







01 概述
随着可观测数据采集需求的不断推陈出新,多样化的数据输入输出选项、个性化的数据处理能力组合、以及高性能的数据处理吞吐能力已经成为顶流可观测数据采集器的必备条件。然而,由于历史原因,现有的 iLogtail 架构和采集配置结构已经无法继续满足上述需求,逐渐成为制约 iLogtail 继续向前快速演进的瓶颈:
▶︎ iLogtail 设计之初完全面向文件日志采集至日志服务的场景:
1)简单地将日志分为多种格式,每种格式的日志仅支持一种处理方式(如正则解析、Json 解析等);
2)功能实现与日志服务相关概念(如 Logstore 等)强绑定;基于此设计思想,现有的 iLogtail 架构偏向于单体架构,导致模块间耦合严重,可扩展性和普适性较差,难以提供多个处理流程级联的能力。
▶︎ Golang 插件系统的引入极大地扩展了 iLogtail 的输入输出通道,且一定程度提升了 iLogtail 的处理能力。然而,囿于 C++ 部分的实现,输入输出与处理模块间的组合能力仍然严重受限:
1)C++ 部分原生的高性能处理能力仍然仅限于采集日志文件并投递至日志服务的场景使用;
2)C++ 部分的处理能力无法与插件系统的处理能力相结合,二者只能选其一,从而降低了复杂日志处理场景的性能。
▶︎ 与 iLogtail 整体架构类似,现有的 iLogtail 采集配置结构也采用平铺结构,缺乏处理流水线的概念,无法表达处理流程级联的语义。
基于上述原因,在 iLogtail 诞生 10 周年之际,日志服务启动对 iLogtail 的升级改造,寄希望于让 iLogtail 的易用性更佳,性能更优,可扩展性更强,从而更好地服务广大用户。
目前,经过半年多的重构与优化,iLogtail 2.0 已经呼之欲出。接下来,就让我们来抢先了解一下 iLogtail 2.0 的新特性吧!
02 新特性
(一)【商业版】采集配置全面升级流水线结构
为了解决旧版采集配置平铺结构无法表达复杂采集行为的问题,iLogtail 2.0 全面拥抱新版流水线配置,即每一个配置对应一条处理流水线,包括输入模块、处理模块和输出模块,每个模块由若干个插件组成,各模块的插件功能如下:
- 输入插件:用于从指定输入源获取数据(各插件具体功能详见输入插件[1])
- 处理插件:用于对日志进行解析和处理(各插件具体功能详见处理插件[2]),可进一步分为原生处理插件和扩展处理插件
- 原生处理插件:性能较优,适用于大部分业务场景,推荐优先使用
- 扩展处理插件:功能覆盖更广,但性能劣于原生处理插件,建议仅在原生处理插件无法完成全部处理需求时使用
- 输出插件:用于将处理后的数据发送至指定的存储
我们可以用一个 JSON 对象来表示一个流水线配置:

其中,inputs、processors 和 flushers 即代表输入、处理和输出模块,列表中的每一个元素 {...} 即代表一个插件;global 代表流水线的一些配置。有关流水线配置结构的具体信息,可参见 iLogtail 流水线配置结构[3]。
示例:采集 /var/log 目录下的 test.log,对日志进行 json 解析后发送到日志服务。以下是实现该采集需求对应的旧版和新版配置,可以看到新版配置十分精炼,执行的操作一目了然。
旧版配置:
{
"configName": "test-config",
"inputType": "file",
"inputDetail": {
"topicFormat": "none",
"priority": 0,
"logPath": "/var/log",
"filePattern": "test.log",
"maxDepth": 0,
"tailExisted": false,
"fileEncoding": "utf8",
"logBeginRegex": ".*",
"dockerFile": false,
"dockerIncludeLabel": {},
"dockerExcludeLabel": {},
"dockerIncludeEnv": {},
"dockerExcludeEnv": {},
"preserve": true,
"preserveDepth": 1,
"delaySkipBytes": 0,
"delayAlarmBytes": 0,
"logType": "json_log",
"timeKey": "",
"timeFormat": "",
"adjustTimezone": false,
"logTimezone": "",
"filterRegex": [],
"filterKey": [],
"discardNonUtf8": false,
"sensitive_keys": [],
"mergeType": "topic",
"sendRateExpire": 0,
"maxSendRate": -1,
"localStorage": true
},
"outputType": "LogService",
"outputDetail": {
"logstoreName": "test_logstore"
}
}新版流水线配置:
{
"configName": "test-config",
"inputs": [
{
"Type": "file_log",
"FilePaths": "/var/log/test.log"
}
],
"processors": [
{
"Type": "processor_parse_json_native"
"SourceKey": "content"
}
],
"flushers": [
{
"Type": "flusher_sls",
"Logstore": "test_logstore"
}
]
}如果在执行 json 解析后需要进一步处理,在流水线配置中只需额外增加一个处理插件即可,但是在旧版配置中已经无法表达上述需求。
有关新版流水线配置和旧版配置的兼容性问题,请参见文末兼容性说明板块。
全新 API
为了支持流水线配置,同时区分旧版配置结构,我们提供了全新的用于管理流水线配置的 API 接口,包括:
- CreateLogtailPipelineConfig
- UpdateCreateLogtailPipelineConfig
- GetLogtailPipelineConfig
- DeleteLogtailPipelineConfig
- ListLogtailPipelineConfig
有关这些接口的详细信息,请参见 OpenAPI 文档[4]。
全新控制台界面
与流水线采集配置结构相对应,前端控制台界面也进行了全新升级,分为了全局配置、输入配置、处理配置和输出配置。

与旧版控制台界面相比,新版控制台具有如下特点:参数内聚:某一功能相关的参数集中展示,避免了旧版控制台参数散落各处出现漏配置。
示例:最大目录监控深度与日志路径中的**密切相关,旧版界面中,二者分隔较远,容易遗忘;在新版界面中,二者在一起,便于理解。
旧版控制台:

新版控制台:

所有参数均为有效参数:在旧版控制台中,启用插件处理后,部分控制台参数会失效,从而引起不必要的误解。新版控制台所有参数均为有效参数。
全新 CRD
同样,与新版采集配置对应,K8s 场景中与采集配置对应的 CRD 资源也全新升级。与旧版 CRD 相比,新版 CRD 具有如下特点:
- 支持新版流水线采集配置
- CRD 类型调整为 Cluster 级别,且将 CRD 名称直接作为采集配置名称,避免同一集群多个不同的 CRD 资源指向同一个采集配置引起冲突
- 对所有操作的结果进行定义,避免出现多次操作旧版 CRD 后出现的行为未定义情况
apiVersion: log.alibabacloud.com/v1alpha1
kind: ClusterAliyunLogConfig
metadata:
name: test-config
spec:
project:
name: test-project
logstore:
name: test-logstore
machineGroup:
name: test-machine_group
config:
inputs:
- Type: input_file
FilePaths:
- /var/log/test.log
processors:
- Type: processor_parse_json_native
SourceKey: content(二)处理插件组合更加灵活
对于文本日志采集场景,当您的日志较为复杂需要多次解析时,您是否在为只能使用扩展处理插件而困惑?是否为因此带来的性能损失和各种不一致问题而烦恼?
升级 iLogtail 2.0,以上问题都将成为过去!
iLogtail 2.0 的处理流水线支持全新级联模式,和 1.x 系列相比,有以下能力升级:
- 原生处理插件可任意组合:原有原生处理插件间的依赖限制不复存在,您可以随意组合原生处理插件以满足您的处理需求。
- 原生处理插件和扩展处理插件可同时使用:对于复杂日志解析场景,如果仅用原生处理插件无法满足处理需求,您可进一步添加扩展处理插件进行处理。
注意:扩展处理插件只能出现在所有的原生处理插件之后,不能出现在任何原生处理插件之前。
示例:假如您的文本日志为如下内容:
{"time": "2024-01-22T14:00:00.745074", "level": "warning", "module": "box", "detail": "127.0.0.1 GET 200"}
您需要将 time、level 和 module 字段解析出来,同时还需要将 detail 字段做进一步正则解析,拆分出 ip、method 和 status 字段,最后丢弃 drop 字段,则您可以按顺序使用“Json 解析原生处理插件”、“正则解析原生处理插件”和“丢弃字段扩展处理插件”完成相关需求:
【商业版】


【开源版】
{
"configName": "test-config"
"inputs": [...],
"processors": [
{
"Type": "processor_parse_json_native",
"SourceKey": "content"
},
{
"Type": "processor_parse_regex_native",
"SourceKey": "detail",
"Regex": "(\\S)+\\s(\\S)+\\s(.*)",
"Keys": [
"ip",
"method",
"status"
]
}
{
"Type": "processor_drop",
"DropKeys": [
"module"
]
}
],
"flushers": [...]
}采集结果如下:

(三)新增 SPL 处理模式
除了使用处理插件组合来处理日志,iLogtail 2.0 还新增了 SPL(SLS Processing Language)处理模式,即使用日志服务提供的用于统一查询、端上处理、数据加工等的语法,来实现端上的数据处理。使用 SPL 处理模式的优势在于:
- 拥有丰富的工具和函数:支持多级管道操作,内置功能丰富的算子和函数
- 上手难度低:低代码,简单易学
- 【商业版】统一语法:一个语言玩转日志采集、查询、加工和消费

SPL 语法
整体结构:
- 指令式语句,支持结构化数据和非结构化数据统一处理
- 管道符(|)引导的探索式语法,复杂逻辑编排简便
{
"configName": "test-config"
"inputs": [...],
"processors": [
{
"Type": "processor_parse_json_native",
"SourceKey": "content"
},
{
"Type": "processor_parse_regex_native",
"SourceKey": "detail",
"Regex": "(\\S)+\\s(\\S)+\\s(.*)",
"Keys": [
"ip",
"method",
"status"
]
}
{
"Type": "processor_drop",
"DropKeys": [
"module"
]
}
],
"flushers": [...]
}结构化数据 SQL 计算指令:
- where 通过 SQL 表达式计算结果产生新字段
- extend 根据 SQL 表达式计算结果过滤数据条目
*
| extend latency=cast(latency as BIGINT)
| where status='200' AND latency>100非结构化数据提取指令:
- parse-regexp 提取指定字段中的正则表达式分组匹配信息
- parse-json 提取指定字段中的第一层 JSON 信息
- parse-csv 提取指定字段中的 CSV 格式信息
*
| project-csv -delim='^_^' content as time, body
| project-regexp body, '(\S+)\s+(\w+)' as msg, user(四)日志解析控制更加精细
对于原生解析类插件,iLogtail 2.0 提供了更精细的解析控制,包括如下参数:
- KeepingSourceWhenParseFail:解析失败时,是否保留原始字段。若不配置,默认不保留。
- KeepingSourceWhenParseSucceed:解析成功时,是否保留原始字段。若不配置,默认不保留。
- RenameSourceKey:当原始字段被保留时,用于存储原始字段的字段名。若不配置,默认不改名。
示例:假设需要在日志字段内容解析失败时在日志中保留该字段,并重命名为 raw,则可配置如下参数:
- KeepingSourceWhenParseFail:true
- RenameSourceKey:raw
(五)【商业版】日志时间解析支持纳秒级精度
在 iLogtail 1.x 版本中,如果您需要提取日志时间字段到纳秒精度,日志服务只能在您的日志中额外添加“纳秒时间戳”字段。在 iLogtail 2.0 版本中,纳秒信息将直接附加至日志采集时间(__time__)而无需额外添加字段,不仅减少了不必要的日志存储空间,也为您在 SLS 控制台根据纳秒时间精度对日志进行排序提供方便。
如果需要在 iLogtail 2.0 中提取日志时间字段到纳秒精度,您需要首先配置时间解析原生处理插件,并在“源时间格式(SourceFormat)”的末尾添加“.%f”,然后在全局参数中增加"EnableTimestampNanosecond": true。
示例:假设日志中存在字段 time,其值为 2024-01-23T14:00:00.745074,时区为东 8 区,现在需要解析该时间至纳秒精度并将 __time__ 置为该值。


采集结果如下:

注意:iLogtail 2.0 不再支持 1.x 版本中提取纳秒时间戳的方式,如果您在 1.x 版本中已经使用了提取纳秒时间戳功能,在升级 iLogtail 2.0 后,需要按照上述示例手动开启新版纳秒精度提取功能,详细信息参见文末兼容性说明。
(六)【商业版】状态观测更加清晰
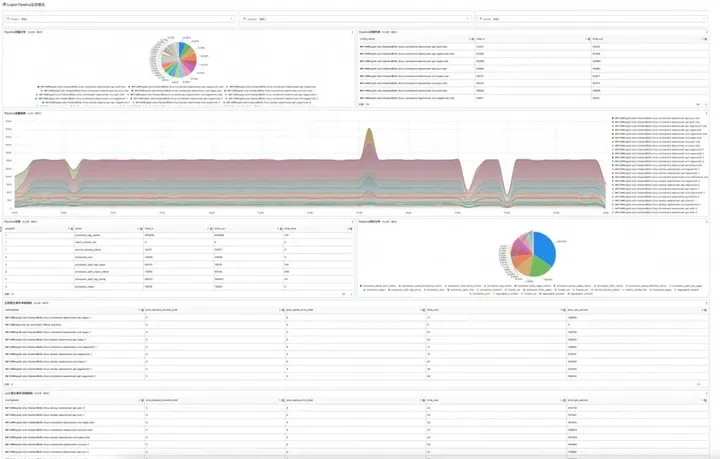
相比于 iLogtail 1.x 暴露的简单指标,iLogtail 2.0 极大地完善了自身可观测性的建设:
- 所有采集配置都有完整指标,可以在 Project/Logstore 等维度上进行不同采集配置的统计与比较
- 所有插件都有自己的指标,可以构建完整流水线的拓扑图,每个插件的状态可以进行清楚的观测
- C++ 原生插件提供更加详细的指标,可以用来监控与优化插件的配置参数
(七)运行更快更安全
iLogtail 2.0 支持 C++ 17 语法,C++ 编译器升级至 gcc 9,同时更新了 C++ 依赖库的版本,使得 iLogtail 的运行更快更安全。
表:iLogtail 2.0 单线程处理日志的性能(以单条日志长度 1KB 为例)
| 场景 | CPU(核) | 内存(MB) | 处理速率(MB/s) |
| 单行日志采集 | 1.06 | 33 | 400 |
| 多行日志采集 | 1.04 | 33 | 150 |
03 兼容性说明
(一)采集配置
商业版
- 新版流水线采集配置是完全向前兼容旧版采集配置的,因此:
- 在您升级 iLogtail 至 2.0 版本的过程中,日志服务会在下发配置时自动将您的旧版配置转换为新版流水线配置,您无需执行任何额外操作。您可以通过 GetLogtailPipelineConfig 接口直接获取旧版配置对应的新版流水线配置
- 旧版采集配置并不完全向后兼容新配流水线配置
- 如果流水线配置描述的采集处理能力可用旧版配置表达,则该流水线配置依然可以被 iLogtail 0.x 和 1.x 版本使用,日志服务会在向 iLogtail 下发配置时自动将新版流水线配置转换为旧版配置
- 反之,该流水线配置会被 iLogtail 0.x 和 1.x 版本忽略
开源版
新版采集配置与旧版采集配置存在少量不兼容情况,详见 iLogtail 2.0 版本采集配置不兼容变更说明[5]。
(二)iLogtail 客户端
1. 使用扩展处理插件时的 Tag 存储位置
当您使用扩展插件处理日志时,iLogtail 1.x 版本由于实现原因会将部分 tag 存放在日志的普通字段中,从而为您后续在 SLS 控制台使用查询、搜索和消费等功能时带来诸多不便。为了解决这一问题,iLogtail 2.0 将默认将所有 tag 归位,如果您仍希望保持 1.x 版本行为,您可以在配置的全局参数中增加"UsingOldContentTag": true。
- 对于通过旧版控制台界面和旧版 API 创建的采集配置,在您升级 iLogtail 2.0 后,tag 的存储位置仍然与 1.x 版本一致;
- 对于通过新版控制台界面和新版 API 创建的采集配置,在您升级 iLogtail 2.0 后,tag 的存储位置将默认归位。
2. 高精度日志时间提取
2.0 版本不再支持 1.x 版本的 PreciseTimestampKey 和 PreciseTimestampUnit 参数,当您升级 iLogtail 2.0 版本后,原有纳秒时间戳提取功能将失效,如果您仍需解析纳秒精度时间戳,您需要参照日志时间解析支持纳秒精度板块对配置进行手动更新。
3. 飞天格式日志微秒时间戳时区调整
2.0 版本的飞天解析原生处理插件将不再支持 1.x 版本的 AdjustingMicroTimezone 参数,默认微秒时间戳也会根据配置的时区进行正确的时区调整。
4. 日志解析控制
对于原生解析类插件,除了日志解析控制更加精细板块中提到的 3 个参数,还存在 CopyingRawLog 参数,该参数仅在 KeepingSourceWhenParseFail 和 KeepingSourceWhenParseSucceed 都为 true 时有效,它将在日志解析失败时,在日志中额外增加 __raw_log__ 字段,字段内容为解析失败的内容。
该参数的存在是为了兼容旧版配置,当您升级 iLogtail 2.0 版本后,建议您及时删去该参数以减少不必要的重复日志上传。
总结
为用户提供更舒适便捷的用户体验一直是日志服务的宗旨。相比于 iLogtail 1.x 时代,iLogtail 2.0 的变化是比较明显的,但这些转变只是 iLogtail 迈向现代可观测数据采集器的序曲。我们强烈建议您在条件允许的情况下尝试 iLogtail 2.0,也许您在转换之初会有些许的不适应,但我们相信,您很快会被 iLogtail 2.0 更强大的功能和更出色的性能所吸引。
相关链接:
[1] 输入插件
https://help.aliyun.com/zh/sls/user-guide/overview-19?spm=a2c4g.11186623.0.0.2a755c0dN5uxv4
[2] 处理插件
https://help.aliyun.com/zh/sls/user-guide/overview-22?spm=a2c4g.11186623.0.0.2f2d1279yGXSce
[3] iLogtail 流水线配置结构
[4] OpenAPI 文档
[5] iLogtail 2.0 版本采集配置不兼容变更说明
https://github.com/alibaba/ilogtail/discussions/1294
作者:张浩翔(笃敏)
本文为阿里云原创内容,未经允许不得转载。















 743
743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









