










目录
一、整体说明
这篇论文从LLM相关工程的各个阶段,说明了对于LRM如何进行更有效率的推理的现有工作和可能的改进。
二、具体解读
1、作者

2、问题介绍
大推理模型(LRM)最近很火,而一个很常见的问题是,这些模型的推理效率过低,多长的推理过程,并且冗余内容很多。对于简单问题过分推理,对于困难问题肤浅推理。
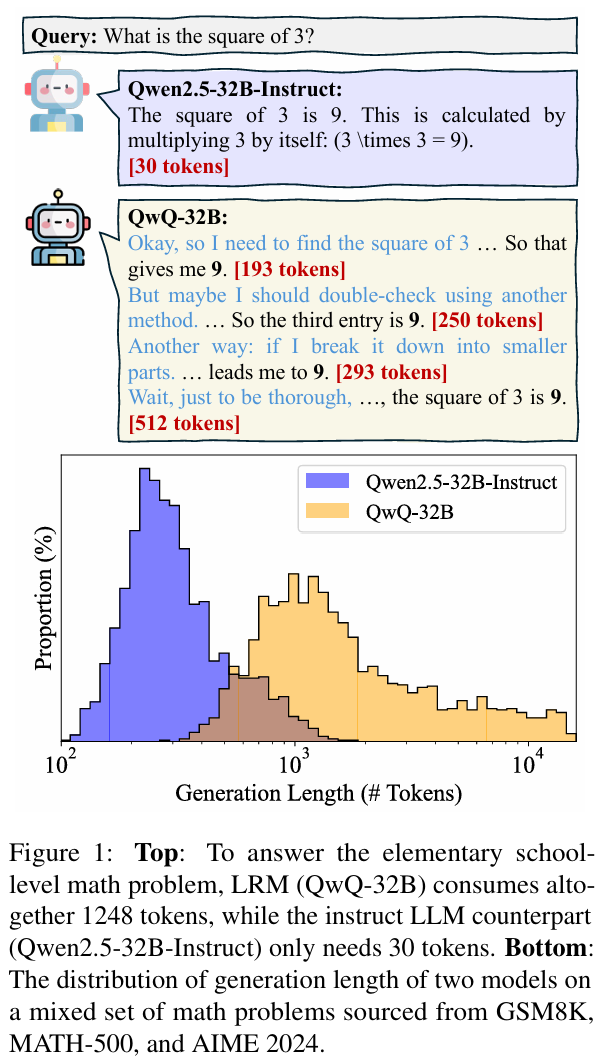
LLM发展到现在有2类,1是之前的可以快速自动决策的LLM,2是现在的面对复杂推理任务进行结构化分析的LRM。LRM显式生成中间推理步骤,也就是中间的CoT。效率也应该是智能的一部分,而不仅仅是推理本身。模型需要知道如何优化推理路径,平衡成本和性能。
目前已有的综述,有LRM全面综述、LRM训练方法、现有长思维链和推理范式,这篇论文是研究推理效率,从训练模型的具体步骤进行研究。
3、推理效率: 定义、模式、挑战
(1)效率的定义
本文下的定义,也就是研究方法。类似元学习,提出通用模型,在各种任务中都能够进行有效推理。任务会有自己的分布,也会有对应的数据集。我们需要去追求模型在生成质量和计算成本2方面的考虑,即性能和成本的权衡。
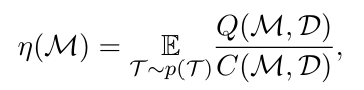
(2)低效模式
- 冗余内容。这是现有LRM的缺陷,即对于推理过程缺乏优化。很多模型只是为了能够表现出流畅的文本推理过程,但是核心的推理其实并没有进步。这会极大增加成本,但是性能方面提升有限。
- 过度思考简单问题。LRM的显著性能提升来自于多个推理回合和额外的验证检查,但这并不简洁,需要的计算成本是成倍增加的。
- 不连贯和次优推理。思考不足。过早改变推理方向,浅层和碎片化推理,没有连贯和深入的思路,从而在多个方法之间跳跃。
(3)独特挑战
- 量化推理的效用。难以评估每个步骤的效用。缺乏计算方法或数据集,确定可压缩和裁剪的部分。难以平衡推理简洁和答案正确。
- 思维的长度。控制思考的长度,不仅仅是在解码时强行限制,需要考虑语言信息和关键逻辑。
- transformer架构。input length是平方空间复杂度。
- 跨任务泛化。应该去选择具体的模型,推理策略或长度策略并不适用于所有任务。
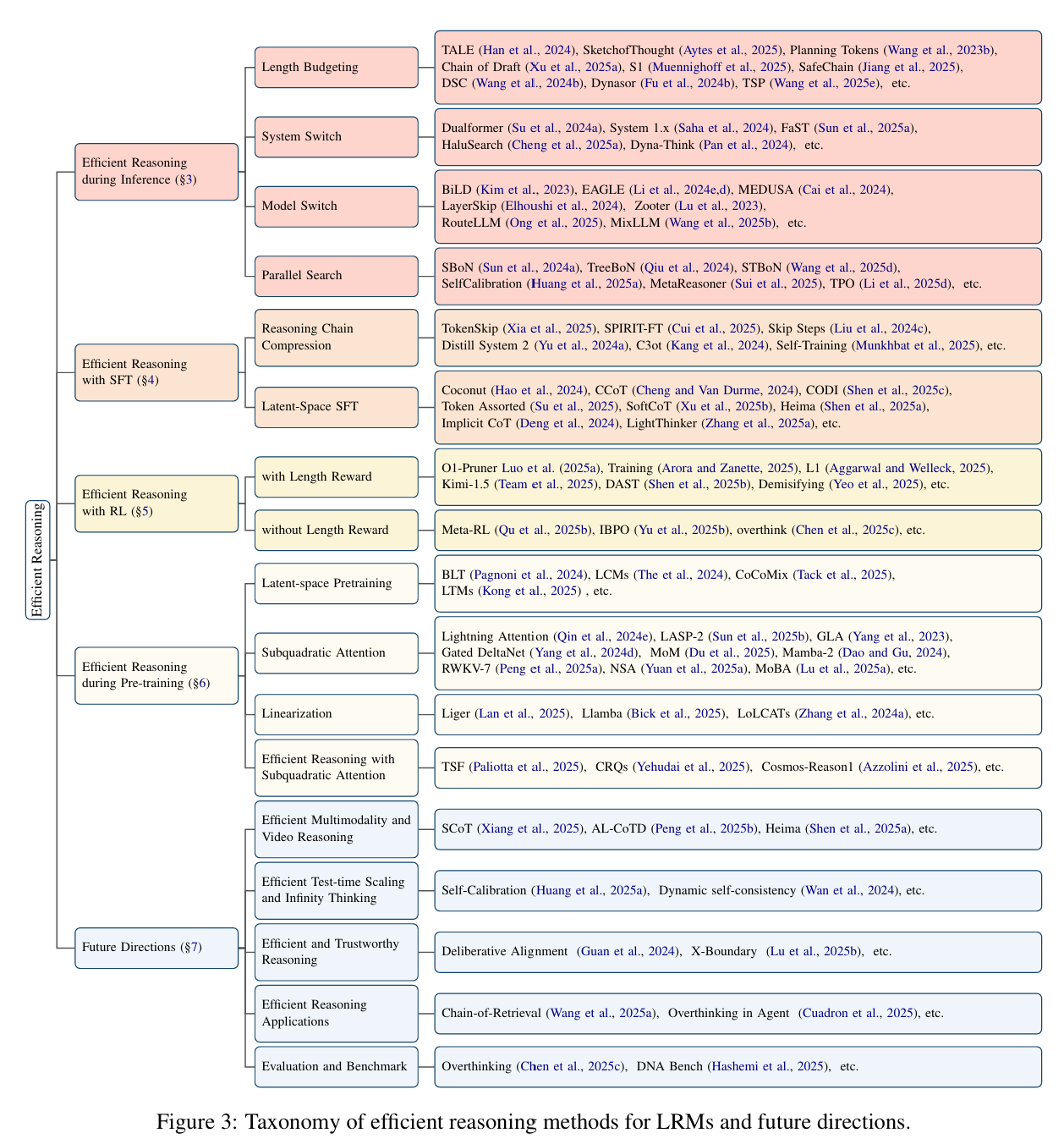
4、推理
目前已经采用过的方法,用于缓解LRM过长的推理。但是由于任务的复杂性,LRM很难采用合适的预算进行推理。目前主要的方法有:
- 长度预算。对于步骤或整个流程进行强制token数量限制。
- 系统切换。system1和system2动态交替。
- 模型切换。通过查询定向不同模型,使用轻量预测器或控制器。
- 并行搜索。同时多个输出、提前终止或裁剪。
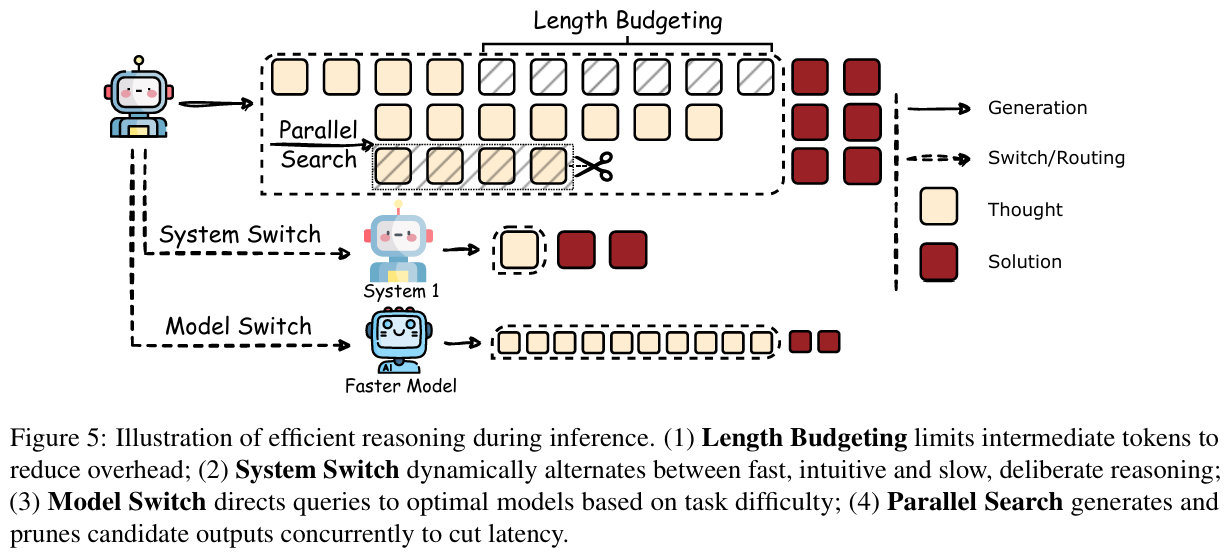
(1)长度预算
最简单的方法,直接明确限制长度。进一步,使用专门的prompt限制中间步骤,自适应范式如:概念链接、分块符号、专家词典。这类方法都是基于prompt的,复杂的方式可以明显减少思维链的长度。但是,过强的限制基本上会明显降低模型的性能。更好的方法是对于查询进行评估,从而动态分配推理资源。
(2)系统切换
dual process theory. 相关的研究来自于人类推理,ai领域外的研究也非常充分。system1快速决策但容易产生偏差,system2复杂推理和分析提供逻辑监督。以这种方式构造复合系统,优化平衡推理质量和效率。系统切换可以由专门的训练、用户定义、额外的适配器、模型自主决定。
(3)型号切换
接受更小的模型带来的性能损失,从而提高效率。主要方法有:
- 推测解码。草稿模型以及早退出机制、小模型快速预测大模型更正、草稿树、基于树的注意力、自推测解码验证。
- 路由。奖励引导路由、RouteLLM。
(4)并行搜索
提高顺序修订方法的效率,提高并行搜索的效率。通常是扩展搜索空间,提高性能,直到趋于稳定。方法如: 投票、自洽、best-of-n、验证器等。改进的方法是,不需要等所有的生成都完成,评估部分可能低质量的相应、TreeBoN中裁剪部分响应。
5、SFT
SFT是最直接的方法。
- 推理压缩。在不损失性能的情况下,减少CoT序列的长度。
- 隐空间推理。在隐空间进行推导。
一个方向是显式隐式结合,从而LLM可以自行决定推理策略。也可以进行自适应学习,从而提高模型的灵活性。不过,也需要保证显式隐式推理的一致性。
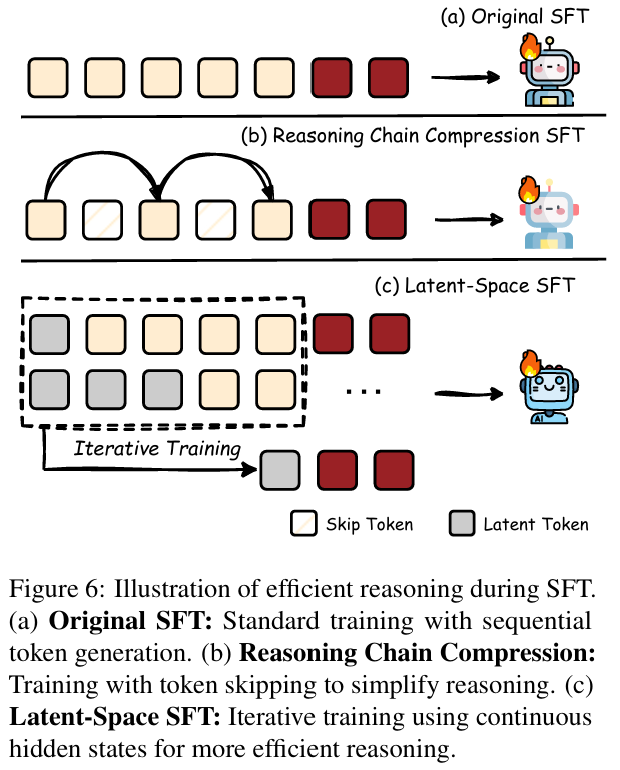
(1)推理链压缩
最直接的方法,通过更短的推理链的数据进行sft。简单的方法是直接处理数据集,用更短CoT的数据集,甚至没有推理步骤的数据集。
消除冗余的方法。外部依赖更强的模型。跳过中间步骤,评价步骤重要性的方法为perplexity。识别控制CoT长度的任务向量。
(2)latent space SFT
让推理发生在隐空间当中,而不是显式的输出token。在LRM出现之前,相关的定义是transformer的内部计算。
相关的训练方法是,Coconut、CCoT、CODI、SoftCoT等。
6、RL
主要由于deepseek-r1的影响,RL可以有效引导LLM的推理能力。目前相关的优化方法都是基于奖励工程。
目前关于长序列效率低下的观点和解决方案不定,研究问题也集中在可验证的数学问题上。一个发展方向是一般任务和多模态任务。现在的研究也只有长CoT推理,即链式推理结构,而并未使用其他推理结构,例如平行搜索、树、图。
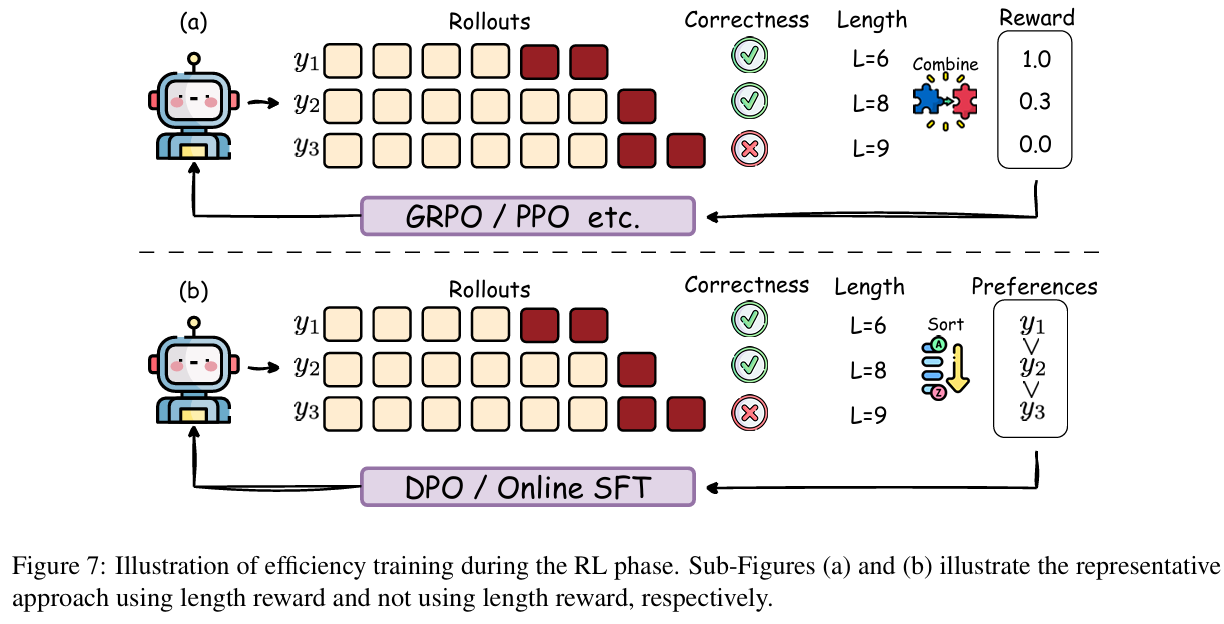
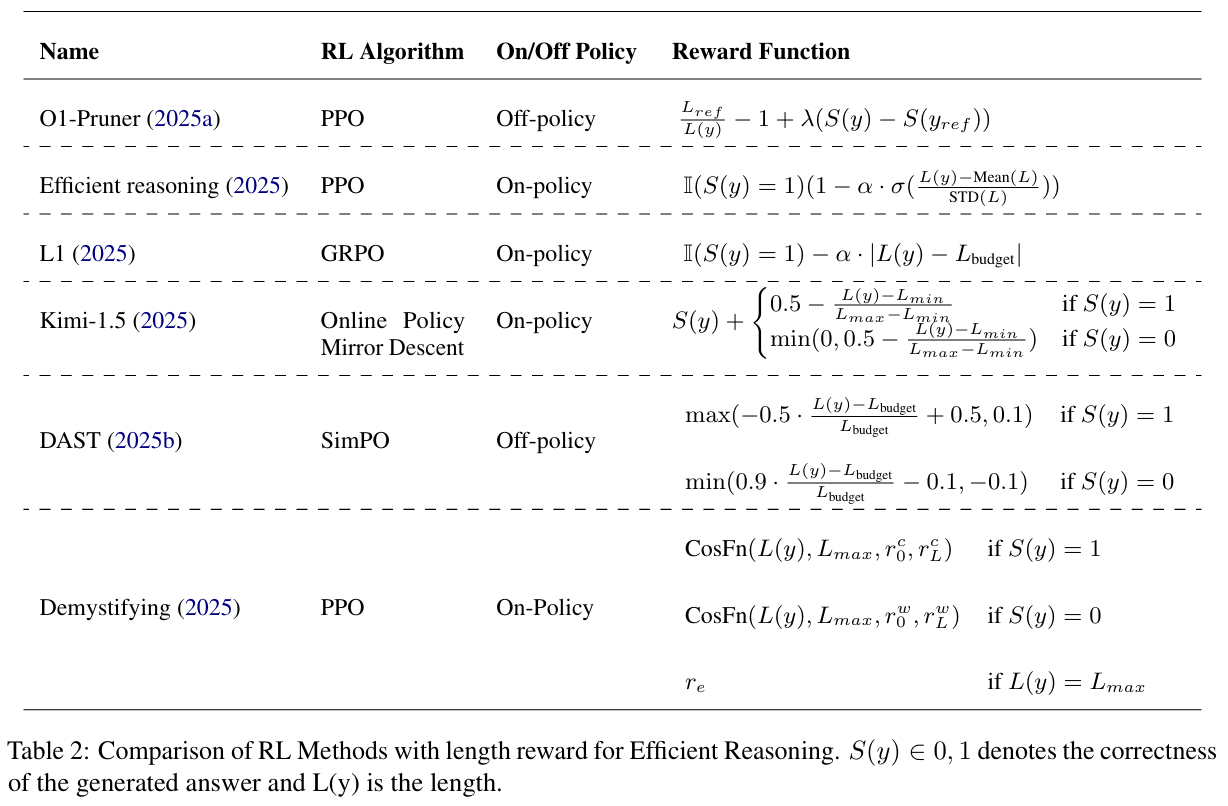
(1)具有长度奖励
最自然的方法,基于规则构建长度奖励。目前已有的工作是,制定任务难度的自适应奖励、基于预算的标准化奖励。
(2)高效RL,无长度奖励
无需明确长度奖励,而是更好的RL框架,重新表述、平衡简洁、详细思维链等。
将优化问题表述为元强化学习,模型自然权衡因正确早期预测(exploitation)和因不确定性继续完善推理(exploration),平衡准确率和速度。
平衡偏好,定义为效用最大化问题。将响应定义为标准推理组和扩展推理组,优化组之间分布。以及,使用第一正确方案(FCS)和贪婪多样性解决方案(GDS)进行优化。
7、pre-train
在pre-train阶段进行改进的方法。目前比较热门的是subquadratic attention。
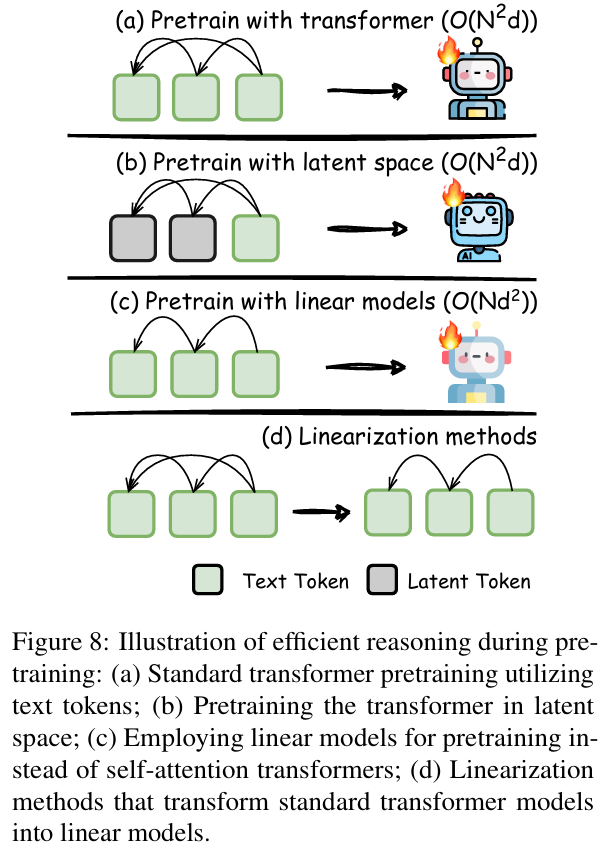
(1)使用latent space进行pre-train
基础的方法是添加special token,而现有的方法已经开始基于连续表征来研究了,例如BLT、LCM、CoCoMix、LTM。这些方法主要是构建隐式推理的捷径,未来研究是面对复杂多步骤推理任务,改进训练方法,确保广泛推理任务的一致性和准确性。
(2)subquadratic attention
CoT推理过程依赖于长上下文推理,使用subquadratic attention代替原本transformer中的self attention,从而降低序列计算成本。
- 线性序列建模。相关的方法有right-product kernel trick、lightning attention、LSAP等。其他模块创新有RetNet、GLA、GSA、TTT等。较新的是SSM,相关工作有Mamba2、线性RNN、HGRN等。
- 稀疏注意力。管理长序列和减轻self attention二次复杂度。滑动窗口将q限制为预先确定的上下文,例如StreamingLLM、DuoAttention、Longformer。动态分层稀疏策略,将粗粒度token压缩将细粒度token选择。
(3)线性化
将LLM转换为线性递归结构。如: 门控线性循环模型、Mamba、LightTransfer等。
三、总结
这篇论文比较详细的说明了现有提高LRM推理效率的方法。对于资源一般研究者而言,关注点可能就是高效推理和RL的部分。SFT更加偏向于数据方面的工程,更加关注数据迭代下LLM更好的实验表现。而pre-train大概只能在小LLM上进行尝试,由于我不喜欢这种很多黑盒上从实验,我仅仅学习了相关的算法。
高效推理直接相关的是agent,本文中很多相关的考虑常见也是agent,这个真的太重要了,对于MAS影响很大。而RL作为较新的改进模型推理模型的热门方法,预计接下来一年会有更多的新工作出来。
一个感悟是,读综述真的要找有github仓库维护相关论文列表的,文章质量真的会高很多。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









