






摘要
现在的项目都是对一张图片或者一个固定用户的视频进行训练。
存在的问题是:对随机的用户、不受限制的说话视频效果比较差。
我们的做法:一个强大的判别器, 提出了一个新的评估指标,有demo且开源。
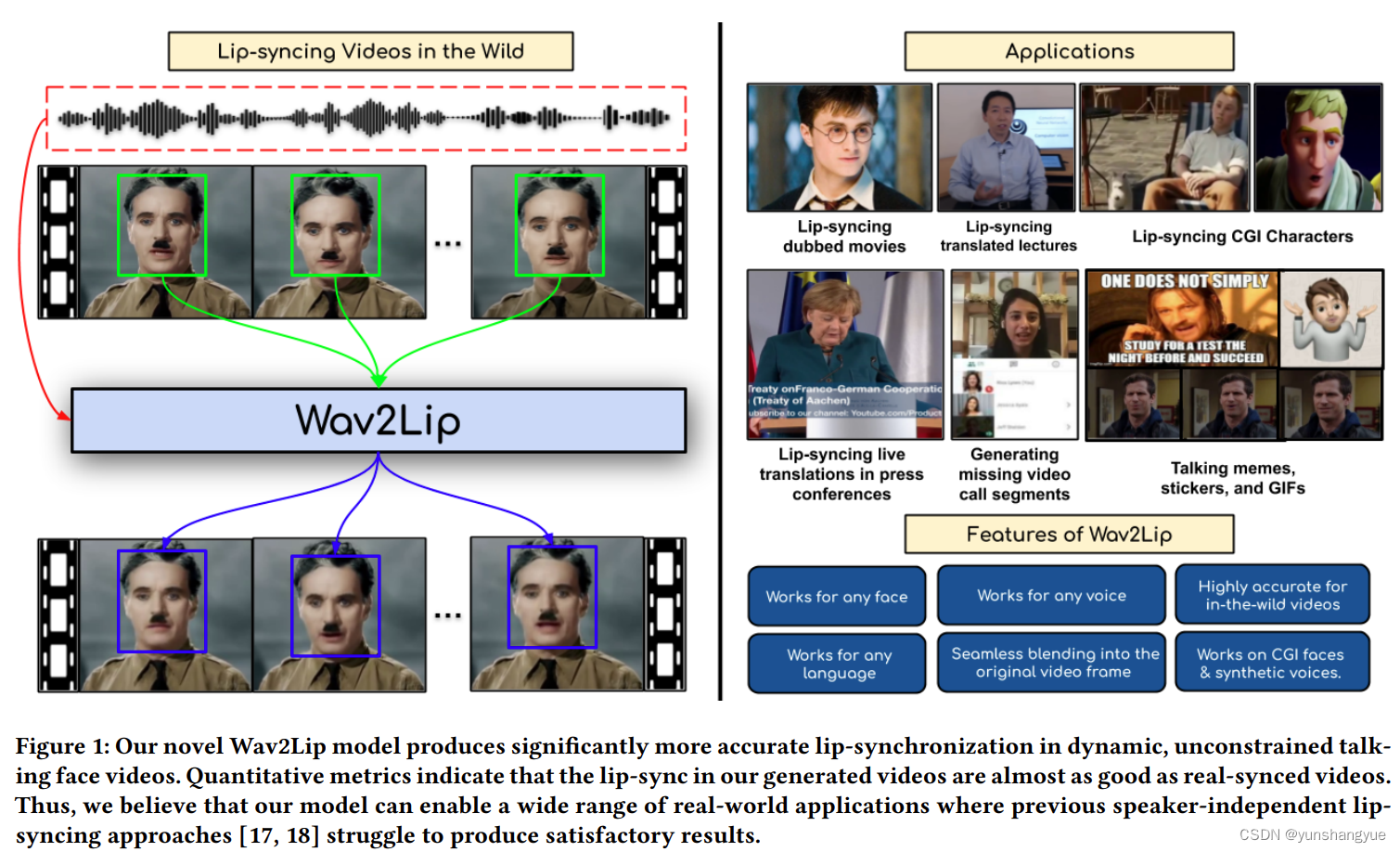
introduction
- 技术的应用价值就不写了
- 之前的项目包括LipGAN 都是针对每个人都进行训练, 可以参考LipGAN, 里面的Voice Transfer 所以固定的模型输出的都是固定的音调的人,这样就不能广泛的应用
- 我们的贡献
- 提出一个新的网络wave2lip, 效果遥遥领先
- 提出了一个新的评估方式
- 提供了一个新的测试集 ReSyncED
- 第一个speaker-independent model (无关、解耦)
之前判别器的缺点
L1 loss 不好
作者提到,唇部区域大概占整个图片的4% 左右, 网络开始学到的是整个face,LipGAN 训练了20epoch, 从第11个epoch才开始学习嘴唇
LipGAN判别器的缺点
LipGAN 的判别器在off-sync audio-lip pairs(A的声音和视频生成B的视频)中的准确率只有56%。但是在wave2lip中的判别器准确率有91%。
- LipGAN 使用单张照片, wave2lip使用的是时序的
- 比较大的pose变化和scale,使得判别器 判别是否有视觉冲突(比如说错乱,不合理等),但是并不是audio和lip的关系的监督。
本文提出的判别器
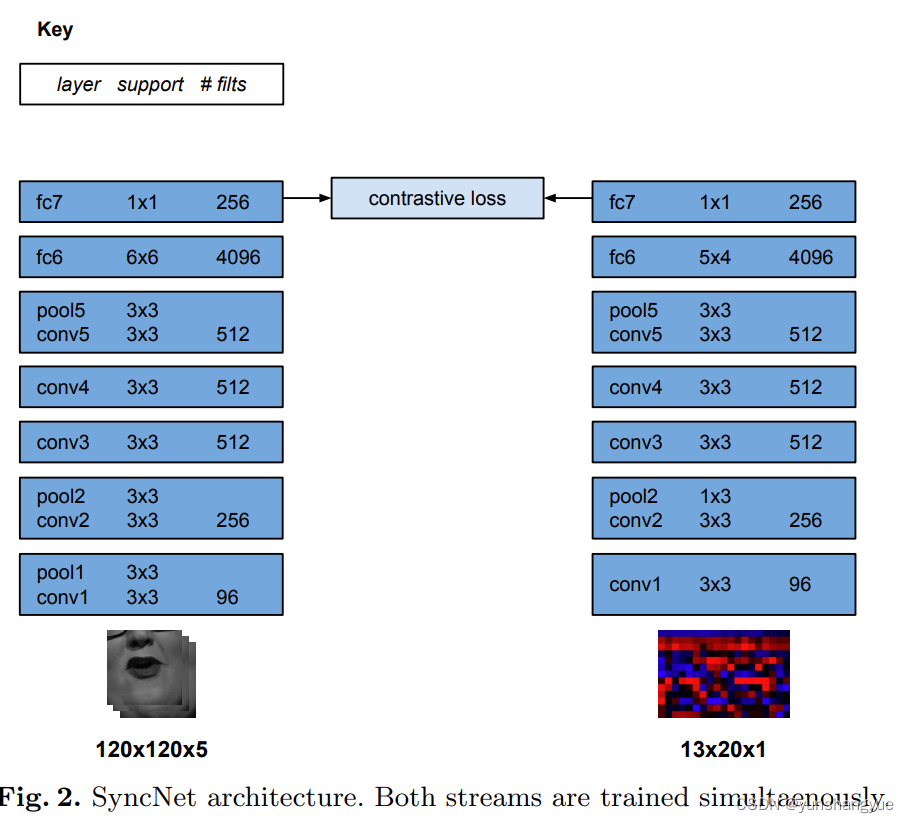
这个就是原始的论文的架构,在这个基础上更改的,
Out of time: automated lip sync in the wild
- 之前输入都是灰度图,现在输入是rgb图片
- 网络结构上更加深了
- 我们使用了cosine-similarity loss(余弦相似度)
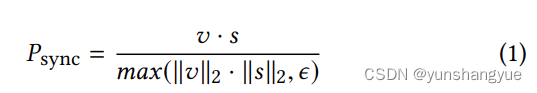
v:视频的embedding, 是经过ReLU-activated后的
s:音频的embedding
我们的项目wave2lip
基于LipGAN判别器的缺点,我们提供了一个唇形同步的判别器。在训练的时候这个不用fine-tune
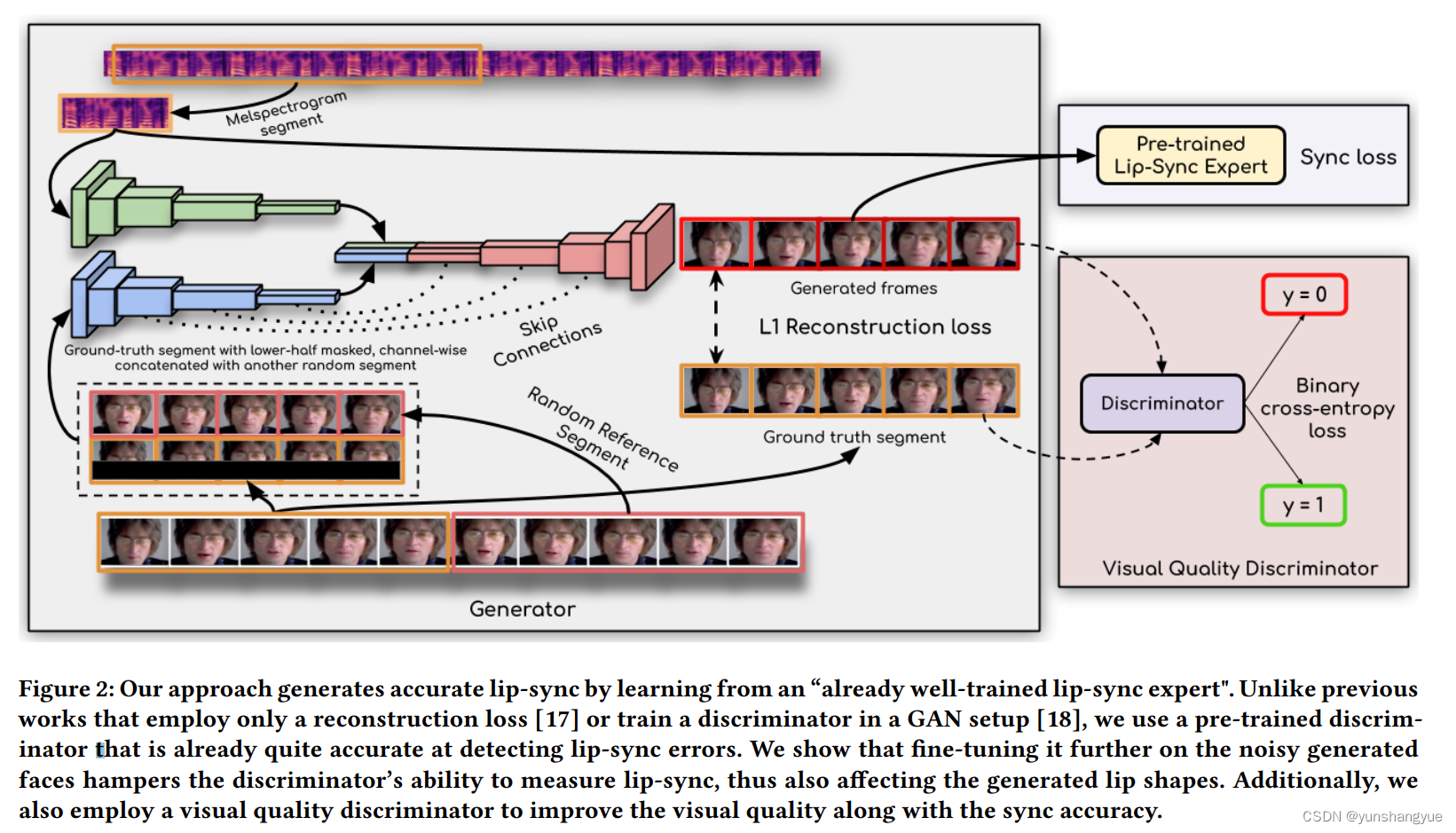
输入数据
- 一个时间窗V内Tv帧人脸,
- 时间窗V内的音频分割S, Ta x D, 这里可以是in-sync(音频 视频同步)或者out-of-sync(音频视频不同步)
L1 loss
dentity Encoder: 图片的encoder
Speech Encoder: 语音的encoder
Face Decoder: 音频 和 视频 的Decoder
损失:逐像素的 L1 loss
pretrained Lip-Sync loss
之前训练好的判别器的loss,
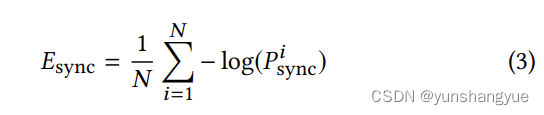
second discriminator
只使用pretrained discriminator会使得视频有违和的感觉,所以这里添加了一个判别器,可能pretrained 判别器和这里的Generator不是同时训练的,可能会有域的不兼容问题
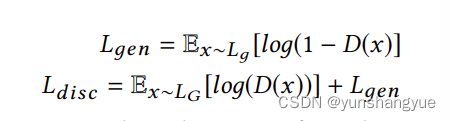
生成器loss: 判别器尽量看不出来
判别器loss: 生成器的loss + 看走眼的
整体loss
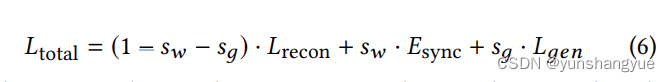
新的评估指标
旧的指标问题
image A ,speech A, 配对;
image B , speech B, 配对;
输入image A, Speech B, image B mask, generate image B
我们期望的是生成image B 的唇形,我们找不到image A pose 下 image B 唇形的照片
- 评估的时候是没有target head pose 信息,这个难度就提升了
- 参考帧是随机被选择的,可能导致问题结果不同
- 没有时序信息
- SSIM、PSNR 评估的是整个照片,而没有针对唇部
LMD着眼于唇部,但是lip landmark在生成的脸部精度不高。(应该是使用landmark效果不好)
新的评估指标
lip-sync discriminator,这个不是我们训练的这个判别器,是Out of time: automated lip sync in the wild 论文里的判别器。 这个训练的数据集不开源,但是代码以及模型开源了。
“LSE-D" (“Lip Sync Error - Distance")
音频和视频都会经过判别器的encoder, encoder的匹配程度
“LSE-C" Lip Sync Error- Confidence
最终判别器的分值
随机选择音频,生成对应的伪视频,然后判别

















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









