






一 基础知识
来源
【课程链接】
https://datawhalechina.github.io/thorough-pytorch/index.html
1 张量
1.1基础知识
- 张量是基于向量和矩阵的推广 >>>> 标量视为零阶张量,矢量可以视为一阶张量,矩阵就是二阶张量:
| 张量维度 | 代表含义 |
|---|---|
| 0维张量 | 标量(数字) |
| 1维张量 | 向量 |
| 2维张量 | 矩阵 |
| 3维张量 | 时间序列数据 |
3维 = 时间序列
4维 = 图像
5维 = 视频
- PyTorch中,
torch.Tensor是存储和变换数据的主要工具 >>> 与NumPy的多维数组类似
1.2 创建tensor
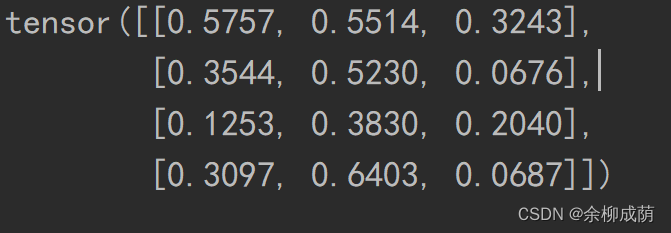
torch.rand()创建一个4*3随机矩阵
import torch
x = torch.rand(4, 3)
print(x)
torch.zeros()构造零矩阵, dtype设置数据类型为 long
torch.zeros(4, 3, dtype=torch.long)

torch.tensor>>> 使用数据,构造张量
torch.tensor([5.5, 3])
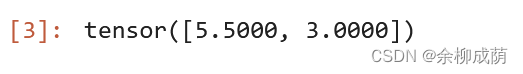
torch.randn_like据已有张量, 创建tensor
#创建4*3 全1张量
x = torch.ones(4, 3, dtype=torch.double)
x

#获取已有张量维度, 创建同size的torch
x = torch.randn_like(x, dtype=torch.float)
x

1.3 加法、索引、广播
- 加法三种表示方法
import torch
# 方式1
y = torch.rand(4, 3)
print(x + y)
# 方式2
print(torch.add(x, y))
# 方式3 in-place,原值修改
y.add_(x)
print(y)
-
索引与numpy类似 >>> 索引出来的结果与原数据共享内存,修改一个,另一个会跟着修改。如果不想修改,可以考虑使用copy()等方法
-
维度变换 >>>
torch.view()以及torch.reshape()
torch.view()返回的新tensor与源tensor共享内存
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8) # -1是指这一维的维数由其他维度决定
print(x.size(), y.size(), z.size())
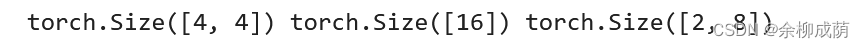
torch.reshape()使原始张量和变换后的张量互相不影响
- 当对两个形状不同的 Tensor 按元素运算时,可能会触发广播(broadcasting)机制:先适当复制元素使这两个 Tensor 形状相同后再按元素运算。
x = torch.arange(1, 3).view(1, 2)
print(x)
y = torch.arange(1, 4).view(3, 1)
print(y)
print(x + y)

1.4 自动求导
torch.Tensor 的属性 .requires_grad 设为 True (默认为False)>>>>
它将会追踪对于该张量的所有操作>>>
当完成计算后可以通过调用 .backward()计算所有的梯度>>>
这个张量的所有梯度将会自动累加到.grad属性。
- 还有一个类对于
autograd的实现非常重要:Function。Tensor和Function互相连接生成了一个无环图 (acyclic graph),它编码了完整的计算历史。每个张量都有一个.grad_fn属性,该属性引用了创建Tensor自身的Function(除非这个张量是用户手动创建的,即这个张量的grad_fn是None)。下面给出的例子中,张量由用户手动创建,因此grad_fn返回结果是None。
x = torch.randn(3,3,requires_grad=True)
print(x.grad_fn)
None
#创建一个张量并设置requires_grad=True用来追踪其计算历史
x = torch.ones(2, 2, requires_grad=True)
x

- 计算后
x**2
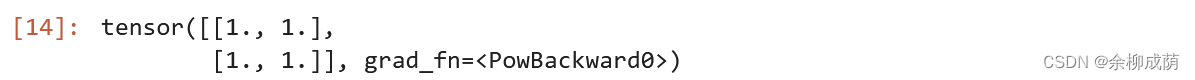
1.5 梯度
torch.autograd这个包就是用来计算一些雅可比矩阵的乘积的grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。
x = torch.ones(2, 2, requires_grad=True)
out2 = x.sum()
out2.backward()
print(x.grad)

out3 = x.sum()
out3.backward()
print(x.grad)

- 清零
out4 = x.sum()
x.grad.data.zero_()
out4.backward()
print(x.grad)

1.6 并行计算
- 数据量大或者提升计算速度的场景,这时就需要用到并行计算
- PyTorch使用 CUDA表示要开始要求我们的模型或者数据开始使用GPU了。
在编写程序中,当我们使用了 .cuda() 时,其功能是让我们的模型或者数据从CPU迁移到GPU(0)当中,通过GPU开始计算。















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









