和挑战是可以研究的方法。大部分内容是简单带过,例如方法部分就不如anthropic的构建agent的论文。但是,整体横向的内容非常全面,大部分研究都可以查找论文中的引用来实现,之后也可以回顾该论文以及查看仓库中的论文更新。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









