







交叉验证(Cross-Validation)一般要满足:
1)训练集的比例要足够多,一般大于一半
2)训练集和测试集要均匀抽样
1、训练数据集,交叉验证数据集,测试数据集的作用
参考:http://blog.csdn.net/wu_nan_nan/article/details/70169836
在Andrew Ng的机器学习教程里,会将给定的数据集分为三部分:训练数据集(training set)、交叉验证数据集(cross validation set)、测试数据集(test set)。三者分别占总数据集的60%、20%、20%。
那么这些数据集分别是什么作用呢?
假设我们训练一个数据集,有下面10中模型可以选择:
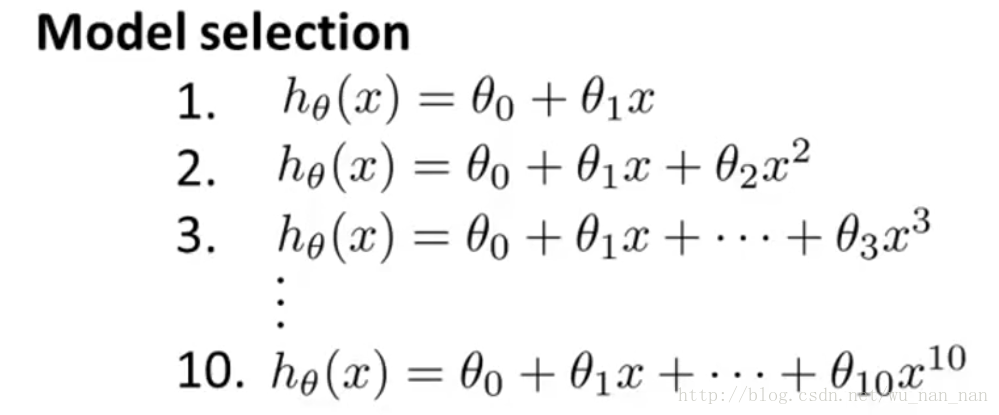
我们想知道两件事:
1)这10中模型中哪种最好(决定多项式的阶数d);
2)最好的模型的θ参数是什么。
为此,我们需要,
使用训练数据集分别训练这10个模型;
用训练好的这10个模型,分别处理交叉验证数据集,统计它们的误差,取误差最小的模型为最终模型(这步就叫做Model Selection)。
用测试数据集测试其准确性。
这里有个问题要回答:为什么不直接使用测试数据集(test set)来执行上面的第2步?
答:如果数据集只分成训练数据集(training set)和测试数据集(test set),且训练数据集用于训练θ,测试数据集用于选择模型,那么就缺少能够公平的评判最终模型优劣的数据集,因为最终的模型就是根据训练数据集和测试数据集训练得到的,肯定在这两个数据集上表现良好,但不一定在其它数据集上也如此。
但是,当样本总量少的时候,上面的划分就不合适了。常用的是留少部分做测试集。然后用以下方法进行交叉(cv)验证
2、三大CV的方法
参考:http://blog.sina.com.cn/s/blog_688077cf0100zqpj.html
1).Hold-Out Method
方法:将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此Hold-OutMethod下分类器的性能指标.。Hold-OutMethod相对于K-fold Cross Validation 又称Double cross-validation ,或相对K-CV称 2-fold cross-validation(2-CV)
优点:好处的处理简单,只需随机把原始数据分为两组即可
缺点:严格意义来说Hold-Out Method并不能算是CV,因为这种方法没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关系,所以这种方法得到的结果其实并不具有说服性.(主要原因是 训练集样本数太少,通常不足以代表母体样本的分布,导致 test 阶段辨识率容易出现明显落差。此外,2-CV 中一分为二的分子集方法的变异度大,往往无法达到「实验过程必须可以被复制」的要求。)
2).K-fold Cross Validation(记为K-CV)
参考:http://sofasofa.io/forum_main_post.php?postid=1000354&
一般来说,交叉验证会特地说明是用的多少fold。中文一般翻译为折。
一个k-fold cross validation是把训练集随机的分成等数量的k份,每一份数据集轮流当验证集,剩下的k-1的数据集当训练集。因为一共有k个数据集,所以我们就有可以验证k次。我们把这k次的预测精度的平均值当作模型的预测精度。
K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2. 而K-CV 的实验共需要建立 k 个models,并计算 k 次 test sets 的平均辨识率。在实作上,k 要够大才能使各回合中的 训练样本数够多,一般而言 k=10 (作为一个经验参数)算是相当足够了。
下图就是一个4-fold cross validation。我们先把数据随机分成四等份(如果不能被k整除,我们就大概近似k等份)。

下面进行交叉验证。首先是把第1个数据集当作测试集,用2,3,4当作训练集来训练模型,再用训练好的模型来预测数据集1,对比其真实值,得到了一个预测精度。然后再把数据集2当作测试集,用1,3,4训练出一个新的模型,在数据集2上测试,又得到一个预测精度。依此类推,我们就可以得到4个预测精度。将它们取平均值,就得到了模型的4-fold cross validation的预测精度。
优点:K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性.
缺点:K值选取上
3).Leave-One-Out Cross Validation(记为LOO-CV)
方法:如果设原始数据有N个样本,那么LOO-CV就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,所以LOO-CV会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标.
优点:相比于前面的K-CV,LOO-CV有两个明显的优点:a.每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。 b. 实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的.
缺点:计算成本高,因为需要建立的模型数量与原始数据样本数量相同,当原始数据样本数量相当多时,LOO-CV在实作上便有困难几乎就是不显示,除非每次训练分类器得到模型的速度很快,或是可以用并行化计算减少计算所需的时间.
在模式识别与机器学习的相关研究中,经常会将 数据集分为 训练集与测试集 这两个子集,前者用以建立 模式,后者则用来评估该 模式对未知样本进行预测时的精确度,正规的说法是 generalization ability(泛化能力)















 2161
2161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









