






哪些用户需要迁移
原社区版用户
- 社区版不再更新
Cloudera(Cloudera 和Hortonworks 合并后)所有产品不再提供社区版,用户无法获取新的功能。
- 社区版不再免费
2021年1月31日开始,所有Cloudera软件都需要有效的订阅,且订阅费昂贵(50个节点,一年订阅费50万美元)。
原企业版用户
- 企业版不再更新
Cloudera 和Hortonworks 合并后推出了新一代大数据平台 CDP,CDH 6和HDP 3将是CDH和HDP的 后企业版本,用户无法继续获取新的功能和性能提升。
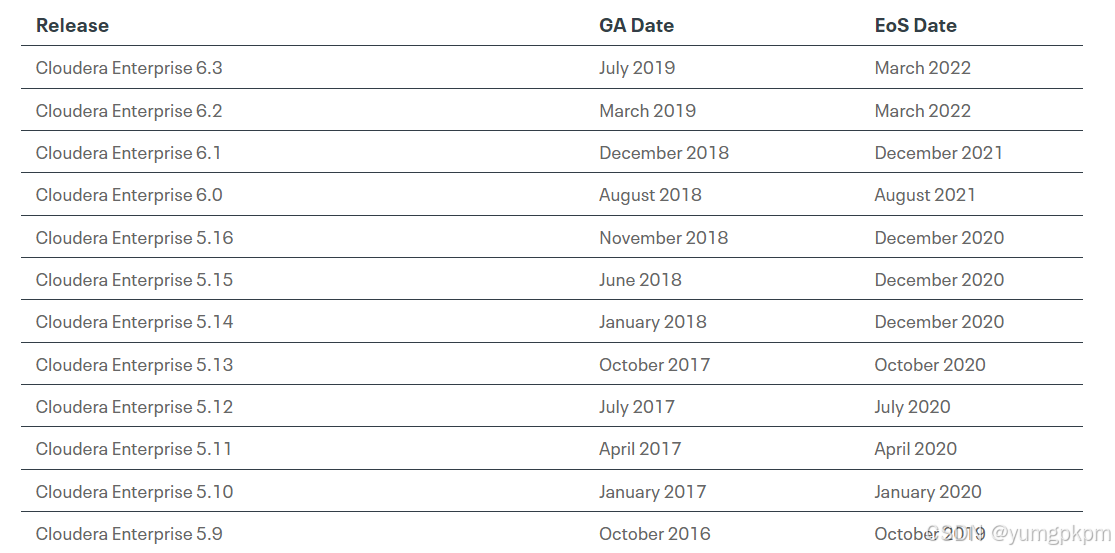
- 企业版不再服务
至2022年3月份,CDH/HDP全部EoS,用户没办法获取售后支持:
邮箱:dong@caimp.cn
迁移方向
方向一:CDP
CDP是 Cloudera 和Hortonworks 合并后发布的新产品,融合原来CDH和HDP能力并增加了一些新功能和BugFix,支持云部署等能力。
虽然CDP提供了一些新能力,也将继续更新并提供支持,但外国的软件无法适配国产软硬件生态(国产芯片、操作系统、服务器、中间件),技术方向不能自主可控,许可证也受外国法律限制,近期俄罗斯事件将这方面风险彻底暴露:
- Oracle宣布暂停在俄业务
3月3日,Oracle发推文称:“为了Oracle在全球各地的150000名员工的利益,为了支持乌克兰民选政府和乌克兰人民,Oracle公司已经暂停了在俄罗斯联邦的所有业务。
- 众多科技公司断供俄罗斯
- 谷歌宣布 Google Pay 在俄罗斯无限期暂停使用;
- 苹果公司除了宣布在俄罗斯停用 Apple Pay 以外,也在俄罗斯境内停止所有产品的销售
- 英特尔、戴尔、AMD 宣布向俄罗斯断供芯片
- ……
- 下一个或是GitHub?
外媒消息称,全球第一代代码托管平台GitHub 正在考虑限制俄罗斯开发人员使用开源软件。尽管此类软件的使用是免费的,但它的许可协议仍然存在诸多限制,包括禁止受制裁的国家使用原本对公众免费开放的代码。
方向二:国内封装的Hadoop商业版
对开源组件进行封装,安装部署运维方面有一些增强。
但是不可避免的,封装开源组件始终是受制于国外法律与国际形势,风险与方向一迁移到CDP相当。
同时,对开源组件进行封装的厂商无法获取 新的源代码。另外,很多人认为有源代码就可以自主可控,实际代码只是一个技术的载体,仅仅拥有源代码并不代表拥有核心技术,数千万行代码里扫清有意无意的漏洞根本不现实,拥抱开源的同时也一定拥抱了风险。
随着美国公司Cloudera不再更新社区版,这一类产品将无法获得能力更新,除非也升级到CDP,完全走向方向一。
方向三:国内自主研发大数据产品CMP
Cloud Data AI Management Platform(CMP v7)是北京建研凯信自主研发的企业级一站式多模型大数据基础平台,采用领先的多模型技术架构,8种存储引擎支持10种数据模型,成套的工具组件让系统的安装部署、扩容升级、安全防卫、风险告警、权限管理等工作变得更便捷。在技术领先性、性能、易用性、安全性、售后服务等诸多方面具有优势。同时,国产自主研发的CMP对国产化生态具有高度兼容性,满足信创验收要求。
迁移到不同平台后获得的能力
迁移到国产自主研发大数据产品CMP
- 如果你关注功能
CMP多模架构,支持关系表、文本、时空地理、图数据、文档、时序等在内的10种数据模型;离线数据批处理、高并发的在线数据服务、数据集市、数据仓库、数据湖、图存储分析、空间数据存储、实时数据处理、数据中台、数据治理等各类大数据业务场景一站解决。
- 如果你关注性能
CMP自研高性能分布式计算和存储引擎,整体性能是CDP 5~25倍。
- 如果你关注开发
CMP完整支持SQL2003标准,支持PLSQL存储过程,兼容Oracle、DB2、Teradata等方言,无需每个场景一套接口。
- 如果你关注运维
CMP提供开箱即用的可视化运维监控、安全管控工具,容器技术带来好的的安装、升级、补丁体验。
- 如果你关注售后
CMP研发与支持团队认证的大数据工程师,专业性更强,售后无忧。
- 如果你关注架构
CMP提供统一SQL引擎、统一计算引擎、统一分布式存储管理、统一资源调度,统一内联架构高效搞定湖仓集一体、HTAP等复杂场景,无需平凑组件散装架构。
- 如果你关注安全
CMP提供的容器隔离、灾备、访问控制、联邦学习、隐私保护、可信计算等技术保障网络层、加固层、治理层、流通层全方位数据安全。
- 如果你关注国产化
CMP完全自研,通过工信部代码自主研发率扫描测试。同时CMP完成了与主流信创生态厂商的适配互认工作,满足信创验收要求。
| CDH/HDP迁移到CMP将获得的能力 | |
| 数据库能力 | 支持SQL2003标准,兼容Oracle、DB2、Teradata等方言,支持PLSQL存储过程; 分布式事务支持,且锁粒度细,性能优于Hive 3事务; Inceptor on 自研内存引擎,比Hive on Tez ETL性能更高; 改进的物理计划,支持物化视图,提供向量化执行和CodeGen能力; 提供一体多模的SQL编译层和执行层,支持多模态数据的联邦计算和存储。 |
| 多模型支持能力 | 关系型分析引擎Inceptor,提供PB级海量数据的高性能分析服务,同时支持完整的SQL标准语法,兼容Oracle、IBM DB2、Teradata方言,兼容Oracle和DB2的存储过程,可以平滑迁移应用;支持分布式事务处理,保障数据强一致性。 图数据库StellarDB,支持千亿级点与万亿级边的存储以及PB数量级属性信息的存储,可以实现毫秒级延时点、边和属性的检索请求; 宽表数据库Hyperbase,能够实现对TB到PB级别数据量的毫秒级响应延时、百万级高并发检索的NoSQL宽表数据库; 搜索引擎Scope,可以在毫秒时间内根据客户提供的搜索关键字对PB数量级的文档数据进行全文检索的分布式搜索引擎; 时序数据库Timelyre,单节点可以每秒处理数百万条带有时间特征数据记录,并支持每秒数百次的查询; 时空数据库Spacture,兼容常见开源和商业GIS地理信息软件,提供高效的时空索引算法、空间拓扑几何算法和遥感影像存取能力; 键值数据库KeyByte,支持单节点数十万次/秒的键值检索,可以作为在线业务系统的热数据缓存,或用于优化复杂系统的IO性能; 事件存储库Event Store,支持事件的写入,持久化并提供容错能力;支持将数据按照时间顺序和指定条件对数据使用方进行多次重放,并可以保证数据有序送达不丢失。 |
| 实时计算 | 支持使用SQL语言开发流任务,SQL语法继承自统一的编译器,遵循ANSI92、99及2003 OLAP扩展,支持存储过程; 内建流式规则引擎模块,无需对接第三方规则引擎,实现实时指标计算与规则研判; 支持流式机器学习算法,可以实现实时聚类分类等预测性分析应用; 继承统一计算引擎能力,支持实时数据、历史数据与其他模型数据的关联计算。 |
| 国产生态 | 主流信创生态厂商的适配兼容,支持国产CPU、国产OS、国产服务器、国产中间件,支持X86与国产硬件混部,包括:华为&飞腾ARM架构、龙芯MIPS架构、申威Alpha架构等国产服务器,中标麒麟、银河麒麟、UOS等国产操作系统,飞腾、鲲鹏等国产芯片; 自主研发,完成了与主流信创生态厂商的适配互认,满足信创验收要求。 |
| 安全 | 数据分类分级能力,提供细粒度的数据安全管理; 数据传输加密引入SM4等国密算法; 支持数据脱密加密,审计和溯源分析; 提供隐私计算、联邦学习的多方加密计算能力。 |
| 存储 | TDFS使用Raft保证数据一致性,写性能比HDFS提高一倍; TDFS解决小文件爆炸和Block Report带来的元数据管理等问题,可扩展性是HDFS的数十倍; TDFS支持对象存储,并发度更高,操作更快; 相比于Kudu性能更好,可快速更改/更新/合并数据。 |
| 容灾能力 | 支持跨数据中心数据热备/温备/冷备三种备份模式; 支持数据块级别全量/增量同步,同步效率高代价低; 支持自动感知数据或元数据变化,自动同步数据; 数据备份支持对象级别CPU和带宽控制。 |
| 运维管理 | 提供CMP所有子产品的安装、配置、管理和监控能力;支持多种架构的国产芯片和操作系统,支持混合异构部署;容器化技术,提供好的的安装部署升级体验; 提供CMP产品用户认证、权限管理、资源配额管理等;支持细粒度的RBAC权限角色控制,增强认证和SSL、TSL等加密设置; 提供CMP各个子产品监控仪表盘、告警通知、日志生命周期管理、日志检索等开箱即用的可视化运维能力; 提供了CMP平台用户的数据操作的存储和审计功能,危险操作告警,防止潜在的数据泄露操作。 |
| 售后服务 | 原厂研发人员售后服务,提供SLA保障; 源代码自主研发,保障cve漏洞等问题快速修复。 |
迁移到CDP
| CDH迁移到CDP将获得的新能力对比 | ||
| 模块 | CDP新能力 | CMP相关能力对比 |
| 策略和授权 | 动态行过滤和动态列掩码 基于属性的访问控制 SparkSQL细粒度的访问控制 Sentry到Ranger的迁移工具 | CMP支持完整的行、列、基于属性的访问控制,并为sql提供了多种调度策略和访问权限控制,效果更好,同时task级别的调度和重试机制更加精细。 |
| 数据治理 | 元数据、血缘和监管链,高级数据发现和业务词汇表 Navigator到Atlas的迁移,提高了性能和可伸缩性 | CMP产品具备完整的数据开发和数据治理功能,包括数据库在线开发与协同,任务调度,数据整合,数据安全防护,元数据管理,数据资产目录,数据服务开发管理,标签管理,数据商城功能,更早更全。 |
| 流处理 | 支持与HDFS、AWS S3和Kafka流的Kafka Connect 对Kafka集群的集群管理和复制支持 使用Cruise Control在集群之间存储和访问架构以及重新平衡集群 | CMP支持StreamSQL技术,支持kafka Connect以及流表的Adhoc查询,流入库和流计算吞吐更高、延时更低。 |
| 运营数据库 | 支持具有完成ACID事务功能的标准SQL 二级索引 星型Schema支持 基于表的视图 | CMP已经支持完整的ACID分布式事务、二级索引、星型Schema、表的视图等数据库功能。 支持完整SQL2003标准,支持PLSQL存储过程,兼容Oracle、DB2、Teradata等方言。 |
| 数据仓库 | Hive-on-Tez提供更好的ETL性能 ACID事务,ANSI 2016 SQL支持,主要性能改进 查询结果缓存 物化视图 改进的CBO,矢量化覆盖率 | CMP含了分布式分析性数据库ArgoDB,实现了结果缓存、物化视图、CBO改进,向量化计算引擎等,TPCDS1TB测试相比于hive on Tez平均有5性能提升。 |
| 存储 | Apache Ozone提供HDFS 30倍的可扩展性,支持100亿个对象 S3原生支持 与Kafka和Nifi的集成 | CMP提供HDFS 50倍的可拓展性,支持对象存储,支持500亿个对象。 |
| 安全 | 使用Knox的基于网关的SSO 支持Ranger KMS-KeyTrutee集成 支持新的Key HSM版本 | CMP已经支持SSO和KMS的能力。 |
迁移方向的对比分析
以下分别从兼容性、技术领先性、性能、易用性、稳定性、灾备与可靠性、安全性、自主可控、国产生态、解决方案、售后服务等多方面对比各迁移方向,供用户参考。
兼容性
兼容性,直接决定迁移成本。很多客户认为CDP是CDH/HDP的高版本,应可以平滑升级,基于开源整合的产品,也可以平滑升级,而CMP是国内自主研发的大数据产品,兼容性不好,升级成本高,其实不然。
- CDP
- CDH 5升级CDP有严重组件版本兼容性问题, 包括 sentry 换成ranger,Hive2 升级到 Hive3,升级对组件的兼容性影响大;
- 例如:某客户CDH5升级到CDP的升级时间长达数月之久。
- 开源封装产品
- 基础存储和计算组件同样有兼容性问题;
- CDH安全、运维管理等不开源组件和功能无法升级,且目前没有很好解决方案。
- CMP
- CMP基础存储和计算组件兼容CDH/HDP,迁移成本低;
- CMP提供迁移工具,数据一键迁移;
- 大量迁移成功案例,不存在迁移风险。
在国产生态方面,CMP已经有非常多落地案例,并且性能提升明显。在不同指令集的CPU架构均表现出优异的性能,如ARM(鲲鹏)和X86(海光)在CPU密集型计算和IO密集型计算上性能提升显著。
| 对比维度 | 使用国产服务器性能提升说明 |
| 批处理 | 平均Tpcds测试集性能提升15%; |
| 流计算 | 单流Filter、窗口聚合、多流Join等场景性能提升20%; |
| 高并发读写 | 高并发读写场景下,综合写性能提升10-15%,读性能提升15%-20%; |
| 综合检索 | 吞吐量提升20%-30% |
解决方案
CDP/开源封装产品,每个场景需要一个组件独立交付,开发语言和接口基本完全不同,客户新业务开发、业务需求变更成本很高。
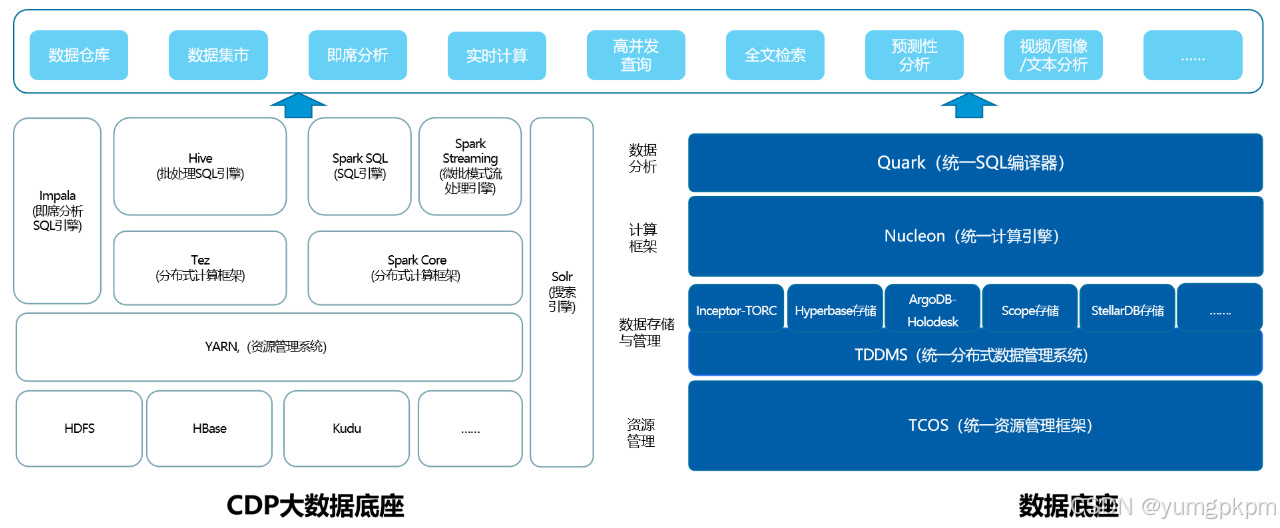
| CDP/开源封封装产品装产品 | CMP封装产品 | ||
| 架构 | 流转链路与数据一致性 | •链路冗长,使用散装架构,开发运维成本高,数据需要导入导出,数据一致性难以保证。 | •链路简单,统一架构,一体化建设,开发运维成本低。统一的计算引擎,避免数据导入导出。统一的分布式存储管理系统:有效保障数据一致性 |
| 跨库关联分析 | •跨库关联的复杂分析场景需要数据的导入导出,过程繁琐,分析延迟高。 | •通过统一SQL编译器、统一计算引擎,统一元数据的湖仓一体能力即可支持Inceptor, ArgoDB,Scope等跨库关联复杂分析场景,简单易用,时效性高。 | |
| 国产信创 | 兼容性 | •CDH/HDP/CDP以及开源相关组件没有对国产生态做过适配,兼容性差 | •适配华为&飞腾ARM架构、龙芯MIPS架构、神威Alpha架构 •适配中标麒麟、银河麒麟、UOS等 •支持X86与ARM架构混合部署 •与符合信创的国产软硬件兼容性好,且拿到相关互认证书 •满足信创验收要求 |
| 数据湖能力 | 一体多模数据支持 | •Hive、Impala等CDP组件在构建数据湖应用的时候没有统一入口,对于不同类型的数据需要开发不同的作业,开发复杂。 | •在SQL编译器层支持多模数据的存储,对外提供统一SQL编程模型,构建数据湖应用方便快速。 |
| 存储能力 | •HDFS分布式文件系统在数据湖应用中存在技术上的局限性,写入性能差,且因为小文件和Block Report等问题不能管理数据湖海量文件 | •自研的TDFS分布式文件系统使用更先进的元数据管理架构,支持的文件数能够达到百亿级别。 使用分布式一致性协议算法,提高写入数据可靠性的同时写入性能也得到了提升 | |
| 数据治理 | •Atlas等开源的数据血缘、数据治理工具在治理功能和粒度上支持有限,且不支持数据标准、数据质量、数据发布等维度的治理能力 | •自研的TDS产品在数据治理上的功能得到了增强,支持实时更新血缘、字段级别的血缘分析 •提供数据质量、数据标准、数据商城、数据发布等模块,加强对数据湖中数据的治理能力 | |
| 数据仓库能力 | SQL编译技术 | •Hive、SparkSQL、ImpalaSQL等使SQL无统一规范,对ANSI SQL标准和传统关系型数据库方言支持度较低。企业业务迁移成本高 •支持的存储过程编译技术主要是HPL兼容的语法比较有限 | •支持SQL 2003标准与存储过程,降低开发难度;兼容Teradata,Oracle,DB2等方言,方便业务平滑迁移,降低迁移成本 •提供存储过程支持,降低开发大型复杂数据业务系统的技术门槛 |
| SQL优化技术 | •Hive、Impala等基于规则和代价的优化器不够丰富,不能满足不同场景的使用 | •改进了代价CBO优化器,丰富了RBO的优化规则,适用场景更广泛 •实现多模优化器,针对不同数据模型和使用场景能够自动适配优化算法 | |
| 分布式一致性 | •HDFS、ElasticSearch等开源产品使用多机器间数据复制方式,可靠性差,且写入性能较差 | •TDFS、ArgoDB、Scope等产品广泛使用分布式一致性协议保障数据的一致性,提高了数据可靠性、系统可用性以及扩展性 | |
| 分布式事务 | •Hive、Spark等在2018年之后才开始陆续支持事务能力,但是隔离级别支持一般,且事务并发不高 | •Inceptor在2015年就已经支持分布式事务,且隔离级别支持丰富,支持乐观和悲观的并发控制策略,支持全局一致性快照,能够快速回滚数据,具备技术领先性 | |
| 性能指标 | •Hive性能弱,难以满足企业高性能要求 | •Inceptor 全球首个通过TPCDS测试,TPC-DS查询性能是Hive的7X~25X | |
| 数据集市能力 | 索引支持 | •Impala不支持二级索引,难以满足企业灵活查询性能要求 | •支持二级索引、全文索引等多种索引类型,提高查询速度,满足企业灵活查询性能要求 |
| OLAP高并发 | •OLAP并发度低,水平扩展能力有限,难以满足OLAP高并发需求 | •支持1000+用户同时在线分析,且并发能力可随节点数量增加 | |
| 服务开放能力 | •集群无法对大规模业务人员开放其查询分析服务能力 | •数据服务对外开放,赋能业务人员自助式查询分析。 | |
| 性能指标 | •Impala TPC-H OLAP查询分析性能弱。 | •ArgoDB TDP-H查询分析性能是Impala的2X~6X | |
| 实时计算能力 | 实时数据入库分析能力 | •延迟高,难以满足企业复杂场景的落地即分析场景 | •ArgoDB与Slipstream无缝衔接,落地即分析,秒级响应 |
| 实时流SQL开发便捷性 | •Flink 以API开发为主,SQL支持有限,对企业的实时流开发门槛要求高,运维复杂 | •基于SQL开发流任务,支持通过SQL方式实现复杂事件处理,实现复杂业务逻辑。SQL代码可移植性高,降低企业开发运维门槛 | |
| 全文检索能力 | 功能/性能差异 | •Solr和ES只支持实时写入,不支持批量加载,入库过程中需要生成索引文件,资源开销大,入库性能不高 | •Scope支持大批量离线数据加载,并且多副本下,只会生成一份索引文件,性能更好 |
| 单机容量 | •ES硬件资源利用率低,单节点单实例存储约10TB | •Scope为企业节省IT硬件成本投入,单节点单实例存储约50TB | |
| 故障恢复时间 | •ES故障恢复时间久,恢复时间为小时/天级别 | •Scope恢复时间短,保证业务的连续性分钟级别(<10min) | |
| 高并发读写 | 跨库分析 | •Phoenix on Hbase的方案在异构数据分析上存在缺陷,包括流表与Hbase关联分析等支持不够 | •Inceptor中独创的HyperDrive表和GLKJoin技术,支持OLAP和实时数仓场景下,跨库的关联分析 |
| 图计算和分析能力 | 数据联邦能力 | •Neo4j不支持跨数据库查询,不支持异构模型数据关联查询 | •支持多个图之间的跨数据库查询能力,并且与Inceptor中结构化数据可以关联查询 |
| 扩展性和可靠性 | •Neo4j 还是集中式系统,不支持分布式图算法,扩展能力差 | •可扩展性强,数据多副本分布式存储,支持分布式图算法 | |
| 时空轨迹分析 | 轨迹分析能力 | •PostGIS等开源组件暂未提供相关轨迹数据的分析文档 | •Spacture支持原生轨迹数据类型,融合空间、时间、属性等多维数据,提供特定的存储格式 •支持常见的轨迹处理算法,兼容OGC Moving Features标准分析函数 |
| 时空索引 | •PostGIS等开源组件暂未提供相关时空索引的分析文档 | •Spacture提供多种时空索引,能够加速空间查询和时空查询 | |
| 时序数据分析 | 标准SQL支持程度 | •使用Hbase和Phoenix组件结合做时序数据的分析,只支持一种数据类型,且不支持自定义函数 | •TimeLyre支持标准的SQL查询语言,且支持多达15种数据类型 |
| 数据处理分析能力 | •Phoenix和InfluxDB对分析函数的支持不够,且对数据关联分析能力弱 | •TimeLyre支持四种数据关联方式,且支持自定义函数 | |
售后服务
CMP的产品提供方是国内厂商,具有非常强大的研发与技术支持与服务能力,可以快速响应客户定制化需求,提供强大的原厂售后服务保障能力。
CDP的产品提供方Cloudera依靠国内代理商提供销售并提供实施、运维服务;Cloudera在国内主要是运维人员,没有原厂技术研发人员,很难保障SLA。由于支持不到位,很多国内CDH企业版客户已经购买了我方技术人员提供技术保障。

















 2312
2312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









