







什么是Hive
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 QL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
=Hive是一个数据挖掘工具 ,
非常简单,只要会sql就会hive
为什么不学习pig? -因为pig在国内用的太少了。
=可以将它的一些语句最终转换成MapReduce来计算数据。
MapReduce是不是out了?还用学MapReduce吗?
=现在在大数据领域还没有东西可以替代MapReduce。还没有一个框架来替代Hive。
最早由Facebook提出。
大部分公司都使用Hive,它真是一个神器。
为什么?
答:你写一条语句,它就能给转换成MapReduce。
=语法简直和MySQL是一样的。只不过Hive有它特殊的地方。对MySQL的语法进行扩展。
=Hive是部署在Hadoop集群上的。
属于Hadoop之上的一个框架。
=Hive依赖于HDFS和YARN
运行Hive需要读取数据。读取数据要跟namenode打交道。
读取完数据要启动MapReduce。 进行map和 reduce。
计算完成数据还要写回去HDFS。
什么是Hive
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
Hive的表其实就是HDFS的目录/文件夹,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
=Hive是一个SQL解析引擎。
它将SQL语句转义成M/R Job然后在Hadoop上执行。
=Hive的表——–HDFS的目录/文件夹
=Hive的表中的数据——–HDFS的文件
Hive体系结构
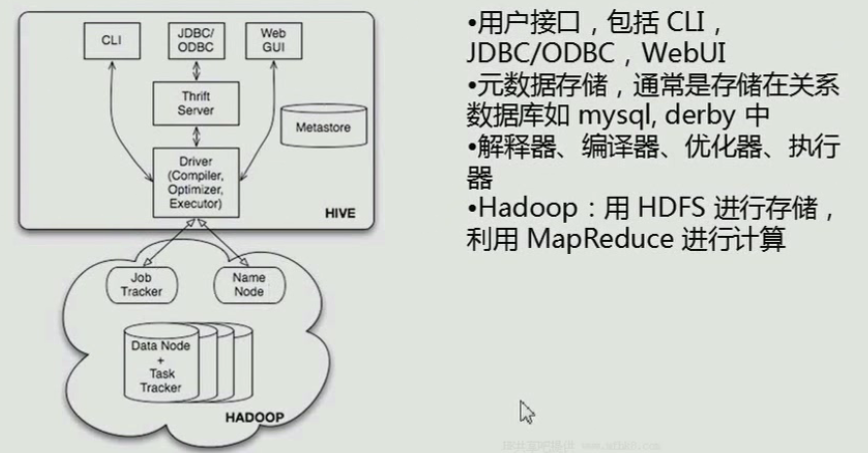
用户接口主要有三个:CLI,JDBC/ODBC和 WebUI
CLI,即Shell命令行
JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似
WebGUI是通过浏览器访问 Hive
Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)
可以通过命令行(CLI)、jdbc/odbc、浏览器来查看。
一般都采用CLI。
jdbc/odbc在高并发方面都存在者一些问题。对并发和连接池支持的不是很好。
Thrift Server 支持很多种语言
Driver(Compiler,Optimizer,Executor):
Compiler:编译器——将sql语句编译成MapReduce。
Optimizer:优化器——优化MapReduce。
Executor:执行器——将MapReduce 丢到Hadoop集群中来执行MapReduce。
Metastroe(元数据库)——存储元数据的一个库。
元数据库中保存表的描述信息。
真正要计算的数据保存在HDFS里。
元数据库 有多中,默认为derby数据库。
实际开发都使用mysql来作为元数据库。
其他概念
数据库:
MySQL、Oracle等。
——特点: 可以实时的进行增删改查
数据仓库:
——特点: 保存大量数据。对仓库中的数据进行分析、计算。
(它主要为了保存数据,保存了之后可以对数据进行分析、计算。一次写入,多次读取。)
——弱点:不会进行实时的更新、删除。(eg:仓库中有一万条数据,有一条数据错了,能不能对这条数据直接进行update?–不能。如果想修改。先把数据下载下来,然后在这个文本中修改。修改完再上传。那么能不能把其中一条删掉?-不能。除非这个文件有就一条数据,我把这个文件删掉。)
ETL
是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库
CLI
命令行界面(英语:command-line interface,缩写:CLI)
总结
Hive是一个数据仓库。
Hive有自己的一套语法——HQL
HQL将语句转化为MapReduce,然后提交到YARN上来执行。
Hive要依赖于HDFS和YARN。(Hadoop1.0中Hive依赖于HDFS和MapReduce)
Hive里面有一些操作它的接口——(CLI、jdbc/odjc、WebUI)——我们用的最多的就是hive的命令行。(hive的CLI)
Hive的数据是存放在HDFS上的。
Hive的表对应HDFS的目录(文件夹)。
Hive要计算的数据也在HDFS。这个数据在这个目录下的文件。
Hive有一个Metastroe——保存表的元数据信息。(包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等)
Hive的基本概念讲完了,
下一节我们来安装一个Hive。















 908
908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









