







spark-redis是基于jedis实现的redis rdd,可对redis的String, Hash, List, Set and Sorted Set,XStream数据结构进行转换读写,支持将redis数据转换成DataFrames的方式,以Spark SQL进行统计运算,支持官方Redis cluster的集群读取模型,可自动感知Redis分区,亦可根据配置调整分区数。
支持版本:
| Spark-Redis | Spark | Redis | Supported Scala Versions |
| master | 3.0.x | >=2.9.0 | 2.12 |
| 2.4, 2.5, 2.6 | 2.4.x | >=2.9.0 | 2.11, 2.12 |
| 2.3 | 2.3.x | >=2.9.0 | 2.11 |
| 1.4 | 1.4.x | 2.10 |
使用方式,如使用2.4.x版本可引用Maven库:
<dependencies>
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>spark-redis_2.11</artifactId>
<version>2.4.2</version>
</dependency>
</dependencies>or
<dependencies>
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>spark-redis_2.12</artifactId>
<version>2.4.2</version>
</dependency>
</dependencies>使用2.3.x版本需要下载源代码:
git clone https://github.com/RedisLabs/spark-redis.git更改Spark版本号
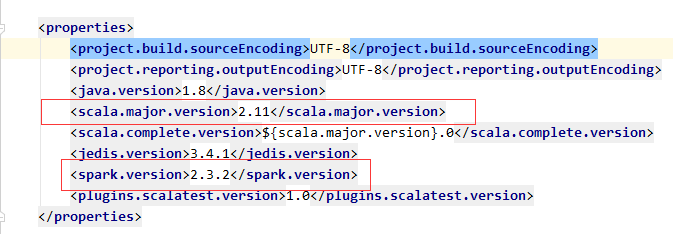
然后进入到相应的目录进行编译:
cd spark-redis
mvn clean package -DskipTests编译后,将编译好的包install到本地的maven库
mvn install:install-file -DgroupId=com.redislabs -DartifactId=spark-redis_2.11 -Dversion=3.0.0-SNAPSHOT -Dpackaging=jar -Dfile=.\spark-redis_2.11-3.0.0-SNAPSHOT.jar在对应的POM中加载对应包:
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>spark-redis_2.11</artifactId>
<version>3.0.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.73</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.4.1</version>
<type>jar</type>
<scope>compile</scope>
</dependency>编写测试代码:
SparkConf sparkConf = new SparkConf().setAppName(appName).set("spark.redis.host", "127.0.0.1")
.set("spark.redis.port", "6000")
.set("spark.redis.auth","123456"); /*初始化sparkconf,设置redis集群的IP、端口及密码,集群模式可使用任一节点的IP与端口*/
SparkSession spark = SparkSession
.builder().master("local[4]")
.config(sparkConf)
.getOrCreate();
Dataset<Row> df = spark.createDataFrame(Arrays.asList(
new Person("John", 35),
new Person("Peter", 40)), Person.class);
df.write()
.format("org.apache.spark.sql.redis")
.option("table", "person2")
.option("key.column", "name")
.mode(SaveMode.Overwrite)
.save(); //对redis进行写入操作
//结果:
/*127.0.0.1:6000> keys *
1) "person2:Peter"
127.0.0.1:6001> keys *
1) "person2:John"
127.0.0.1:6002> keys *
1) "_spark:person2:schema" 存储元数据信息
*/
//redis手动初始化数据 hset person:1 name mike age 30
// hset person:2 name ken age 40
List<StructField> schemaFields = new ArrayList<StructField>();
schemaFields.add(new StructField("_id",StringType,false,Metadata.empty())); //其 hash key值默认为_id
schemaFields.add(new StructField("name",StringType,true,Metadata.empty()));
schemaFields.add(new StructField("age",IntegerType,true,Metadata.empty()));
StructType structType=DataTypes.createStructType(schemaFields);
Dataset<Row> ds=spark.read()
.format("org.apache.spark.sql.redis")
.option("keys.pattern", "person:*")
.schema(structType).load();
/*另其自动识别字段模式,默认所有字段为String类型
Dataset<Row> ds=spark.read()
.format("org.apache.spark.sql.redis")
.option("infer.schema", true)
.option("table", "person")
.schema(structType).load();
*/
ds.show();
ds.createOrReplaceTempView("persontbl");
Dataset<Row> ds2=spark.sql("select * from persontbl");
ds2.show();
/*结果
+---+----+---+
|_id|name|age|
+---+----+---+
| 1|mike| 30|
| 2| ken| 40|
+---+----+---+
*/
//年龄汇总
Dataset<Row> ds3=spark.sql("select sum(age) from persontbl");
ds3.show();
/*
+--------+
|sum(age)|
+--------+
| 70|
+--------+*/
探其代码实现,通过redis的scan方法获取到key值后,通过单节点的连接器,一条条的对key的value进行遍历,该操作在大数据量时,可能导致性能问题,需在网络上进行相应的优化。
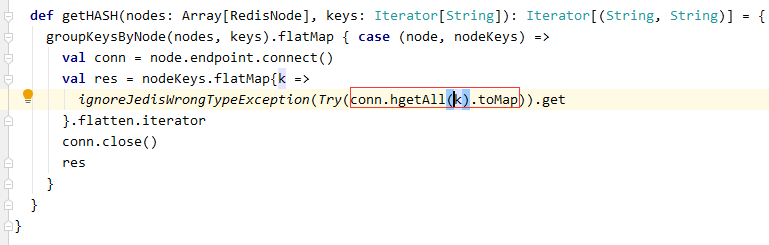
同样,其String,List, Set and Sorted Set的实现方式亦是如此。

















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









