






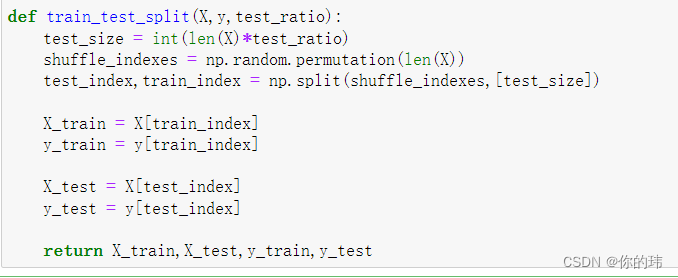
你是否还在这样分离训练集和测试集?
![]()
是否还有这样的?
交叉验证:
我们为什么要用交叉验证?
- 交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表,可以在一定程度上减小过拟合。
- 还可以从有限的数据中获取尽可能多的有效信息。
- 可以选择出合适的模型
今天给大家分享model_selection的交叉验证函数:
1.标准交叉验证

cv决定做几轮交叉验证,这里cv=10,就是十轮然后取均值
2.分折交叉验证

KFold超参数:
n_splits:表示划分几等份
shuffle:在每次划分时,是否进行洗牌(默认为False)
①若为Falses时,其效果等同于random_state等于整数,每次划分的结果相同
②若为True时,每次划分的结果都不一样,表示经过洗牌,随机取样的
random_state:随机种子数
3.分层分折交叉验证
会按照原始类别比例分割数据集

4.留一法交叉验证
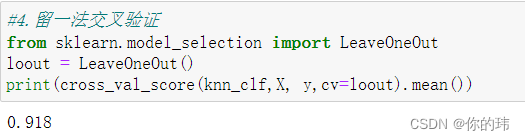
计算时间长,不过结果可靠
5.随机交叉验证,可以控制划分迭代次数
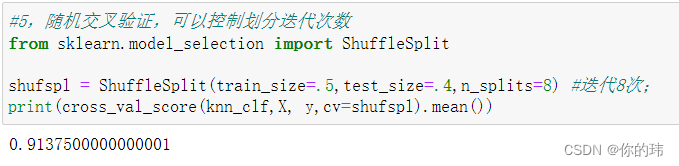
随机排列交叉验证,像train_test_split的升级版,重复分割过程几次,就和交叉验证很像了















 7883
7883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









