






摘要

上图是添加表情后的效果,更加合理自然
拆分为三个时序任务,具体做法后面介绍
- 人脸带有表情(这个也是之前没有的)
- 音频驱动唇形
- 人脸增强
生成的表情图片和mask掉的原始图片同时唇形驱动
introduction
之前paper的问题
用视频中原始的图片作为head pose的参考(LipGAN、Wave2lip中mask掉的gt),我们发现唇形对head pose很敏感, 直接使用原始照片可能最终out-of-sync(不同步,不自然,)
大概是改变pose的情况下唇形学习的内容比较多、比较困难、效果也就比较差。 这里通过生成中性表情的图片,不用改变pose,只用着眼于唇形区域效果会更好。
fig4 提到一点,中性表情可以看做是将所有的唇形进行标定了一下。 之前的操作在没有声音的时候唇形也有比较大的幅度
我们的解决方案
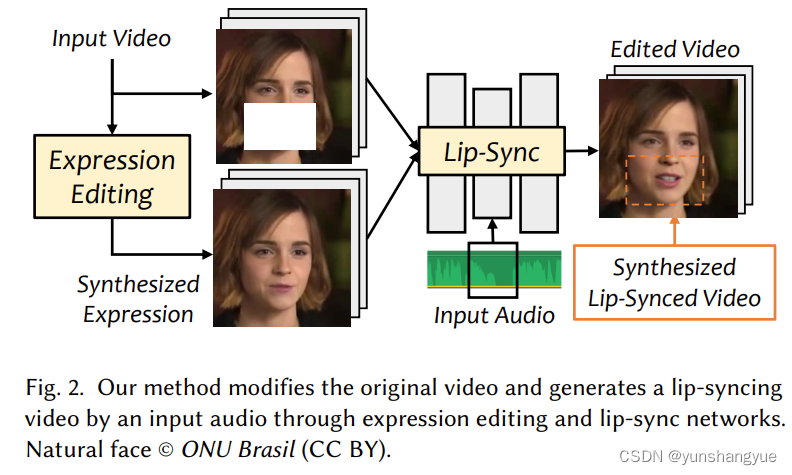
fig-2中我们针对这个问题设计了三个模块。将输入照片经过表情中和(就是不开心也不伤心的自然表情),最终生成的照片的质量比之前的工作也好(没有mask区域的模糊,以及唇齿比较清晰)
具体做法
| 功能 | 输出 | |
|---|---|---|
| input video | 输入 | |
| crop face region | 检测 | 人脸 box |
| 提取每帧pose 和expression 参数(3DMM 形式) | ||
| 生成中性表情视频 fig2中没有mask哪个图片 | ||
| lip-sync网络 | 唇形驱动 | |
| enhancement network | 后处理来提升效果 |
网络结构

主要解决两个问题:
- 训练的时候送入gt的head pose
- 画质低
Semantic-guided Reenactment Network

开源网络
将视频每一帧的人脸提取出来,通过网络生成3DMM 中性表情的每一帧视频
Lip-Sync Network

细节有所调整,差别不大
唇形驱动
Identity-aware Enhancement Network

受制于训练集的分辨率比较低, 所有我们将训练集通过GAN进行了增强(分辨率肯定变大了)
GAN增强后的数据集和真实图片数据之间肯定有差别(domain gap),所以这里想通过原始输入视频来获取 真实图片域的信息
上图是不同的增强的网络的效果
Post-processing
一般嘴部的box区域会有一些artifact(伪影,就是一个box内更加模糊、画质更差)。
我们通过Multi-band Laplacian Pyramids Blending [Burt and Adelson 1983]将人脸和牙齿解析后paste
贡献点
- 不用从src pose学习到gt pose, 这样学习内容更加少,效果也就更好
- 工程上的整合比较多。














 156
156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









