







给定数组A,大小为n,数组元素为1到n的数字,不过有的数字出现了多次,有的数字没有出现。请给出算法和程序,统计哪些数字没有出现,哪些数字出现了多少次。能够在O(n)的时间复杂度,O(1)的空间复杂度要求下完成么?
该问题来源于:数组统计分析,文中给出的方法非常巧妙,通过简单的整除性质解决了该问题:第一次遍历将每一个位置加上k倍的n,然后第二次遍历将每一个位置除以n即得每个整数出现的次数k。该方法应用的整除原理是:A[i] = x + k*n,其中x<n。
在此我们提出一种另一种方法,比较贴近我们最初的思维方式:交换元素法。在O(1)的空间复杂度要求下,我们只能操作原数组,不能进行新的大于O(1)的空间分配。对原数组进行操作,我们最容易想到的操作即是交换元素,因为元素的交换出现在了所有的原地排序算法中。因为原数组的元素范围为1到n,而且数组长度也为n,所以一个很自然的想法是将元素i放置到位置i,然后我们就可以统计每个元素出现的次数。根据这个思想我们按照如下方式交换元素:遍历n个位置,如果位置i处不满足A[i]=i,则交换A[A[i]]和A[i]两个元素。例如,A[3]=5,则满足A[i] !=i,我们就将A[3]和A[5]交换,交换的结果是A[5]=5,有一个元素在其应该在的位置。
我们希望通过遍历n个位置,通过交换元素的方式使数组达到如下状态:如果元素i出现一次,它就在位置i处;如果元素j出现多次,它除了在位置j处之外,还占据某些其他未出现的元素的位置。例如序列:
| 7 | 6 | 5 | 3 | 5 | 1 | 4 |
我们希望在完成交换之后,达到如下状态:
| 1 | 5 | 3 | 4 | 5 | 6 | 7 |
元素1、3、4、6、7都在其正确位置,元素5除了在位置5以外,还占据了元素2应该出现的位置。
但是不幸的是,我们很快发现上述的遍历方法不能达到上述目的。按照如上方式遍历完之后的序列为:
| 4 | 1 | 3 | 5 | 5 | 6 | 7 |
其中,元素4和1没有在正确位置。
通过研究发现,出现上述问题的原因在于:经过一次交换之后,虽然A[i]处的元素在正确位置,但是i处的元素可能还不在正确位置。解决的方法很简单,只要i处的元素始终能执行交换操作就一直交换,直到不能交换元素为止。此时的伪代码如下:
for i=1:n
while canSwap(i) do swap(i);while循环结束的条件是不能交换,不能交换就说明:要么A[i]=i,要么A[A[i]]=A[i],两个条件的含义是元素i已经在正确位置,或者元素i没有在正确位置,但是其正确位置处已经放置了元素i,这时说明i出现多次。通过将每个位置遍历多次的方式,我们就可以使数组元素达到前述的状态。
正确性证明:我们通过证明按照上述方式交换之后,不存在元素不满足前述状态。首先,如果要交换元素,则每一次交换都会将一个元素放入正确位置,同时不会将之前在正确位置的元素替换掉。这是因为我们在交换元素时必须满足两个条件:A[i]!=i且A[A[i]]!=A[i],第一个条件使我们不交换已经在正确位置的元素,第二个条件使我们在交换的时候满足要交换到的位置尚未放入正确的元素。所以只要满足交换条件,则必定将一个元素放入正确位置,同时不会破坏之前已经在正确位置的元素。由于我们要将n个位置遍历一次,所以会将每个位置不满足前述状态的元素都进行交换,所以遍历完n个位置之后,所有的元素都满足前述状态。
复杂度证明:上述交换操作的复杂度为O(n)。虽然是两层循环,但是该操作的复杂度是O(n)。事实上,上述操作和KMP算法的流程非常相似,所以我们也可以通过平摊分析来证明内层while循环的平摊代价是O(1)。我们通过平摊分析中的聚集分析来证明:如果满足交换条件,则每次都会使一个元素处在正确位置,因为总共有n个元素,所以至多需要n-1次交换(交换完n-1个元素,第n个元素自动满足)即可使所有的元素处在正确位置,也即while循环至多执行O(n)次,每次的平摊代价是O(1)。所以上述交换操作的复杂度为O(n)。
完成交换之后,下一步的操作是统计每个元素出现的次数,我们可以这样完成:遍历一遍数组,将在正确位置的元素变为-1,其他位置不变;然后再次遍历数组,将大于0的元素所在的正确位置减1,同时该位置置零。最后每个位置的绝对值即表示了该位置的元素个数。也即统计元素个数也可以通过O(n)的复杂度完成,因而整个算法的复杂度为O(n)。通过代码优化,可以在一次遍历过程中统计每个元素的次数。
我们将两种不能思路的方式都实现并测试性能,性能差异如下:
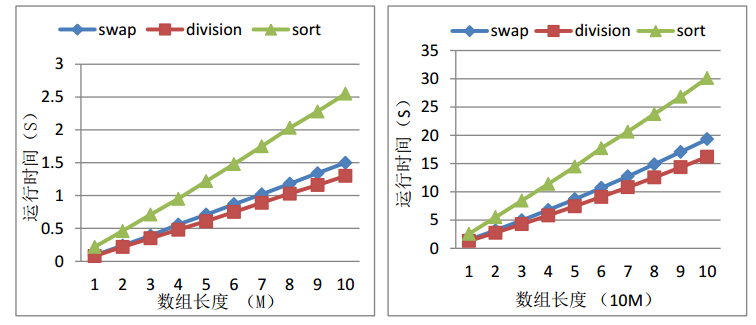
图1 不同的统计方法和排序性能对比(左:小数据;右:大数据)
基于交换的方法我们称其为swap,基于整除的方法我们称其为division,同时为了对比时间,我们将C++的sort方法执行时间也列在图上。通过对比我们发现两种不同的统计方法性能接近,而且满足线性关系,但是基于整除的方法性能稍好,但是它们都比sort的性能高。
测试代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include <math.h>
#include <algorithm>
using namespace std;
#define MAX 100000000
int a[MAX];
int b[MAX];
int c[MAX];
void gen_data(int n)
{
for(int i=0;i<n;i++)
a[i]=rand()%n;
}
void swap(int *a,int *b)
{
int temp=*a;
*a=*b;
*b=temp;
}
void num_count1(int n)
{
for(int i=0;i<n;i++)
{
while(a[i]!=i&&a[a[i]]!=a[i])
{
swap(&a[i],&a[a[i]]);
}
}
for(int i=0;i<n;i++)
{
if(a[i]==i)
a[i]=-1;
else if(a[i]>=0)
{
if(a[a[i]]==a[i])a[a[i]]=-2;
else a[a[i]]--;
a[i]=0;
}
}
}
void num_count2(int n)
{
for(int i=0;i<n;i++)
{
b[b[i]%n]+=n;
}
for(int i=0;i<n;i++)
{
b[i]/=n;
}
}
int main()
{
int n;
clock_t start,end;
srand((unsigned)time(0));
while(scanf("%d",&n)&&n)//input 0 to end, n must <= MAX
{
gen_data(n);
memcpy(b,a,sizeof(int)*n);
memcpy(c,a,sizeof(int)*n);
start=clock();
num_count1(n);
end=clock();
printf("method 1 time:%.3f\n",(double)(end-start)/CLOCKS_PER_SEC);
start=clock();
num_count2(n);
end=clock();
printf("method 2 time:%.3f\n",(double)(end-start)/CLOCKS_PER_SEC);
start=clock();
sort(c,c+n);
end=clock();
printf("sort time:%.3f\n",(double)(end-start)/CLOCKS_PER_SEC);
if(!memcmp(a,b,sizeof(int)*n))
{
printf("error!\n");
return -1;
}
printf("success!\n");
}
return 0;
}














 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









