






一、.view()、.size()
1.view()
是 PyTorch 中用于重塑张量形状的方法。它返回一个新的张量,与原张量共享数据,但形状不同。通常用来对特征进行展平操作。功能类似于 NumPy 中的 reshape() 方法。
参数说明:.view(new_shape):new_shape 是一个元组或一个张量,用于指定新张量的形状。其中的每个维度可以是具体的大小,也可以是 -1,表示根据其他维度的大小自动推断该维度的大小。
注意事项:
- 调用
.view()后,返回的新张量与原始张量共享内存,因此在新张量上的操作可能会影响原始张量。 - 如果
new_shape中存在-1,则会自动推断该维度的大小,但是只能有一个维度被设置为-1,否则会引发错误。
2.size()
是 PyTorch 中用于获取张量维度信息的方法。这个方法返回一个包含张量各维度大小的元组(tuple)。它通常用于检查张量的形状,或者在需要动态获取张量尺寸的情况下使用。
注意事项:
.size()返回的是一个元组,可以使用索引访问具体维度的大小,也可以通过循环遍历获取所有维度的大小。.size(dim)可以指定维度来获取该维度的大小。- PyTorch 中的
.size()方法与 NumPy 中的.shape属性类似,用于获取张量的形状信息。 - 在pytorch中,.size()和.shape的用法是等价的,它们都返回张量的尺寸信息。
举例
假设 x 的形状为 (batch_size, channels, height, width),例如 (32, 3, 224, 224)。
在这种情况下,调用 x.view(x.size(0), -1) 的作用如下:
这会将 x 的形状从 (32, 3, 224, 224) 变为 (32, 3*224*224),即 (32, 150528)。这里150528是由3*224*224计算得到的。重塑后的张量 reshaped_x 仍然包含 32 个样本,每个样本有150528个特征。
x.size(0): 获取张量 x 的第一个维度的大小,通常是批次大小(batch size)。
-1: 这是一个特殊值,表示这个维度的大小将根据其他维度的大小自动推算出来。它可以帮助我们自动计算维度,从而使得总的元素数量保持不变。
import torch
x = torch.randn(32,3,224,224)
print(x.size())
# 输出为torch.Size([32, 3, 224, 224])
print(x.size(1))
# 输出为3
y = x.view(x.size(0),-1) #展平操作
print(y.size())
# 输出为torch.Size([32, 150528])使用场景
在神经网络中,通常在卷积层后面使用全连接层(fully connected layer)。卷积层的输出通常是一个多维特征图,而全连接层需要输入一维向量。因此,需要使用 .view() 方法将多维特征图展平成一维向量。
二、.permute()
.permute() 方法用于对张量的维度进行重新排列,返回一个新的张量,其维度顺序按照参数指定的顺序重新排列。
如x的形状为(B,C,H,W),y = x.permute(0,2,3,1),则x的形状变为(B,H,W,C)
注意事项
.permute()返回的是一个新的张量,不会改变原始张量的维度顺序。- 参数是一个维度索引的元组,表示按照指定的顺序重新排列张量的维度。
.permute()方法通常用于将张量从一种维度顺序转换为另一种维度顺序,常用于深度学习中的数据处理和模型操作。
import torch
x = torch.randn(32,3,224,224)
y = x.permute(0,2,1,3)
print(y.size())
# 输出为torch.Size([32, 224, 3, 224])三、torch.cat()
在PyTorch 中用于沿指定维度连接两个或多个张量的方法。这个函数对于将多个张量合并成一个更大的张量非常有用,特别是在处理多尺度特征或将多个特征图拼接在一起时。
torch.cat(tensors, dim=0)tensors:一个包含待连接张量的列表或元组。dim:指定要沿哪个维度进行连接。
举例:
import torch
# 创建两个形状相同的张量
x = torch.randn(2, 3)
y = torch.randn(2, 3)
# 沿第0维度(行)连接张量
z = torch.cat((x, y), dim=0)
print(z.size())
# 输出为torch.Size([4, 3])
# 沿第1维度(行)连接张量
z = torch.cat((x, y), dim=1)
print(z.size())
# 输出为torch.Size([2, 6])四、torch.nn.functional.interpolate()
是 PyTorch 中的一个用于上采样(放大)张量的函数,取代原来的.upsample()
torch.nn.functional.interpolate(input,
size=None,
scale_factor=None,
mode='nearest',
align_corners=None,
recompute_scale_factor=None,
antialias=False)参数详解
input:输入张量,通常为 4D(N, C, H, W)或 5D(N, C, D, H, W)
size:目标输出的尺寸。可以是一个整数或一个整数元组,表示输出的高度和宽度(对于 4D 输入)或深度、高度和宽度(对于 5D 输入)。
scale_factor:缩放因子。如果设置了 size,则 scale_factor 应该为 None。
mode:插值模式。常用模式包括 'nearest'(最近邻插值)、'linear'(线性插值,仅限于 3D 张量)、'bilinear'(双线性插值,常用于 4D 张量)、'bicubic'(双三次插值)和 'trilinear'(三线性插值,常用于 5D 张量),Default: 'nearest'。
align_corners:如果为 True,输入和输出张量的角像素对齐。这通常影响插值结果,特别是对于 bilinear 和 trilinear 模式。
详见:torch.nn.functional.interpolate — PyTorch 2.3 documentation
import torch
import torch.nn.functional as F
# 假设 input 是一个形状为 (N, C, H, W) 的 4D 张量
input = torch.randn(1, 3, 24, 24)
# F.upsample 的旧用法(不推荐)
output = F.interpolate(input, size=(48, 48), mode='bilinear') # 双线性插值
print(output.shape) # 输出: torch.Size([1, 3, 48, 48])五、torch.randn()、torch.rand()、torch.zeros()、torch.bmm()
1.torch.randn()
返回一个张量,其中充满来自均值为0,方差为1的正态分布(也称为标准正态分布)的随机数。
torch.randn(*size,
*,
generator=None,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False,
pin_memory=False)import torch
x = torch.randn(4)
print(x)
# tensor([-0.5168, 1.0305, -0.8989, -0.8135])
y = torch.randn(2, 4)
print(y)
# tensor([[-0.0997, 0.8106, 2.3443, -1.4624],
[ 0.5994, 0.5576, -1.4681, -1.2033]])2.torch.rand()
返回一个由区间[0,1)上均匀分布的随机数填充的张量。
torch.rand(*size,
*,
generator=None,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False,
pin_memory=False)import torch
x = torch.rand(4)
print(x)
# tensor([0.2099, 0.6615, 0.8233, 0.7062])
y = torch.rand(4, 4)
print(y)
# tensor([[0.1887, 0.2547, 0.2217, 0.2088],
[0.6738, 0.5339, 0.3027, 0.0226],
[0.3196, 0.8840, 0.1084, 0.6806],
[0.2702, 0.4626, 0.8536, 0.6016]])3.torch.zeros()
返回一个用标量值0填充的张量。
torch.zeros(*size,
*,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False)import torch
x = torch.zeros(5)
print(x)
tensor([0., 0., 0., 0., 0.])
y = torch.zeros(2, 3)
print(y)
tensor([[0., 0., 0.],
[0., 0., 0.]])4.torch.bmm()
对存储在输入和 mat2 中的矩阵执行批量矩阵-矩阵乘积。
torch.bmm(input,
mat2,
*,
out=None)import torch
input = torch.randn(10, 3, 4)
mat2 = torch.randn(10, 4, 5)
res = torch.bmm(input, mat2)
print(res.size())
# torch.Size([10, 3, 5])六、模型解读(以PAFEM为例)
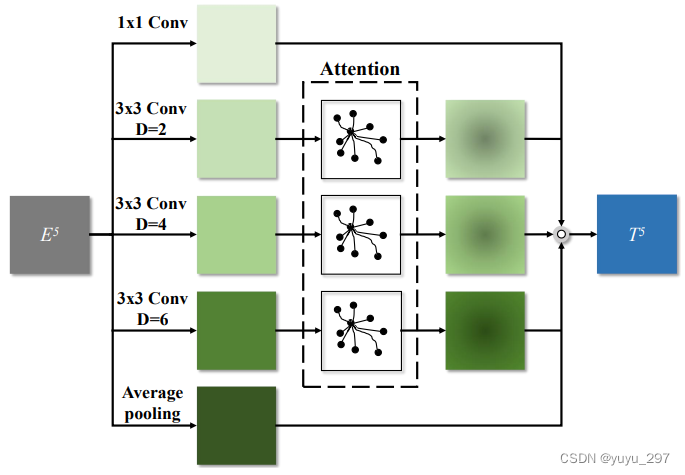
图片来源于:https://arxiv.org/abs/2007.06811
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Conv2d, Softmax, Parameter
class PAFEM(nn.Module):
def __init__(self, dim,in_dim):
super(PAFEM, self).__init__()
# 用于将输入从dim变为in_dim
self.down_conv = nn.Sequential(nn.Conv2d(dim,in_dim , 3,padding=1),nn.BatchNorm2d(in_dim),
nn.PReLU())
down_dim = in_dim // 2
self.conv1 = nn.Sequential(
nn.Conv2d(in_dim, down_dim, kernel_size=1), nn.BatchNorm2d(down_dim), nn.PReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=2, padding=2), nn.BatchNorm2d(down_dim), nn.PReLU()
)
self.query_conv2 = Conv2d(in_channels=down_dim, out_channels=down_dim//8, kernel_size=1)
self.key_conv2 = Conv2d(in_channels=down_dim, out_channels=down_dim//8, kernel_size=1)
self.value_conv2 = Conv2d(in_channels=down_dim, out_channels=down_dim, kernel_size=1)
self.gamma2 = Parameter(torch.zeros(1))
self.conv3 = nn.Sequential(
nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=4, padding=4), nn.BatchNorm2d(down_dim), nn.PReLU()
)
self.query_conv3 = Conv2d(in_channels=down_dim, out_channels=down_dim//8, kernel_size=1)
self.key_conv3 = Conv2d(in_channels=down_dim, out_channels=down_dim//8, kernel_size=1)
self.value_conv3 = Conv2d(in_channels=down_dim, out_channels=down_dim, kernel_size=1)
self.gamma3 = Parameter(torch.zeros(1))
self.conv4 = nn.Sequential(
nn.Conv2d(in_dim, down_dim, kernel_size=3, dilation=6, padding=6), nn.BatchNorm2d(down_dim), nn.PReLU()
)
self.query_conv4 = Conv2d(in_channels=down_dim, out_channels=down_dim//8, kernel_size=1)
self.key_conv4 = Conv2d(in_channels=down_dim, out_channels=down_dim//8, kernel_size=1)
self.value_conv4 = Conv2d(in_channels=down_dim, out_channels=down_dim, kernel_size=1)
self.gamma4 = Parameter(torch.zeros(1))
self.conv5 = nn.Sequential(
nn.Conv2d(in_dim, down_dim, kernel_size=1),nn.BatchNorm2d(down_dim), nn.PReLU() #如果batch=1 ,进行batchnorm会有问题
)
self.fuse = nn.Sequential(
nn.Conv2d(5 * down_dim, in_dim, kernel_size=1), nn.BatchNorm2d(in_dim), nn.PReLU()
)
self.softmax = Softmax(dim=-1)
def forward(self, x):
x = self.down_conv(x)
conv1 = self.conv1(x)
conv2 = self.conv2(x)
m_batchsize, C, height, width = conv2.size()
proj_query2 = self.query_conv2(conv2).view(m_batchsize, -1, width * height).permute(0, 2, 1)
proj_key2 = self.key_conv2(conv2).view(m_batchsize, -1, width * height)
energy2 = torch.bmm(proj_query2, proj_key2)
attention2 = self.softmax(energy2)
proj_value2 = self.value_conv2(conv2).view(m_batchsize, -1, width * height)
out2 = torch.bmm(proj_value2, attention2.permute(0, 2, 1))
out2 = out2.view(m_batchsize, C, height, width)
out2 = self.gamma2* out2 + conv2
conv3 = self.conv3(x)
m_batchsize, C, height, width = conv3.size()
# .view(m_batchsize, -1, width * height) 将(B,C,H,W)变为(B,C,HxW)
# .permute(0, 2, 1) 将(B,C,HxW)变为(B,HxW,C)
# 所以q的形状为(B,HxW,C)
proj_query3 = self.query_conv3(conv3).view(m_batchsize, -1, width * height).permute(0, 2, 1)
# k的形状为(B,C,HxW)
proj_key3 = self.key_conv3(conv3).view(m_batchsize, -1, width * height)
# q和k相乘,形状变为(B,HxW,HxW)
energy3 = torch.bmm(proj_query3, proj_key3)
attention3 = self.softmax(energy3)
# v的现状为(B,C,HxW)
proj_value3 = self.value_conv3(conv3).view(m_batchsize, -1, width * height)
out3 = torch.bmm(proj_value3, attention3.permute(0, 2, 1))
out3 = out3.view(m_batchsize, C, height, width)
out3 = self.gamma3 * out3 + conv3
conv4 = self.conv4(x)
m_batchsize, C, height, width = conv4.size()
proj_query4 = self.query_conv4(conv4).view(m_batchsize, -1, width * height).permute(0, 2, 1)
proj_key4 = self.key_conv4(conv4).view(m_batchsize, -1, width * height)
energy4 = torch.bmm(proj_query4, proj_key4)
attention4 = self.softmax(energy4)
proj_value4 = self.value_conv4(conv4).view(m_batchsize, -1, width * height)
out4 = torch.bmm(proj_value4, attention4.permute(0, 2, 1))
out4 = out4.view(m_batchsize, C, height, width)
out4 = self.gamma4 * out4 + conv4
conv5 = F.upsample(self.conv5(F.adaptive_avg_pool2d(x, 1)), size=x.size()[2:], mode='bilinear') # 如果batch设为1,这里就会有问题。
return self.fuse(torch.cat((conv1, out2, out3,out4, conv5), 1))














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









