







基于距离的分类
给定一个数据库 D={t1,t2,…,tn}和一组类C={C1,…,Cm},则分类问题是要分配每个ti到满足如下条件的类Cj:sim(ti,Cj) >= sim(ti,Cl) ,任取Cl∈C,Cl≠Cj,其中sim(ti,Cj)被称为相似度
分类思想:把数据分到距离最近(相似度最高)的类别去
难处:需要计算每个类别的中心
基础算法
算法思想:每个元组与各类中心计算距离,寻找距离最小的中心归入那一类
输入:每个类的中心c1,…, cm;待分类的一个元组t。
输出:输出类别c。
(1)dist =∞;//距离初始化
(2)FOR i =1 to m DO
(3) IF dist(ci,t) < dist THEN BEGIN
(4) ci← t;
(5) dist←dist(ci,t);
(6) END.
k-近邻分类算法
k-近邻分类算法:k-Nearest Neighbors ,KNN
算法思想:通过计算每个训练数据到待分类元组的距离,取和待分类元组距离最近的k个训练数据,k个数据中哪个类别的训练数据占多数,则待分类元组就属于哪个类别。
可以先用基础算法分类,再按k个近邻的多数类别进行分类
难点:找各个类别中心,如何将语义的属性差距转化成数字距离描述,找待分类元组的k个近邻元组
输入:训练数据T ;近邻数目k ;待分类的元组t。
输出:输出类别c。
下面的算法是找k个最近邻的
(1) N = 空集;
(2)FOR each d ∈T DO BEGIN
(3) IF | N | ≤ k THEN
(4) N = N ∪{d}; //先把输出k个归为最近邻
(5) ELSE
(6) IF 存在u ∈N such that sim(t,u) < sim(t,d) THEN BEGIN
(7) N = N - {u}; //一旦发现有更近的,就把现在最近邻集合里最远的踢掉
(8) N = N ∪{d};
(9) END
(10)END
(11)c = class to which the most u ∈N.
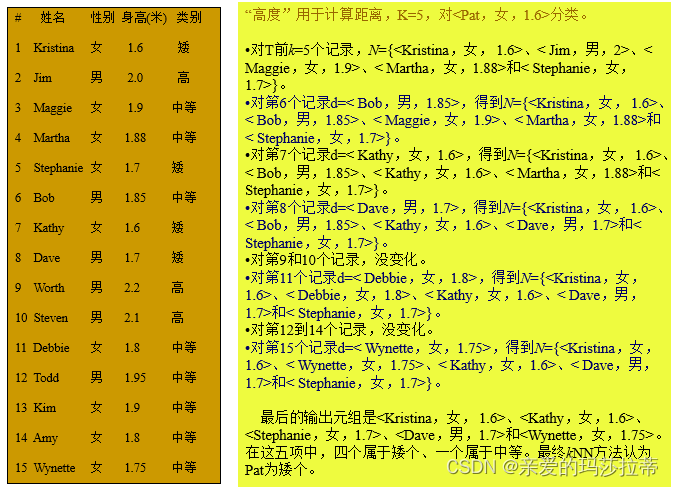
计算元组间距离:

举例:















 3412
3412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









