







 卷积神经网络(CNN)是处理图像、序列数据的重要模型,源于1970年代,由Yann LeCun等人发展。CNN通过卷积层、池化层解决全连接网络的参数过多和局部不变性问题。本文介绍了CNN的历史、整体框架,特别是卷积层的卷积滤波器、局部感受野和参数共享,帮助理解CNN的基础概念和优势。
卷积神经网络(CNN)是处理图像、序列数据的重要模型,源于1970年代,由Yann LeCun等人发展。CNN通过卷积层、池化层解决全连接网络的参数过多和局部不变性问题。本文介绍了CNN的历史、整体框架,特别是卷积层的卷积滤波器、局部感受野和参数共享,帮助理解CNN的基础概念和优势。
前言
卷积神经网络(Convolutional Neural Network,CNN或ConvNet)是一种具有局部连接、权重共享等特性的深层前馈神经网络。卷积神经网络最早可以追溯到1970年代,但目前所说的CNN是源自Yann LeCun等人的工作。
CNN是近年来在计算机视觉领域取得突破性成果的基石,在自然语言处理、推荐系统和语音识别领域广泛使用。首先描述卷积神经网络中的卷积层和池化层的工作原理,并解释填充、步幅、输入通道和输出通道的含义。在掌握这些基础知识后,将展示一个简单的CNN网络实例(Python代码),接着探究几个具有代表性的深度卷积神经网络的设计思路,最后将对最新的关于CNN的论文进行研究和编码学习。
1 历史与问题
卷积神经网络是一种专门用来处理具有类似网络结构的数据的神经网络。例如时间序列数据(可以认为是在时间轴上有规律地采样形成的一维网格)和图像数据(可以看成二维的像素网格)。卷积网络在诸多应用领域都表现优异。“CNN”一词表明该网络使用了卷积(convolution)这种数学运算。卷积是一种特殊的线性运算。卷积网络是指那些至少在网络的一层使用卷积运算来替代一般的矩阵乘法运算的神经网络。
卷积神经网络最早是主要用于处理图像信息。若使用全链接前馈网络来处理图像,会存在以下两个问题:
(1)参数太多:如果输入图像大小为 100 × 100 × 3 100\times 100 \times3 100×100×3(即图像的高度是100,宽度为100,3个颜色通道:RGB)。在全连接前馈神经网络中,第一个隐藏层的每一个神经元都有 100 × 100 × 3 = 30000 100\times 100 \times3 = 30000 100×100×3=30000个相互独立的连接,每个连接都对应这一个权重参数。随着隐藏层神经元的增加,参数的规模也会急剧增加。这导致整个神经网络的训练效率会很低,也易出现过拟合。
(2)局部不变性特征:自然图像处理中的物体具有局部不变性特征,在尺寸缩放、平移、旋转等操作上不影响其语义信息。全连接网络很难提取这些局部不变性特征,一般需要进行数据增强来提高性能。
2 整体框架
CNN由几个基本的层构成,这些层包括输入层、卷积层、池化层、全连接层和输出层所构成,如下图1所示,其模块化的表示如图2所示。输入层、全连接层和输出层工作原理先不叙述,待以后整体叙述时补上。卷积层和池化层是CNN的核心。
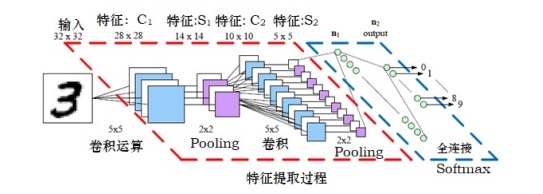
图1 CNN的架构
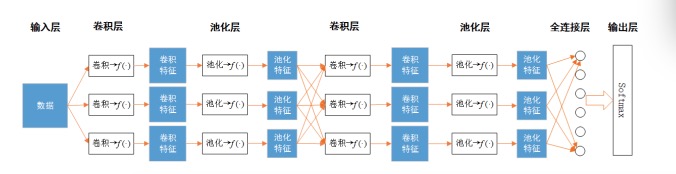
图2 CNN的基本模块
3 卷积层
卷积层是CNN中最重要部分,包含多个特征映射,卷积层中的每个特征映射相当于之前所述网络的节点,特征映射通过卷积运算和激活函数 f ( ⋅ ) f(\cdot) f(⋅)将输入映射为卷积特征。每个特征映射可接收一个或多个前层特征输入,并包含与特征输入数目相同的卷积滤波器(也称为卷积核)。这些卷积滤波器与输入时行卷积运算,然后将结果通过激活函数后,输出卷积特征。
3.1 卷积与卷积滤波器
当以 2 − D 2-D 2−D特征 a a a作为输入时,卷积滤波器 w w w是二维的矩阵。令输入特征 a a a和卷积滤波器 w w w分别为
a = ( 1 3 0 − 1 − 2 0 3 2 2 − 3 − 1 4 4 2 0 1 ) w = ( 3 − 1 0 2 ) a = \begin{pmatrix} 1 & 3 & 0 & -1 \\ -2 & 0 & 3 & 2 \\ 2 & -3 & -1 & 4 \\ 4 & 2 & 0 & 1 \end{pmatrix} w = \begin{pmatrix} 3 & -1 \\ 0 & 2 \end{pmatrix} a=⎝⎜⎜⎛1−22430−3203−10−1241⎠⎟⎟⎞w=(30−12)
进行卷积运算时,先对滤波器 w w w进行 18 0 ∘ 180^{\circ} 180∘翻转,得到
w ~ = ( 2 0 − 1 3 ) \tilde{w} = \begin{pmatrix} 2 & 0 \\-1 & 3 \end{pmatrix} w~=(2−103)
然后按照图3所示进行计算
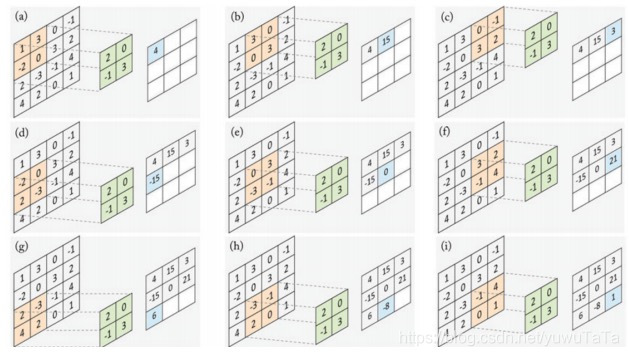
图3 卷积计算过程
卷积运算就是 a ∗ w a*w a∗w的过程,计算过程展示如下
( 1 3 0 − 1 − 2 0 3 2 2 − 3 − 1 4 4 2 0 1 ) ∗ ( 3 − 1 0 2 ) = ( 4 15 3 − 15 0 21 6 − 3 1 ) \begin{pmatrix} 1 & 3 & 0 & -1 \\ -2 & 0 & 3 & 2 \\ 2 & -3 & -1 & 4 \\ 4 & 2 & 0 & 1 \end{pmatrix} * \begin{pmatrix} 3 & -1 \\ 0 & 2 \end{pmatrix} = \begin{pmatrix} 4 & 15 & 3 \\-15 & 0 & 21 \\6 & -3 & 1 \end{pmatrix} ⎝⎜⎜⎛1−22430−32
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









