



原文链接:[1509.02971] Continuous control with deep reinforcement learning
DDPG是一种确定性策略梯度算法,是在DPG的研究基础上继续进行的,没看过DPG文章的友友,可以点这个链接论文阅读总结:确定性策略梯度算法(Deterministic Policy Gradient Algorithms)DPG-CSDN博客
1. 研究背景
-
连续动作控制的挑战:传统强化学习算法(如 DQN)在离散动作空间表现优异,但难以直接扩展到连续动作空间,尤其是高维任务(如机器人控制)。
-
确定性策略的潜力:直接优化确定性策略可避免随机策略的高方差问题,但需解决函数逼近的不稳定性。
2. 核心贡献
-
深度确定性策略梯度(DDPG) 将确定性策略梯度(DPG)与深度神经网络结合,提出端到端的模型 - free 算法,适用于高维连续动作空间。
-
稳定性改进
-
经验回放(Replay Buffer):存储历史经验,打破数据相关性,支持批量训练。
-
目标网络(Target Network):通过软更新(\(\tau \ll 1\))稳定 TD 目标,避免发散。
-
批量归一化(Batch Normalization):处理状态空间的尺度差异,提升泛化能力。
-
-
多模态输入支持 成功从原始像素输入学习策略(如 64x64 图像),扩展了强化学习的应用场景。
3. 算法设计
-
架构
-
Actor 网络:输出确定性策略 \(\mu(s|\theta^\mu)\)(如 MLP 或 CNN)。
-
Critic 网络:估计动作值函数 \(Q(s,a|\theta^Q)\),输入包含状态和动作。
-
目标网络:独立的 \(Q'\) 和 \(\mu'\),参数通过软更新跟踪主网络。
-
-
训练流程
-
探索:使用 Ornstein-Uhlenbeck 噪声生成动作序列,存储到回放缓冲区。
-
更新 Critic:最小化 TD 误差:\ \(y_i = r_i + \gamma Q'(s_{i+1}, \mu'(s_{i+1})|\theta^{Q'})\)
-
更新 Actor:沿动作值梯度优化策略:\ \(\nabla_{\theta^\mu} J \approx \mathbb{E}_{s \sim \rho^\beta} \left[ \nabla_a Q(s,a|\theta^Q) \nabla_{\theta^\mu} \mu(s|\theta^\mu) \right]\)
-
4. 实验验证
-
任务覆盖
-
经典控制:CartPole 摆起、双摆平衡。
-
机器人控制:猎豹奔跑(20 维动作)、人形机器人行走、章鱼臂操作。
-
自动驾驶:Torcs 赛车游戏(像素输入)。
-
像素输入:直接从原始图像学习策略,性能接近低维状态输入。
-
-
性能对比
-
基准对比:DDPG 在多数任务中达到或超过基于模型的规划算法(如 iLQG)的性能。
-
消融实验:目标网络和批量归一化是稳定性的关键,缺少任一组件会导致性能显著下降。
-
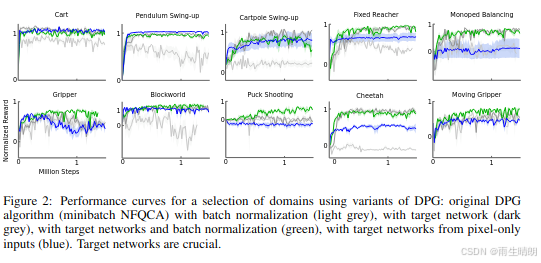
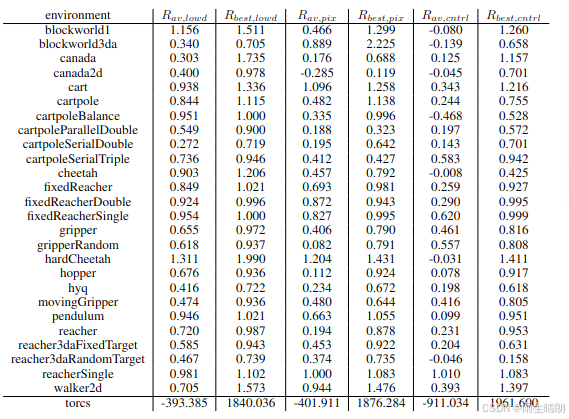
5. 理论意义
- 深度强化学习框架:首次将确定性策略梯度与深度神经网络结合,为高维连续控制提供了通用解决方案。
- 稳定性机制:经验回放和目标网络的引入,为深度强化学习的稳定性提供了理论依据。
- 端到端学习:证明了从原始像素输入直接学习复杂控制策略的可行性。
6. 应用价值
-
机器人控制:直接优化微分控制器(如猎豹奔跑、人形机器人行走)。
-
自动驾驶:在 Torcs 赛车游戏中实现端到端驾驶策略。
-
高维决策:适用于金融、医疗等高维复杂场景。
7. 局限性与未来方向
-
数据效率:依赖大量训练样本,在样本稀缺场景中表现受限。
-
探索策略:固定噪声策略可能无法覆盖所有探索需求,需结合自适应噪声。
-
扩展方向:结合模型预测控制(MPC)、多智能体协作、强化学习与规划的融合。
8. 总结
DDPG 通过引入深度神经网络、经验回放和目标网络,解决了高维连续动作空间的控制问题,在 20 多个复杂任务中取得突破性进展。其核心创新在于将深度学习与确定性策略梯度结合,为机器人控制、自动驾驶等领域提供了高效且稳定的解决方案,为后续深度强化学习方法(如 SAC、TD3)奠定了基础。
与DPG的相同点
| 维度 | DPG | DDPG |
|---|---|---|
| 理论基础 | 确定性策略梯度定理 | 继承 DPG 的梯度公式,结合深度学习 |
| 离策略学习 | 使用行为策略生成样本 | 经验回放 + 目标网络,强化离策略学习 |
| actor-critic 架构 | 线性或 tile-coding 逼近策略和值函数 | 深度神经网络逼近策略和值函数 |
与 DPG 的不同点
| 维度 | DPG | DDPG |
|---|---|---|
| 函数逼近 | 线性 / 低维特征(如 tile-coding) | 深度神经网络(全连接 / 卷积层) |
| 稳定性机制 | 兼容函数逼近 | 经验回放、目标网络、批量归一化 |
| 探索策略 | 固定高斯噪声 | 时间相关噪声(Ornstein-Uhlenbeck) |
| 应用场景 | 低维任务(如章鱼臂控制) | 高维复杂任务(机器人、像素输入) |
| 数据效率 | 较低(依赖兼容函数) | 较高(批量训练与经验重用) |
| 输入模态 | 低维状态特征 | 原始像素输入(端到端学习) |
DDPG 是 DPG 的深度强化学习扩展,通过引入神经网络和稳定性机制,解决了高维连续动作空间的控制问题,并在多个复杂任务中取得突破性进展。其核心创新在于将深度学习与确定性策略梯度结合,为机器人控制、自动驾驶等领域提供了高效且稳定的解决方案。


















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











