







【案例名称】药物选择决策支持
【案例类型】数据挖掘
【所属行业】医药卫生
【案例版本】1.0
【完成日期】2003年7月2日
【应用软件】Clementine 7.2英文版
【遵循标准】CRISP-DM
【案例数据来源】Clementine 7.2 Demo自带数据
【案例应用模型】神经网络、C5.0、Logistic回归
【案例制作】钟云飞
【案例用途】通过案例实现以下目的:
1、 CRISP-DM的标准流程及在解决具体业务问题过程中的应用;
2、 理解如何提高数据挖掘模型的效果;
3、 理解结果发布的几种方式。
【案例简要描述】
针对病人的病情和体质情况,医生往往需要采用不同的用药。本案例通过数据挖掘,对医院积累的历史数据进行分析,确定病人选择何种药物对治疗疾病最为有效。并开发了相应的药物选择决策支持系统的应用系统。
案例正文
【背景介绍】
XX病是一种常见的疾病,目前有5种药物可以对其治疗,分别是——A、B、C、X、Y。不同的药物对病人有不同的疗效。历史上,医院往往根据医生的经验去判断针对特定的病人应该选择何种药物。但是由于新医生的加入,这种仅仅靠经验判断的做法造成了很多误诊。
该医院有比较完善的病例留存,为了改变以上局面,也为了更好的利用历史数据和专家经验,该医院决定通过数据挖掘技术对历史数据进行分析研究,并期望能够建立一套有效的药物选择决策支持系统。
【数据说明】
目前有历史病例数据1200条,咨询专家意见,我们提取了其中影响选择药物的若干个变量记入数据库,它们是年龄、性别、血压、胆固醇含量、钠含量、钾含量,最后一个变量是我们需要确定的选择药物,数据存贮在Microsoft Access数据库中。
【数据挖掘过程】
1、 商业理解
在这个阶段我们主要需要描述清楚业务问题,并对我们手头拥有的资源有一个非常清晰的认识。在这个案例中,我们需要根据病人的个人情况和身体特征来确定何种药物对它最为合适。由于问题比较简单,我们的商业理解也比较简单。
2、 数据理解
数据理解阶段用来完成对数据质量、数据之间的基本关系进行探索性分析等项工作。在这个阶段,我们对历史数据中的1200条数据进行图形观察,初步观察病人的情况和身体特征是否与选择药物关系明显。数据流图见图1。
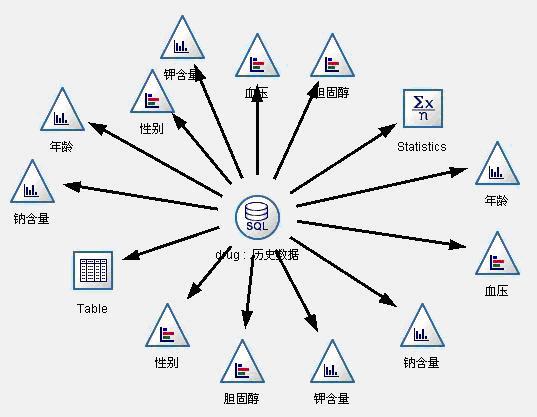
图1:数据理解
下面是产生的一些典型图形,图形解释略。

图2:对数据的初步探索性分析
3、 数据准备
数据准备主要完成对不同的数据源的整合,并且对数据进行适当的变换,使之适合数据挖掘的需要,对于特定的模型,需要把原始数据集合拆分成训练数据集和检验数据集也在这个步骤中完成。
对于本案例来说,由于数据源只有一个,并且数据格式也相对单一简单,我们在数据准备中主要完成对原始数据集的拆分,从而用训练数据集建立模型,用检验数据集对模型的效果进行评估。
在Clementine中,对数据集的拆分,是通过引入一个中间变量来完成的。在本案例中,我们把全部1200条数据中的2/3左右(800左右)作为训练数据集,把1/3左右(400左右)作为检验数据集。我们引入了一个二分变量——拆分变量,这个二分变量对应1200条原始数据有2/3左右为“真”(T),1/3左右为“假”(F)。我们挑出那些拆分变量值取“真”(T)的记录作为训练数据集,那些拆分变量值取“假”(F)的记录作为检验数据集。实现该过程的数据流见图3。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 929
929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









