






摘要
中华文化瑰宝之一的古代诗词,蕴含着丰富情感。传统人工分析古代诗词情感倾向存在效率低、主观性强的问题,难以满足大规模诗词情感分析的需求。文本挖掘技术可从海量文本数据中提取有价值信息,为古代诗词情感倾向分析提供了新途径。基于文本挖掘设计的古代诗词情感倾向分析系统,...
关键词
文本挖掘;古代诗词;情感倾向分析;系统设计
Abstract
Ancient poetry contains rich emotions and is a treasure of Chinese culture. Traditional manual analysis of emotional tendencies in ancient poetry is inefficient and subjective, making it difficult to meet the needs of large-scale emotional analysis of poetr...
Keywords
Text mining; Ancient Chinese poetry; Sentiment tendency analysis; System design
第一章 绪论
中国文化瑰宝之一的古代诗词,蕴含着古人的思想、情感与价值观,具备独特艺术魅力和深厚文化内涵,是中华民族文化遗产的重要构成。随着时间流转,古代诗词丰富的情感与文化信息在传承和理解方面遭遇困难。开展古代诗词情感倾向分析,能够助力更好地了解古人的内心世界,深切感受中...
第二章 系统需求分析
2.1 功能需求分析
系统在数据采集与管理功能上,需从多个渠道收集古代诗词数据,涵盖专业古代文献数据库、古籍数字化平台、图书馆数字馆藏,以及网络诗词论坛和博客等,可借助网络爬虫技术获取。采集的数据常存在格式不统一、有噪声字符等状况,需要进行清洗,去除无用标点和特殊字符,并且开展分词处理。要构建高效数据库存储数据,支持快速...
2.2 性能需求分析
系统在处理诗词数据并分析情感倾向时,对响应时间、准确性、稳定性和可扩展性等方面有着严格要求。响应时间作为衡量系统性能的关键指标,指的是从用户提交分析请求到系统返回结果所经历的时长,会直接影响用户体验。进行实时查询时,系统需在 3 秒内做出响应,以此保证交互的流畅性;批量分析每 100 首诗词所花费的时间不能...
2.3 数据需求分析
古代诗词集在数据来源中占据核心地位,例如《全唐诗》《全宋词》,它们经过了历史的筛选与整理,具备高度的权威性和代表性。古籍文献包含诗词以及诗词的创作背景、相关评论等内容,能够为研究提供丰富的上下文信息。网络资源如诗词网站、数字化图书馆,不仅获取便捷,还包含现代学者的研究成果。研究机构和学者发布的数据集...
2.4 用户需求分析
古代诗词情感倾向分析系统借助文本挖掘技术构建,学生、教师、诗词爱好者等均是其用户群体,不同用户使用系统时需求多样。用户希望能便捷且流畅地浏览海量古诗词,系统需有简洁界面,以合理方式对诗词分类展示,像按朝代、体裁等分类,让用户快速找到感兴趣的诗词类别。用户也有通过作者、朝代、主题等关键词精准搜索诗词的...
第三章 现存问题剖析
3.1 文本预处理难题
古代诗词情感倾向分析系统设计的重要基础是文本预处理,不过这一过程面临诸多难题。古汉语理解存在突出障碍,生僻字词和通假字较为常见。生僻字在现代极少被使用,需要查阅古代文献才能理解其含义,像“垆边人似月”中的“垆”;通假字是用读音相近的字来代替本字,例如“蚤”通“早”,若无法识别就会误解原意。古汉语语法...
3.2 情感词典局限性
情感词典的覆盖范围存在局限,不能涵盖全部情感词汇。历经千年发展的古代诗词,用词表意丰富繁杂,情感表达形式多样。情感词典的构建依托于特定语料库和人工标注,很难将所有表达情感的词汇收录其中。生僻字、古文特有的词汇以及随着时代变迁语义发生变化的词汇,常常被遗漏。“酩酊”一词蕴含着借酒消愁的意思,若情感词典...
3.3 算法适配性问题
语言特性适配难题凸显。古汉语语义理解存在阻碍,古代诗词采用古汉语,其词汇含义和语法结构与现代汉语差异明显。在古代诗词里,“可怜”可能表达可爱之意,这与现代语义大相径庭。现有的文本挖掘算法大多基于现代汉语语料进行训练,难以精准领会古汉语独特的语义,进而导致诗词情感倾向判断出错。诗词语法具有高度灵活性,...
第四章 系统总体设计
4.1 系统架构设计
系统采用分层架构,各层职责清晰。数据存储层承担古代诗词文本及相关数据的存储任务,可选择关系型数据库像 MySQL 或者非关系型数据库如 MongoDB,存储内容包括诗词原始文本、作者信息、创作背景等,同时也存储经过预处理和特征提取后的数据,用于后续分析。数据处理层对数据开展预处理工作,鉴于古代诗词语言和现代...

4.2 模块划分设计
原始古代诗词数据先由数据预处理模块进行初步处理,以此保障后续分析的数据质量。数据来源广泛,从古籍文献、诗词数据库以及网络资源收集,确保数据具有多样性和完整性,能够涵盖不同朝代诗人的作品。对收集到的数据进行清理,去除标点、特殊字符、HTML标签等噪声以及无关信息,同时处理缺失值和重复值。使用专门的古代...
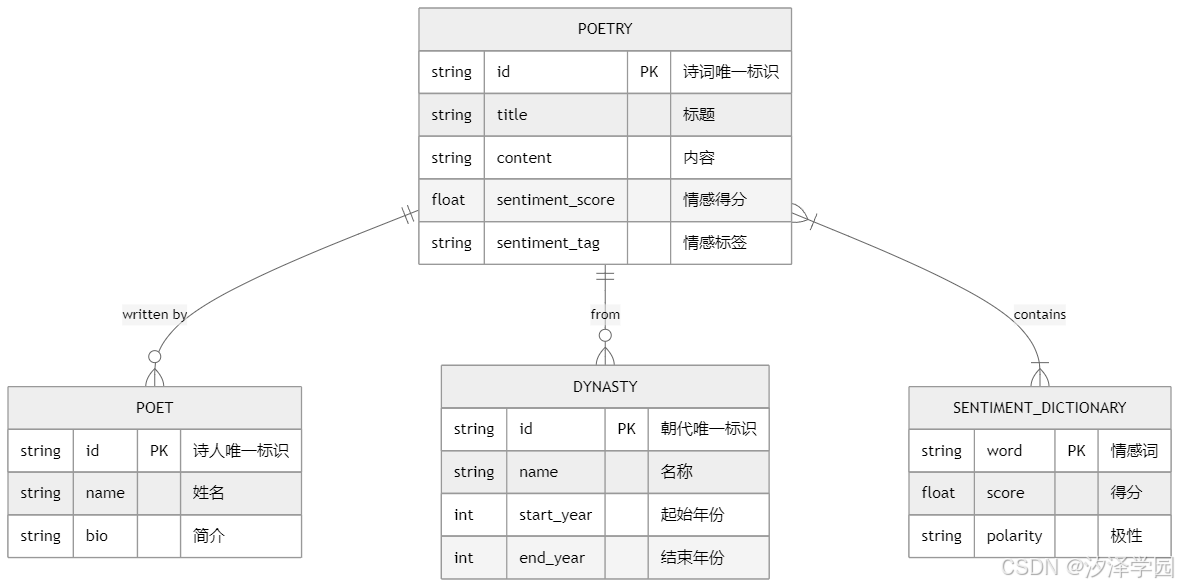
4.3 数据库设计
设计用于分析古代诗词情感倾向系统的数据库,要先明确系统对数据存储和管理的需求。该系统需存储诗词基本信息、内容、情感分析结果,还有诗人、朝代等辅助信息。根据系统规模和性能要求,选择开源的关系型数据库 MySQL。它性能良好、稳定且应用广泛,能够满足数据存储和查询需求。
依据需求分析设计主要数据表。诗词...
第五章 关键技术实现
5.1 文本预处理技术
数据清洗工作中,要去除噪声数据。古代诗词在流传过程里,存在版本差异和抄录错误的情况,需要纠正其中的错别字,依据权威版本修正不同版本间个别字的差异,并且删除电子文档里无法识别的乱码。为避免字符显示错误,要统一字符编码,确保所有诗词文本使用相同编码。处理古代诗词的特殊符号时需谨慎,虽然古代诗词标点的使用...
5.2 情感词典构建
构建情感词典的基础在于语料库选择。为确保情感词典的有效性和泛化能力,需挑选具有强代表性、丰富多样的语料库。古代诗词语料库可从多个经典诗集、诗词总集中获取,这些作品要涵盖不同朝代、风格和主题,从而全面反映各种情感表达。数据预处理是极为关键的步骤。要对语料库文本进行清洗,把特殊符号、注释等干扰信息去除;...
5.3 情感分析算法
情感分析算法的基础步骤是文本预处理。古代诗词具有独特性,需要转化为计算机能够处理的形式。通过数据清洗,去除特殊符号、标点以及噪声信息,使文本变得简洁。采用针对古代汉语的方法或工具对诗词进行分词,将其分割成独立的词语。为词语标注词性进行词性标注,这有助于后续的特征提取和分析。过滤停用词,去除“之”“乎...
第六章 系统测试评估
6.1 测试环境搭建
在硬件环境搭建上,当系统规模较小时,可选用普通台式机或笔记本作为测试服务器。为保证系统能够流畅运行,需选择配置较高的处理器,像Intel Core i7及以上型号,同时配备至少16GB的大容量内存以及512GB及以上的SSD存储空间。要是需要处理大规模诗词数据或者进行复杂算法计算,则要考虑使用专业服务器,例如戴尔P...
6.2 测试用例设计
系统情感分析准确性由功能性测试用例设计从多方面予以保障。情感分类准确性测试涉及正向、负向、中性情感诗词,以杜甫《闻官军收河南河北》检验正向情感判断,用柳永《雨霖铃·寒蝉凄切》测试负向情感识别,借《敕勒歌》验证中性情感判定。特殊情感表达测试针对隐晦和多重情感诗词,考察系统挖掘复杂情感能力,如李商隐《锦...
6.3 评估指标分析
古代诗词情感倾向分析系统测试评估存在几个关键评估指标。系统整体准确性由准确率反映,其为系统正确分类的样本数与总样本数之比,是衡量系统性能的直观指标。但在古代诗词情感分析中,若各类别样本数量不均衡,准确率可能无法真实体现系统对不同情感类别分类的能力。系统对正样本的识别能力由召回率反映,其为系统正确分类...
第七章 结论
系统在对古代诗词进行情感倾向分析时表现出较高的有效性。经过对大量古代诗词样本的测试,发现系统在情感倾向分类方面准确率颇高,能够精准地识别出积极、消极、中性等不同的情感倾向。在处理唐宋诗词测试集时,系统对情感倾向判断的准确率达到了一定比例,这表明系统在处理具有深...
致谢
论文完成之时,内心满溢感激之情。尤其感恩导师,在研究与设计的全程中,导师给予了细致入微的指导与关怀。从确定选题,到完善系统设计思路,再到反复修改论文,导师都投入了大量精力。导师严谨的治学风格、深厚的学识以及敏锐的学术洞察力,引领我在数字人文领域持续探索、不断进步,这些宝贵的品质将让我终身受益。
学...
资料清单
资料包含:论-文,PPT
小绿泡泡:yutiedun_lt


















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











