







numpy的基本操作
1.1 生成numpy数组
import numpy as np
#查看numpy函数的帮助信息
np.abs??
1.1.1 从已有数据中创建数组
import numpy as np
lst1 = [3.14, 2.17, 0, 1, 2]
nd1 =np.array(lst1)
print(nd1)
# [3.14 2.17 0. 1. 2. ]
print(type(nd1))
[3.14 2.17 0. 1. 2. ]
<class 'numpy.ndarray'>
import numpy as np
lst2 = [[3.14, 2.17, 0, 1, 2], [1, 2, 3, 4, 5]]
nd2 =np.array(lst2)
print(nd2)
# [[3.14 2.17 0. 1. 2. ]
# [1. 2. 3. 4. 5. ]]
print(type(nd2))
[[3.14 2.17 0. 1. 2. ]
[1. 2. 3. 4. 5. ]]
<class 'numpy.ndarray'>
list = [[1,2,3,4],[1,6,9]]
nd = np.array(list)
print(nd)
print(type(nd))
[list([1, 2, 3, 4]) list([1, 6, 9])]
<class 'numpy.ndarray'>
可以看到利用list创建数组时,如果数组的长度不等长,则数组中的元素就是列表里元素的种类,即一个列表的数组
1.1.2 利用 random 模块生成数组
import numpy as np
nd3 =np.random.random([3, 3])
print(nd3)
print("nd3的形状为:",nd3.shape)
[[0.2825494 0.49026544 0.89050493]
[0.73615031 0.82211001 0.07713871]
[0.94375842 0.75488908 0.97321202]]
nd3的形状为: (3, 3)
import numpy as np
np.random.seed(123)
nd4 = np.random.randn(2,3)
print(nd4)
np.random.shuffle(nd4)
print("随机打乱后数据:")
print(nd4)
print(type(nd4))
[[-1.0856306 0.99734545 0.2829785 ]
[-1.50629471 -0.57860025 1.65143654]]
随机打乱后数据:
[[-1.50629471 -0.57860025 1.65143654]
[-1.0856306 0.99734545 0.2829785 ]]
<class 'numpy.ndarray'>
1.1.3 创建特定形状的多维数组
import numpy as np
# 生成全是 0 的 3x3 矩阵
nd5 =np.zeros([3, 3])
#生成与nd5形状一样的全0矩阵
#np.zeros_like(nd5)
# 生成全是 1 的 3x3 矩阵
nd6 = np.ones([3, 3])
# 生成 3 阶的单位矩阵
nd7 = np.eye(3)
# 生成 3 阶对角矩阵
nd8 = np.diag([1, 2, 3])
print(nd5)
print(nd6)
print(nd7)
print(nd8)
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
[[1 0 0]
[0 2 0]
[0 0 3]]
从文件载入数据创建数组
import numpy as np
nd9 =np.random.random([5, 5])
print(nd9)
np.savetxt(X=nd9, fname='./test1.txt')
nd10 = np.loadtxt('./test1.txt')
print(nd10)
[[0.02798196 0.17390652 0.15408224 0.07708648 0.8898657 ]
[0.7503787 0.69340324 0.51176338 0.46426806 0.56843069]
[0.30254945 0.49730879 0.68326291 0.91669867 0.10892895]
[0.49549179 0.23283593 0.43686066 0.75154299 0.48089213]
[0.79772841 0.28270293 0.43341824 0.00975735 0.34079598]]
[[0.02798196 0.17390652 0.15408224 0.07708648 0.8898657 ]
[0.7503787 0.69340324 0.51176338 0.46426806 0.56843069]
[0.30254945 0.49730879 0.68326291 0.91669867 0.10892895]
[0.49549179 0.23283593 0.43686066 0.75154299 0.48089213]
[0.79772841 0.28270293 0.43341824 0.00975735 0.34079598]]
1.1.4 利用 arange、linspace 函数生成数组
import numpy as np
print(np.arange(10))
# [0 1 2 3 4 5 6 7 8 9]
print(np.arange(0, 10))
# [0 1 2 3 4 5 6 7 8 9]
print(np.arange(1, 4, 0.5))
# [1. 1.5 2. 2.5 3. 3.5]
print(np.arange(9, -1, -1))
# [9 8 7 6 5 4 3 2 1 0]
print(np.linspace(0,10))
print(np.linspace(0,10,5))
#[ 0. 2.5 5. 7.5 10. ]
print(np.linspace(1,10,4))
#[ 1. 4. 7. 10.]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[1. 1.5 2. 2.5 3. 3.5]
[9 8 7 6 5 4 3 2 1 0]
[ 0. 0.20408163 0.40816327 0.6122449 0.81632653 1.02040816
1.2244898 1.42857143 1.63265306 1.83673469 2.04081633 2.24489796
2.44897959 2.65306122 2.85714286 3.06122449 3.26530612 3.46938776
3.67346939 3.87755102 4.08163265 4.28571429 4.48979592 4.69387755
4.89795918 5.10204082 5.30612245 5.51020408 5.71428571 5.91836735
6.12244898 6.32653061 6.53061224 6.73469388 6.93877551 7.14285714
7.34693878 7.55102041 7.75510204 7.95918367 8.16326531 8.36734694
8.57142857 8.7755102 8.97959184 9.18367347 9.3877551 9.59183673
9.79591837 10. ]
[ 0. 2.5 5. 7.5 10. ]
[ 1. 4. 7. 10.]
利用arange创建数组:arange(start,end,step),默认start=0,step=1)即只输入一个数n,则创建0,1,2,,,,n-1的数组
利用linspace创建数组 linspace(start,end,step) 至少输入两个参数,start开始的数,end为结束数,step为几步从start到end,步长为(end-sart)/(step-1)
1.2 获取元素
import numpy as np
np.random.seed(2019)
nd11 = np.random.random([10])
print("数组:",nd11)
#获取指定位置的数据,获取第4个元素
print("第四个元素:",nd11[3])
数组: [0.90348221 0.39308051 0.62396996 0.6378774 0.88049907 0.29917202
0.70219827 0.90320616 0.88138193 0.4057498 ]
第四个元素: 0.6378774010222266
#截取一段数据 下标3,4,5的位置
print(nd11[3:6],'\n')
#截取固定间隔数据
print(nd11[1:6:2])
[0.6378774 0.88049907 0.29917202]
[0.39308051 0.6378774 0.29917202]
#倒序取数
print(nd11[::-2])
[0.4057498 0.90320616 0.29917202 0.6378774 0.39308051]
#截取一个多维数组的一个区域内数据
nd12=np.arange(25).reshape([5,5])
print(nd12)
print(nd12[1:3,1:3])
#截取一个多维数组中,数值在一个值域之内的数据
print(nd12[(nd12>3)&(nd12<10)])
#截取多维数组中,指定的行,如读取第2,3行
print(nd12[[1,2]]) #或nd12[1:3,:]
##截取多维数组中,指定的列,如读取第2,3列
print(nd12[:,1:3])
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
[20 21 22 23 24]]
[[ 6 7]
[11 12]]
[4 5 6 7 8 9]
[[ 5 6 7 8 9]
[10 11 12 13 14]]
[[ 1 2]
[ 6 7]
[11 12]
[16 17]
[21 22]]
import numpy as np
from numpy import random as nr
a=np.arange(1,25,dtype=float)
c1=nr.choice(a,size=(3,4)) #size指定输出数组形状
c2=nr.choice(a,size=(3,4),replace=False) #replace缺省为True,即可重复抽取。
#下式中参数p指定每个元素对应的抽取概率,缺省为每个元素被抽取的概率相同。
c3=nr.choice(a,size=(3,4),p=a / np.sum(a))
print("随机可重复抽取")
print(c1)
print("随机但不重复抽取")
print(c2)
print("随机但按制度概率抽取")
print(c3)
随机可重复抽取
[[19. 6. 24. 22.]
[21. 17. 16. 2.]
[23. 15. 13. 11.]]
随机但不重复抽取
[[ 5. 14. 23. 15.]
[ 8. 24. 6. 18.]
[13. 10. 21. 11.]]
随机但按制度概率抽取
[[19. 21. 18. 11.]
[10. 21. 23. 19.]
[18. 19. 11. 20.]]
这里说一下按概率抽取
choice(a,size,p)a就是被抽取的数组,size是抽取成什么样子的数组,而p为a每一点数组被抽取的概率,如上面代码,即a每一点抽取的概率为每一点的值除以数组元素和,大数的概率比较大,所以可以看到第三个数组中大数比较多
1.3 Numpy的算术运算
1.3.1对应元素相乘
A = np.array([[1, 2], [-1, 4]])
B = np.array([[2, 0], [3, 4]])
A*B
array([[ 2, 0],
[-3, 16]])
#或另一种表示方法
np.multiply(A,B)
array([[ 2, 0],
[-3, 16]])
print(A*2.0)
print(A/2.0)
[[ 2. 4.]
[-2. 8.]]
[[ 0.5 1. ]
[-0.5 2. ]]
X=np.random.rand(2,3)
def softmoid(x):
return 1/(1+np.exp(-x))
def relu(x):
return np.maximum(0,x)
def softmax(x):
return np.exp(x)/np.sum(np.exp(x))
print("输入参数X的形状:",X.shape)
print("激活函数softmoid输出形状:",softmoid(X).shape)
print("激活函数relu输出形状:",relu(X).shape)
print("激活函数softmax输出形状:",softmax(X).shape)
输入参数X的形状: (2, 3)
激活函数softmoid输出形状: (2, 3)
激活函数relu输出形状: (2, 3)
激活函数softmax输出形状: (2, 3)
softmoid是一个用来解决二分类问题的激活函数
而softmax可以用来解决多分类,她的值在0 -1之间
relu是最简单的激活函数,非负值为本身,而负值则为零
在这列一下常见的激活函数
1.3.2 点积运算
X1=np.array([[1,2],[3,4]])
X2=np.array([[5,6,7],[8,9,10]])
X3=np.dot(X1,X2)
print(X3)
[[21 24 27]
[47 54 61]]
1.4 数组变形
1.4.1 更改数组的形状
import numpy as np
arr =np.arange(10)
print(arr)
# 将向量 arr 维度变换为2行5列
print(arr.reshape(2, 5))
# 指定维度时可以只指定行数或列数, 其他用 -1 代替
print(arr.reshape(5, -1))
print(arr.reshape(-1, 5))
[0 1 2 3 4 5 6 7 8 9]
[[0 1 2 3 4]
[5 6 7 8 9]]
[[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]
[[0 1 2 3 4]
[5 6 7 8 9]]
import numpy as np
arr =np.arange(10)
print(arr)
# 将向量 arr 维度变换为2行5列
arr.resize(2, 5)
print(arr)
[0 1 2 3 4 5 6 7 8 9]
[[0 1 2 3 4]
[5 6 7 8 9]]
import numpy as np
arr =np.arange(12).reshape(3,4)
# 向量 arr 为3行4列
print(arr)
# 将向量 arr 进行转置为4行3列
print(arr.T)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
import numpy as np
arr =np.arange(6).reshape(2, -1)
print(arr)
# 按照列优先,展平
print("按照列优先,展平")
print(arr.ravel('F'))
# 按照行优先,展平
print("按照行优先,展平")
print(arr.ravel())
[[0 1 2]
[3 4 5]]
按照列优先,展平
[0 3 1 4 2 5]
按照行优先,展平
[0 1 2 3 4 5]
import numpy as np
a =np.floor(10*np.random.random((3,4)))
print(a)
print(a.flatten())
[[3. 7. 7. 4.]
[3. 1. 0. 9.]
[4. 8. 2. 9.]]
[3. 7. 7. 4. 3. 1. 0. 9. 4. 8. 2. 9.]
可以看到这两个函数实现的功能一样,但我们在平时使用的时候flatten()更为合适.在使用过程中flatten()分配了新的内存,但ravel()返回的是一个数组的视图.视图是数组的引用(说引用不太恰当,因为原数组和ravel()返回后的数组的地址并不一样),在使用过程中应该注意避免在修改视图时影响原本的数组.这是什么意思咧,我们通过代码来具体解释:
做一个例子体会一下
import numpy as np
a = np.arange(6).reshape(2,3)
b = a.copy()
c = a.flatten()
d = b.ravel()
c[0] = 10
d[0] = 10
print(a)
print(b)
[[0 1 2]
[3 4 5]]
[[10 1 2]
[ 3 4 5]]
可以看到的是我们修改flatten展开后的数组,原数组不会改变,而修改ravel展开的数组,原来的数组也随之改变了
import numpy as np
arr =np.arange(3).reshape(3, 1)
print(arr.shape) #(3,1)
print(arr.squeeze().shape) #(3,)
arr1 =np.arange(6).reshape(3,1,2,1)
print(arr1.shape) #(3, 1, 2, 1)
print(arr1.squeeze().shape) #(3, 2)
(3, 1)
(3,)
(3, 1, 2, 1)
(3, 2)
arr = np.arange(6).reshape(3,2)
print(arr.squeeze().shape)
(3, 2)
squeeze()的作用就是把单维度去掉,即把维度为1的层去掉
import numpy as np
arr2 = np.arange(24).reshape(2,3,4)
print(arr2.shape) #(2, 3, 4)
print(arr2)
print(arr2.transpose(1,2,0).shape) #(3, 4, 2)
print(arr2.transpose(1,2,0))
(2, 3, 4)
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
(3, 4, 2)
[[[ 0 12]
[ 1 13]
[ 2 14]
[ 3 15]]
[[ 4 16]
[ 5 17]
[ 6 18]
[ 7 19]]
[[ 8 20]
[ 9 21]
[10 22]
[11 23]]]
transpose()可以理解成对坐标轴的转换,0,1,2即对应的维数的坐标轴,接用下图来说明一下
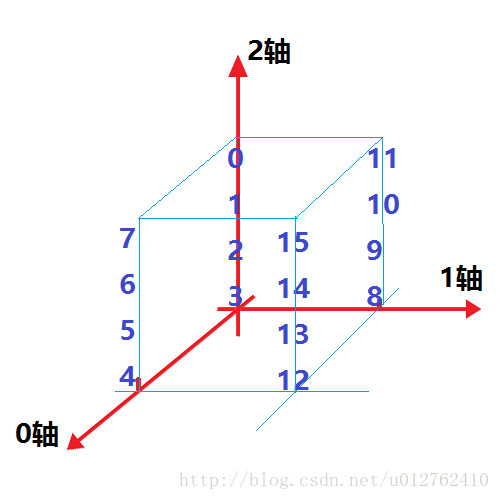
1.4.2 合并数组
import numpy as np
a =np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = np.append(a, b)
print(c)
[1 2 3 4 5 6]
import numpy as np
a =np.arange(4).reshape(2, 2)
b = np.arange(4).reshape(2, 2)
# 按行合并
c = np.append(a, b, axis=0)
print('按行合并后的结果')
print(c)
print('合并后数据维度', c.shape)
# 按列合并
d = np.append(a, b, axis=1)
print('按列合并后的结果')
print(d)
print('合并后数据维度', d.shape)
按行合并后的结果
[[0 1]
[2 3]
[0 1]
[2 3]]
合并后数据维度 (4, 2)
按列合并后的结果
[[0 1 0 1]
[2 3 2 3]]
合并后数据维度 (2, 4)
import numpy as np
a =np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
c = np.concatenate((a, b), axis=0)
print(c)
d = np.concatenate((a, b.T), axis=1)
print(d)
[[1 2]
[3 4]
[5 6]]
[[1 2 5]
[3 4 6]]
在concatenate()中axis即不动的轴,和上面所说的编号一样,即axis=0则是第一维度不变,进行拼接
import numpy as np
a =np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
print(np.stack((a, b), axis=0))
[[[1 2]
[3 4]]
[[5 6]
[7 8]]]
stack()中axis即拼接的维度,如果是0.则是整体的拼接,如果是则是数组中第一维堆叠,还是用上面的这个例子体会一下
import numpy as np
a =np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
print(np.stack((a, b), axis=1))
a =np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
print(np.stack((a, b), axis=2))
[[[1 2]
[5 6]]
[[3 4]
[7 8]]]
[[[1 5]
[2 6]]
[[3 7]
[4 8]]]
1.5 批量处理
import numpy as np
#生成10000个形状为2X3的矩阵
data_train = np.random.randn(10000,2,3)
#这是一个3维矩阵,第一个维度为样本数,后两个是数据形状
print(data_train.shape)
#(10000,2,3)
#打乱这10000条数据
np.random.shuffle(data_train)
#定义批量大小
batch_size=100
#进行批处理
for i in range(0,len(data_train),batch_size):
x_batch_sum=np.sum(data_train[i:i+batch_size])
print("第{}批次,该批次的数据之和:{}".format(i,x_batch_sum))
(10000, 2, 3)
第0批次,该批次的数据之和:-15.536990243960666
第100批次,该批次的数据之和:-21.985298462061966
第200批次,该批次的数据之和:-6.855888222836782
第300批次,该批次的数据之和:3.6083079848920177
第400批次,该批次的数据之和:-27.40567692288462
第500批次,该批次的数据之和:20.068354790364182
第600批次,该批次的数据之和:-13.839675656904632
第700批次,该批次的数据之和:-6.800114389801605
第800批次,该批次的数据之和:-1.9488451010894652
第900批次,该批次的数据之和:26.949204942120392
第1000批次,该批次的数据之和:-2.979366161898813
第1100批次,该批次的数据之和:5.312401696285585
第1200批次,该批次的数据之和:1.3890251621522829
第1300批次,该批次的数据之和:18.8278831675152
第1400批次,该批次的数据之和:-3.013130267630288
第1500批次,该批次的数据之和:9.19572394091026
第1600批次,该批次的数据之和:13.626914005186402
第1700批次,该批次的数据之和:0.37350417857288587
第1800批次,该批次的数据之和:36.73925921491799
第1900批次,该批次的数据之和:43.06712584126686
第2000批次,该批次的数据之和:23.638307136673426
第2100批次,该批次的数据之和:-4.75115381990968
第2200批次,该批次的数据之和:9.141910224904446
第2300批次,该批次的数据之和:-20.59408298159168
第2400批次,该批次的数据之和:-3.8542936637889635
第2500批次,该批次的数据之和:5.190831422077821
第2600批次,该批次的数据之和:0.1033080749731976
第2700批次,该批次的数据之和:28.514888340013478
第2800批次,该批次的数据之和:-4.250705282285964
第2900批次,该批次的数据之和:17.312294875434937
第3000批次,该批次的数据之和:0.5178363908270427
第3100批次,该批次的数据之和:-17.8790934227159
第3200批次,该批次的数据之和:-36.038534218631526
第3300批次,该批次的数据之和:-18.657461526119754
第3400批次,该批次的数据之和:8.96642791168259
第3500批次,该批次的数据之和:-16.8977731392328
第3600批次,该批次的数据之和:-39.054872436325724
第3700批次,该批次的数据之和:29.935644015116434
第3800批次,该批次的数据之和:30.81055271944732
第3900批次,该批次的数据之和:23.851982375149078
第4000批次,该批次的数据之和:-8.478701579368202
第4100批次,该批次的数据之和:40.85481653211612
第4200批次,该批次的数据之和:26.97601083992147
第4300批次,该批次的数据之和:17.21262555227974
第4400批次,该批次的数据之和:-50.016561720525274
第4500批次,该批次的数据之和:7.631903490893341
第4600批次,该批次的数据之和:25.243168771911083
第4700批次,该批次的数据之和:20.190514976100143
第4800批次,该批次的数据之和:-18.98702100615133
第4900批次,该批次的数据之和:34.36360805643004
第5000批次,该批次的数据之和:25.35375896132753
第5100批次,该批次的数据之和:43.424816168297085
第5200批次,该批次的数据之和:11.608363288030285
第5300批次,该批次的数据之和:21.68416206846238
第5400批次,该批次的数据之和:6.436689489116896
第5500批次,该批次的数据之和:23.006041325030225
第5600批次,该批次的数据之和:-4.249812203931111
第5700批次,该批次的数据之和:-17.871637787937228
第5800批次,该批次的数据之和:7.323918659671357
第5900批次,该批次的数据之和:4.309354533237804
第6000批次,该批次的数据之和:6.633432875784267
第6100批次,该批次的数据之和:26.218426870623425
第6200批次,该批次的数据之和:-26.91658590296429
第6300批次,该批次的数据之和:-3.1430761455881417
第6400批次,该批次的数据之和:-22.26223782650041
第6500批次,该批次的数据之和:30.91871933556546
第6600批次,该批次的数据之和:-31.898292758640856
第6700批次,该批次的数据之和:18.59988200903708
第6800批次,该批次的数据之和:-15.791132841722868
第6900批次,该批次的数据之和:3.238520833596276
第7000批次,该批次的数据之和:29.277501741691015
第7100批次,该批次的数据之和:12.522408724950385
第7200批次,该批次的数据之和:-0.04632167826632738
第7300批次,该批次的数据之和:-3.608568580957826
第7400批次,该批次的数据之和:-21.734163196503275
第7500批次,该批次的数据之和:-3.3394183779285953
第7600批次,该批次的数据之和:21.199090908362376
第7700批次,该批次的数据之和:0.7073121847016655
第7800批次,该批次的数据之和:-9.496965787226815
第7900批次,该批次的数据之和:-8.102498149343045
第8000批次,该批次的数据之和:-26.111801722552734
第8100批次,该批次的数据之和:-7.824020704193143
第8200批次,该批次的数据之和:14.258594184191388
第8300批次,该批次的数据之和:41.14559557118639
第8400批次,该批次的数据之和:-42.423226225171845
第8500批次,该批次的数据之和:11.13236358559491
第8600批次,该批次的数据之和:-1.2049458243346294
第8700批次,该批次的数据之和:5.3873446796294395
第8800批次,该批次的数据之和:24.155931755306803
第8900批次,该批次的数据之和:-12.25847649662716
第9000批次,该批次的数据之和:5.1467032230558605
第9100批次,该批次的数据之和:17.989358787209316
第9200批次,该批次的数据之和:17.246006465757496
第9300批次,该批次的数据之和:22.15262511102754
第9400批次,该批次的数据之和:-50.060940782199324
第9500批次,该批次的数据之和:-15.72888648024591
第9600批次,该批次的数据之和:-3.687025332996005
第9700批次,该批次的数据之和:27.34512912877116
第9800批次,该批次的数据之和:-21.107887951322212
第9900批次,该批次的数据之和:22.67782616351013
1.6 通用函数
import time
import math
import numpy as np
x = [i * 0.001 for i in np.arange(1000000)]
start = time.clock()
for i, t in enumerate(x):
x[i] = math.sin(t)
print ("math.sin:", time.clock() - start )
x = [i * 0.001 for i in np.arange(1000000)]
x = np.array(x)
start = time.clock()
np.sin(x)
print ("numpy.sin:", time.clock() - start )
math.sin: 0.2364024
numpy.sin: 0.010098599999999847
import time
import numpy as np
x1 = np.random.rand(1000000)
x2 = np.random.rand(1000000)
##使用循环计算向量点积
tic = time.process_time()
dot = 0
for i in range(len(x1)):
dot+= x1[i]*x2[i]
toc = time.process_time()
print ("dot = " + str(dot) + "\n for loop----- Computation time = " + str(1000*(toc - tic)) + "ms")
##使用numpy函数求点积
tic = time.process_time()
dot = 0
dot = np.dot(x1,x2)
toc = time.process_time()
print ("dot = " + str(dot) + "\n verctor version---- Computation time = " + str(1000*(toc - tic)) + "ms")
dot = 250060.8664321925
for loop----- Computation time = 375.0ms
dot = 250060.8664321958
verctor version---- Computation time = 0.0ms
1.7 广播机制
import numpy as np
A = np.arange(0, 40,10).reshape(4, 1)
B = np.arange(0, 3)
print(A)
print(B)
print("A矩阵的形状:{},B矩阵的形状:{}".format(A.shape,B.shape))
C=A+B
print("C矩阵的形状:{}".format(C.shape))
print(C)
[[ 0]
[10]
[20]
[30]]
[0 1 2]
A矩阵的形状:(4, 1),B矩阵的形状:(3,)
C矩阵的形状:(4, 3)
[[ 0 1 2]
[10 11 12]
[20 21 22]
[30 31 32]]
广播机制其实就是把两个矩阵reshape到一个同样的shape,然后进行加减
我的学习记录
githup连接https://github.com/yunlong-G/tensorflow_learn/blob/master/%E5%9F%BA%E6%9C%AC%E7%9A%84/numpy%E5%AD%A6%E4%B9%A0%E8%AE%B0%E5%BD%95.ipynb)















 1215
1215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









