






读写分离将读操作和写操作分别分配给不同的数据库实例,以提高系统的吞吐量和性能。
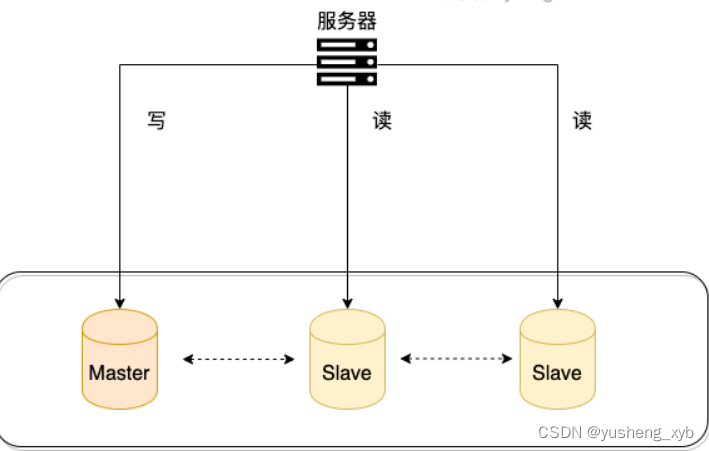
一般情况下,我们都会选择一主多从,也就是一台主数据库负责写,其他的从数据库负责读。主库和从库之间会进行数据同步,以保证从库中数据的准确性。这样的架构实现起来比较简单,并且也符合系统的写少读多的特点。
如何实现读写分离
基本步骤
- 部署多台数据库,选择其中的一台作为主数据库,其他的一台或者多台作为从数据库。保证
- 主数据库和从数据库之间的数据是实时同步的,这个过程也就是我们常说的主从复制。
- 系统将写请求交给主数据库处理,读请求交给从数据库处理。
实现方式有两种:
1.代理方式
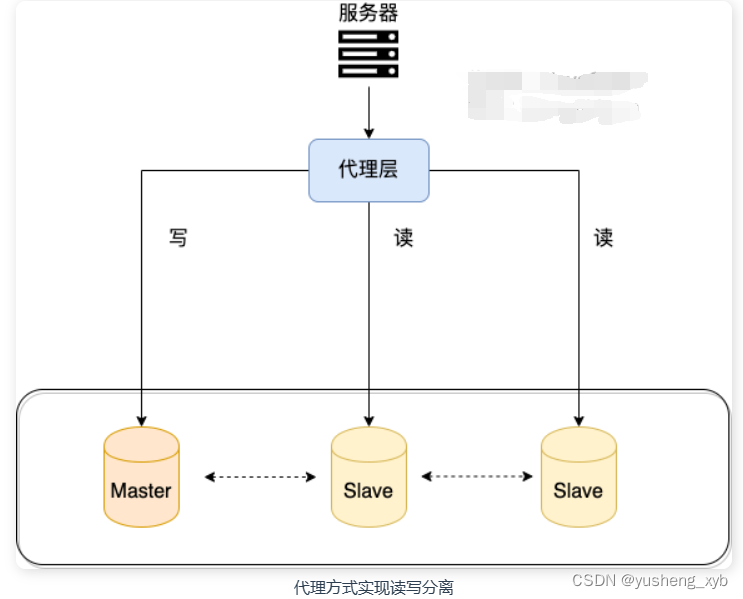
我们可以在应用和数据中间加了一个代理层。应用程序所有的数据请求都交给代理层处理,代理层负责分离读写请求,将它们路由到对应的数据库中。
提供类似功能的中间件有 MySQL Router(官方, MySQL Proxy 的替代方案)、Atlas(基于 MySQL Proxy)、MaxScale、MyCat。
2.组件方式
我们可以通过引入第三方组件来帮助我们读写请求。
这种方式目前在各种互联网公司中用的最多的,相关的实际的案例也非常多。如果你要采用这种方式的话,推荐使用 sharding-jdbc ,直接引入 jar 包即可使用,非常方便。同时,也节省了很多运维的成本。
主从复制的原理
MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据库中数据的所有变化(数据库执行的所有 DDL 和 DML 语句)。因此,我们根据主库的 MySQL binlog 日志就能够将主库的数据同步到从库中。
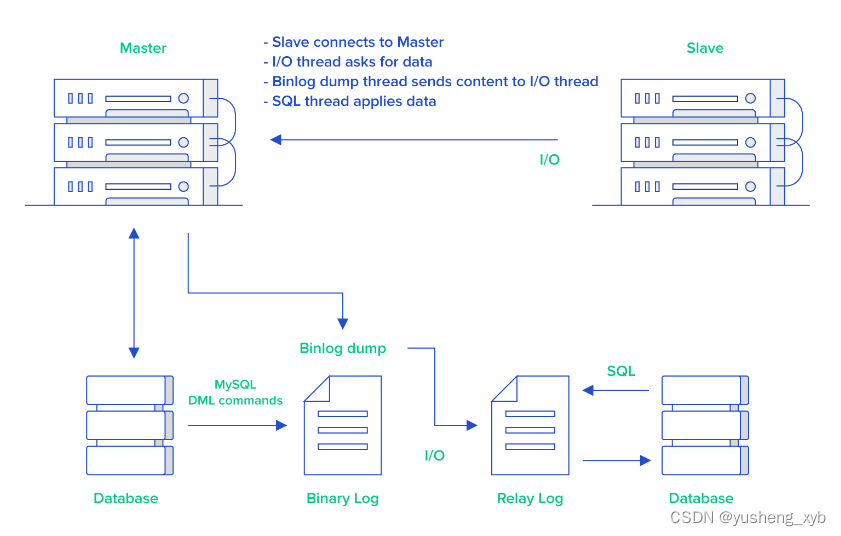
- 主库将数据库中数据的变化写入到 binlog
- 从库连接主库
- 从库会创建一个 I/O 线程向主库请求更新的 binlog
- 主库会创建一个 binlog dump 线程来发送 binlog ,从库中的 I/O 线程负责接收
- 从库的 I/O 线程将接收的 binlog 写入到 relay log 中。
- 从库的 SQL 线程读取 relay log 同步数据到本地(也就是再执行一遍 SQL )。
如何避免主从延迟
读写分离对于提升数据库的并发非常有效,但是,同时也会引来一个问题:主库和从库的数据存在延迟,比如你写完主库之后,主库的数据同步到从库是需要时间的,这个时间差就导致了主库和从库的数据不一致性问题。这也就是我们经常说的 主从同步延迟 。
如果我们的业务场景无法容忍主从同步延迟的话,应该如何避免呢(注意:我这里说的是避免而不是减少延迟)?
第一个方式:强制将读请求路由到主库处理
可以将那些必须获取最新数据的读请求都交给主库处理.
第二个方式:延迟处理
既然主从同步存在延迟,那我就在延迟之后读取啊,比如主从同步延迟 0.5s,那我就 1s 之后再读取数据。这样多方便啊!方便是方便,但是也很扯淡。
不过,如果你是这样设计业务流程就会好很多:对于一些对数据比较敏感的场景,你可以在完成写请求之后,避免立即进行请求操作。比如你支付成功之后,跳转到一个支付成功的页面,当你点击返回之后才返回自己的账户。














 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









