







操作系统的发展离不开南北向软硬件生态的扩展和支持,龙蜥社区也离不开各合作伙伴的共创。在 2023 龙蜥操作系统大会全面拥抱智算时代分论坛上,英特尔 AI 软件工程师王华强从两方面分享了英特尔至强处理器平台上的两个重点算力和内存带宽,以及英特尔 xFasterTransformer 开源项目(主要用于 CPU 平台)、xFT 开发软件图、软件架构和特点以及基于 xFT 平台大语言模型对比公开的性能数据。以下为本次分享原文:

(图/英特尔 AI 软件工程师王华强)
2023 年 12 月,英特尔发布了第五代至强的服务器平台,在 2023 年初发布了第四代至强服务器平台。服务器发布通常称之为 jtalk,一代 CPU 注重于特性,注重架构的升级,引入很多的特性。这一代 CPU 力度优化,会带来更多的 CPU 核心数,更高的 CPU 频率。刚发布的第五代至强服务器属于密度优化,第四代属于架构升级。

第四代至强可扩展处理器引入的一些新特性,其中一个是内存画面,引入 DDR5 规格的频率支持。第四代 DDR5 频率支持 4800MT 每秒,第五代 CPU 支持 5600MT 每秒,对比第三代 3200MT 每秒,内存带宽几乎翻一倍。另外一个提升来自数据总线,第四代至强开始支持 PCIE5.0 的数据总线,PCIE5.0 速度已经跑到 32GB 每秒,组件带宽的提升为 CPU 引入更多的设备带来了可能。这些设备其中之一就是 CXL,第四代至强支持 CXL1.1 。在这代平台上,开始有一个专门的系列 AMX 系列,支持 HBM 的内存。针对一些细分的业务领域,在芯片上集成了众多的加速器,QAT、IAA,可以加速加解密、压缩解压缩的业务。在对这些业务进行加速的同时,可以节省 CPU 的资源,起到 offload 作用。加速器用于网络负载均衡方面集成了 DLB 加速引擎。对于人工智能 AI,特别引入一个 AR 加速引擎,称之 AMS 加速引擎,AMS 主要做矩阵的运算。

大语言模型算法的基础就是 transform,再往下分可能是 atention、MLP 各种算法。这些算法需要很多变化,要有很多运算。典型算法是向量乘向量的计算,或者是矩阵乘矩阵的运算,大语言模型对算力的要求很高。
接下来回顾英特尔 CPU 尤其是服务器,了解一下算力如何演进。
在了解英特尔算力演进前先了解大语言模型向量乘向量或者矩阵乘矩阵,它们要做的事情都可以往下 breakdown 成 A 乘 B 再加上 C 这样的运算。为了完成乘加的运算,在早期平台比如像第一代 SKYLAKE 平台上需要三条指令去完成这样的运算。在后来的 CPU 上引入了 VNNI,如果数据的精度是 8bit,比较整齐用一条 VNNI 指令就可以完成乘加的运算。第四代引入了 AMX 矩阵运算单元,可以完成一个 A 矩阵乘 B 矩阵得到 C 矩阵。如果运算的 A 矩阵和 B 矩阵数据是 8bit 整形,可以一次性完成 16 行 64 列的 A 矩阵乘 64 行 16 列的矩阵。如果数据精度是 16bit 浮点,可以完成 16 行 32 列乘 32 行 16 列的矩阵相乘。

大语言模型对于硬件资源的另一需求体现在内存带宽上。要进行一次推理需要将所有的模型权重访问一遍,以 LLM 模型为例有 70 个并列参数,这些模型参数通常大于硬件容量,所以模型参数通常放在内存中。每进行一次推理,需要将参数或者模型权重访问一遍,需要很大的内存带宽。
第四代引入了 HBM 支持,但不是第四代所有的芯片都支持,只有 Max 系列的 CPU 上会集成 64GB 的 HBM 内存,再加上系统在 DDR 通道上支持的内存,实现了 1TB 每秒内存带宽的内存区域,兼顾了内存速度和内存容量。

对于内存带宽的扩展,第四代至强 CPU 同时支持 CXL 内存,在分享前先介绍 CXL 总线的一些基础知识。CXL 内存协议分为三个内存子协议:CXLIO、CXL.Cache、CXL.Memory。CXLIO 类似 PCle 总线,CXL.Cache 支持 CXL.Cache 设备,例如 CPU 网卡显卡,只要支持了 CXL.Cache 协议,就可以由硬件来保持网卡 GPU 等之间的一致性。CXL.Memory 类似普通内存。CXL 协议是由众多厂家推出的协议,第四代至强服务器已经开始支持 CXL1.1 设备,可以用 CXL1.1 所支持的 CXL.Memory 进行内存扩展。原有 8 个 DDR 通道可以用 CXL 再扩展 4 个通道,结合 CXL 内存可以将内存带宽做 50% 的提升。
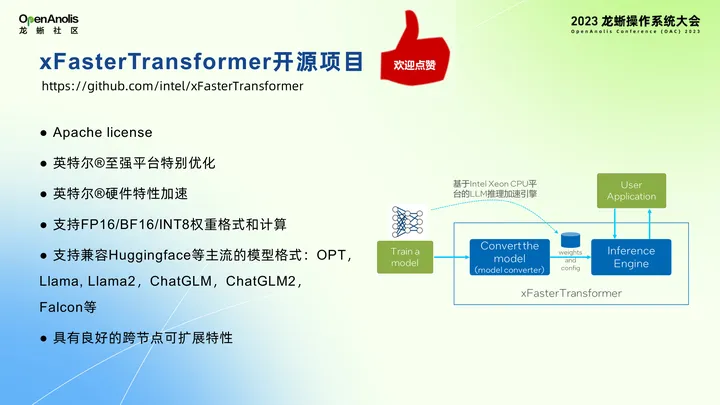
FasterTransformer 项目用于 GPU 推理,xFasterTransformer 主要注重 CPU 平台例如 Llama、ChatGLM 平台大语言模型推理的优化。xFasterTransformer 关注英特尔硬件的加速特性,对于英特尔平台尤其至强平台有特别优化。该项目遵循了 Apache 开源协议,欢迎大家下载试用。

xFasterTransformer 在 2023 年 3 月份开源,开源初就支持 ChatGLM 系列以及 Llama 小模型。数据精度除了 Float 外还支持 BF16、INT8 等混合精度。它支持分布式推理,如果一台服务器算力不够,可以搭建小型集群进行分布式推理。在第四季度对该项目做了更新,支持百度百窗系列的模型推理,支持 Llama2 模型推理,该模型在分布式小集群上进行推理,支持了 8bit 转型的数据精度。在 2024 年 Q1 会做一些优化例如使用 FP16 数据精度、使用 AMX 做优化,也会对 batching 做进一步优化。

xFT 整个软件架构建立的硬件是英特尔各种各样的 xeon 平台,也可能是支持 HBM 的 xeon 等,不同的硬件平台有不同的硬件特性。例如第四代第五代支持 AMX,但是在第一代并不支持 AMX 加速引擎,硬件的适配工作由软件架构的最底层的库进行适配。上图右边 OneCCL 做分布式通讯框架,OeDNN 做计算,IG 库还没有开源,专门针对大语言模型集中运算的特点所作的库。xFT 针对 Transformer 的算法做了一些封装,包括 atention、MLP 等。值得一提的是,这些算法都支持分布式计算,如果使用 atention 算力时间过长,可以使用集群方式将计算分布到多个机器上。xFT 从接口上支持 C++ 和 Python 接口。

xFT有三个特点,上面提到第一个特点是分布式计算,另外 xFT 集成开发基于 C++,保证推理框架的高性能。除此之外 xFT 也有其他的一些优化特点:实现了 Flash Attention 优化,CPU 版本通过 Flash Attention 可以减少内存带宽。多进程通信实现了内存零拷贝的算法,基于 GEMV 算法实现了零拷贝需求。针对 Attention、Normlous 算法,针对模型特点做了一些融合。
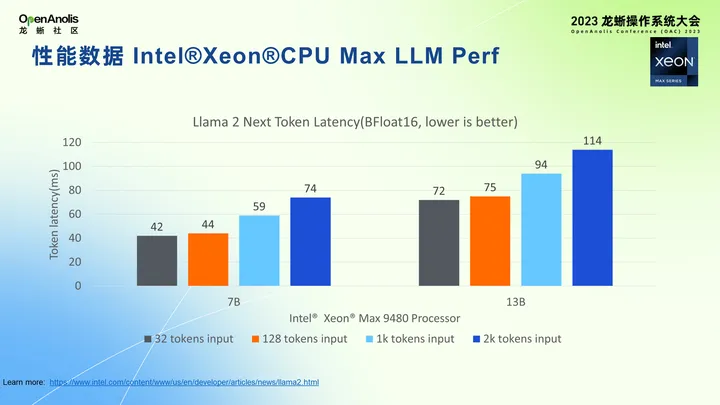
上图展示最近公开的性能数据。性能测试平台是在支持 HBM 第四代的 MAX CPU 上进行测试的,衡量性能指标采用 Next Token,推理出的模型首次词的平均时间。两个模型分别是 Llama 2 7B 模型和 Llama 2 13B 模型,从比较常用的 1024 Input token 参数来看,选用 Llama 2 7B 模型的平均 latency 是 59 毫秒,Llama 2 13B 模型输入 1024 尺寸产生的 latency 是 94 毫秒。
本文为阿里云原创内容,未经允许不得转载。















 502
502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









