






 本文介绍了一个开源项目,教你如何下载资源、安装依赖,使用MP3音频训练模型,以及通过WebUI操作进行声音克隆和唱歌。尽管存在电音效果,项目提供了一种基础的语音合成体验,还需后续调试优化。
本文介绍了一个开源项目,教你如何下载资源、安装依赖,使用MP3音频训练模型,以及通过WebUI操作进行声音克隆和唱歌。尽管存在电音效果,项目提供了一种基础的语音合成体验,还需后续调试优化。
文章目录
前言
使用开源项目实现克隆自己的声音唱任何歌曲
类似AI孙燕姿,AI范小勤的项目
一、环境准备
1.1 从github下载资源包
1)点击release
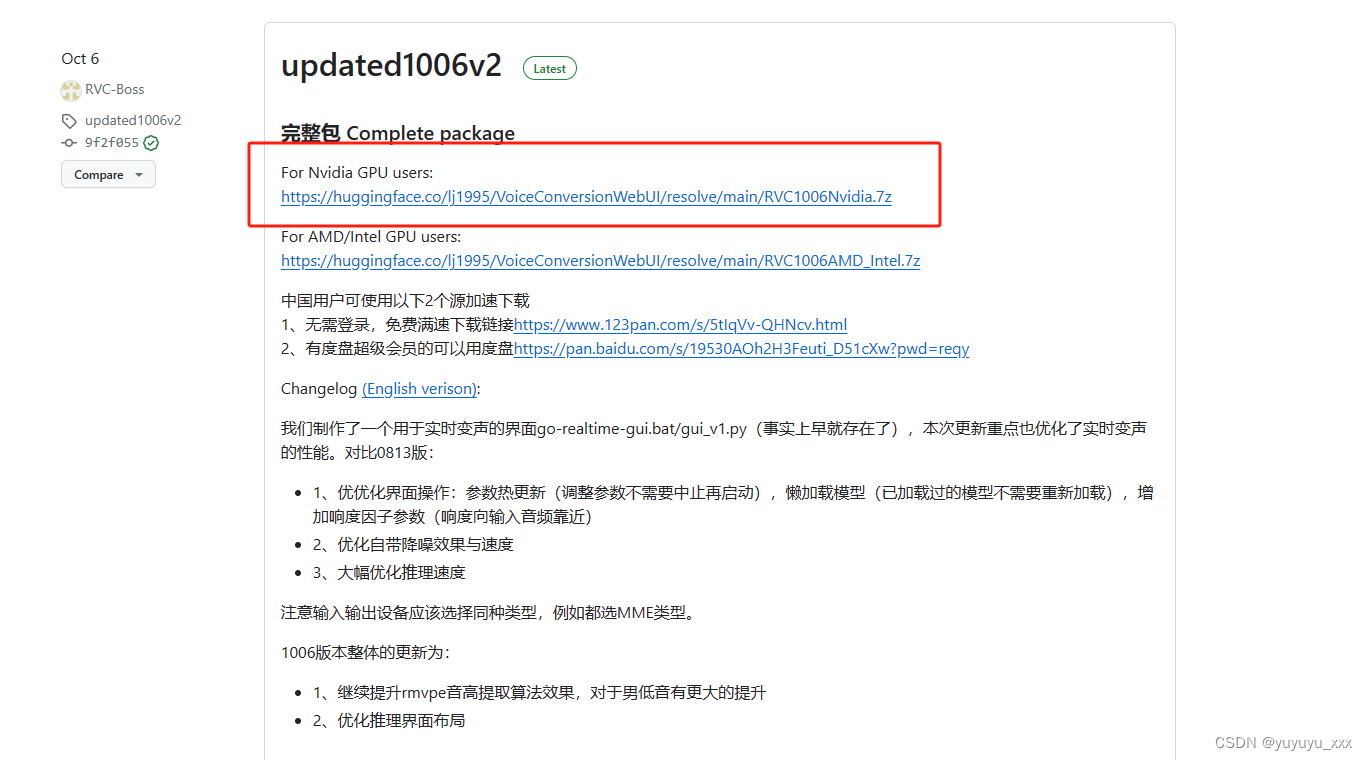
2)从此跳转到HGF中下载资源包
若是没有梯子,可通过HGF的镜像网站下载
1.2 解压压缩包安装依赖
3)解压.7z压缩包

4)根据需要安装依赖
pip install -r requirements.txt
同时需要根据自身情况,缺什么包就再补充安装什么包
比如 缺 ffmpeg 就 conda install ffmpeg 安装
二、启动环境
2.1 启动程序
python infer-web.py

2.2 根据链接跳转到webui界面

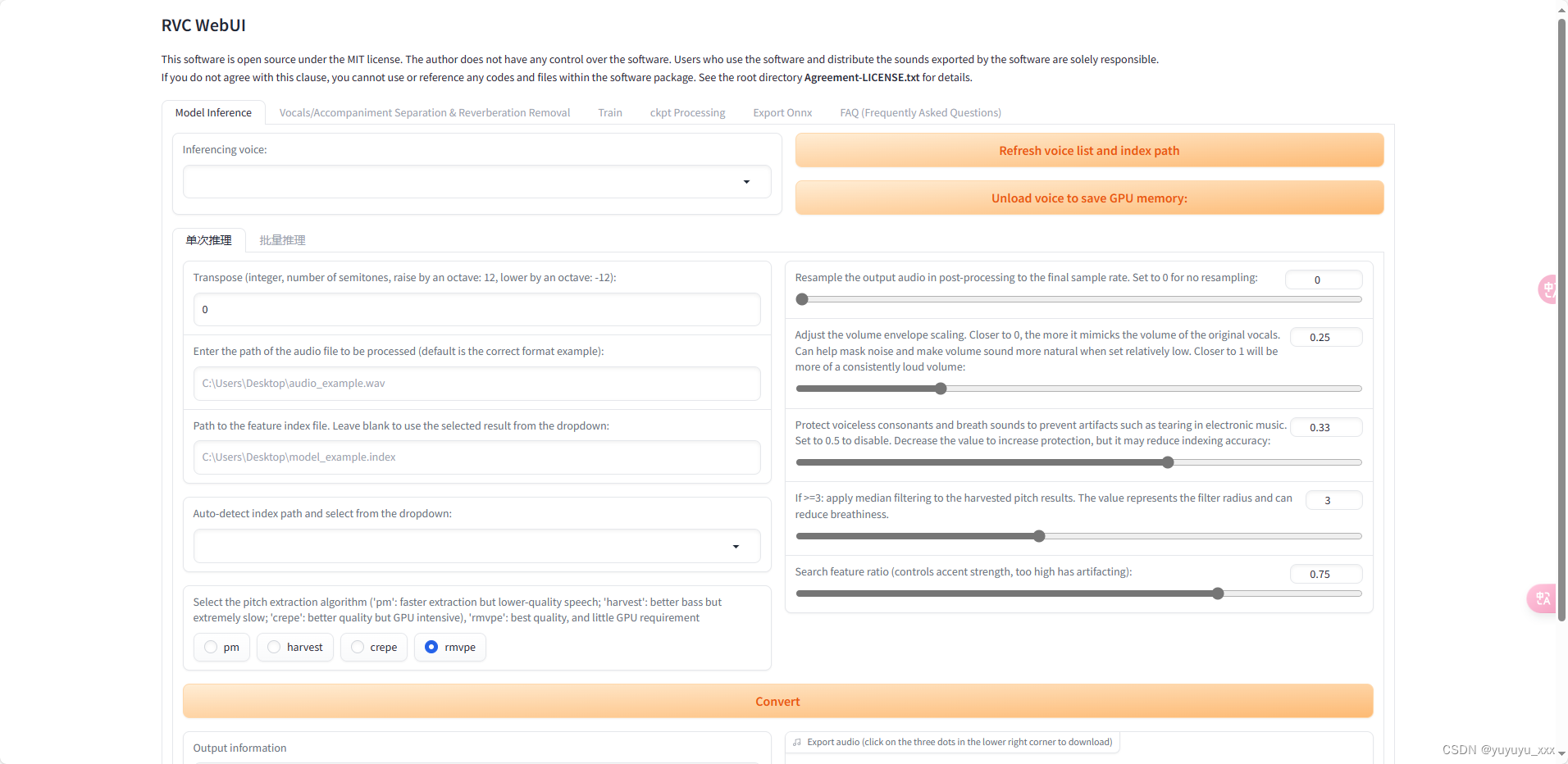
三.训练模型
3.1 准备10分钟自己朗读的音频格式为MP3
3.2 准备自己想要克隆声音过去的歌曲格式也是MP3
可从油管复制视频链接到该网站进行制作转换
3.3 训练模型
1)预处理音频
指定文件名,设置自己录的音频位置
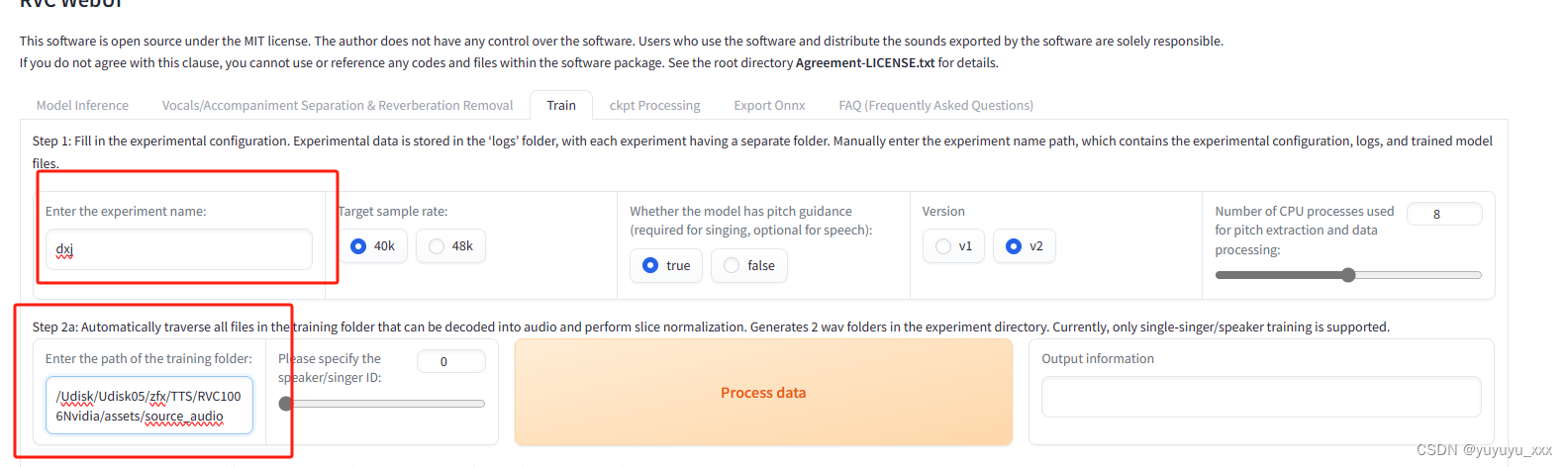
点击process data

完成
- 提取特征
使用图中选项或者使用默认


3)训练模型
按图中设置
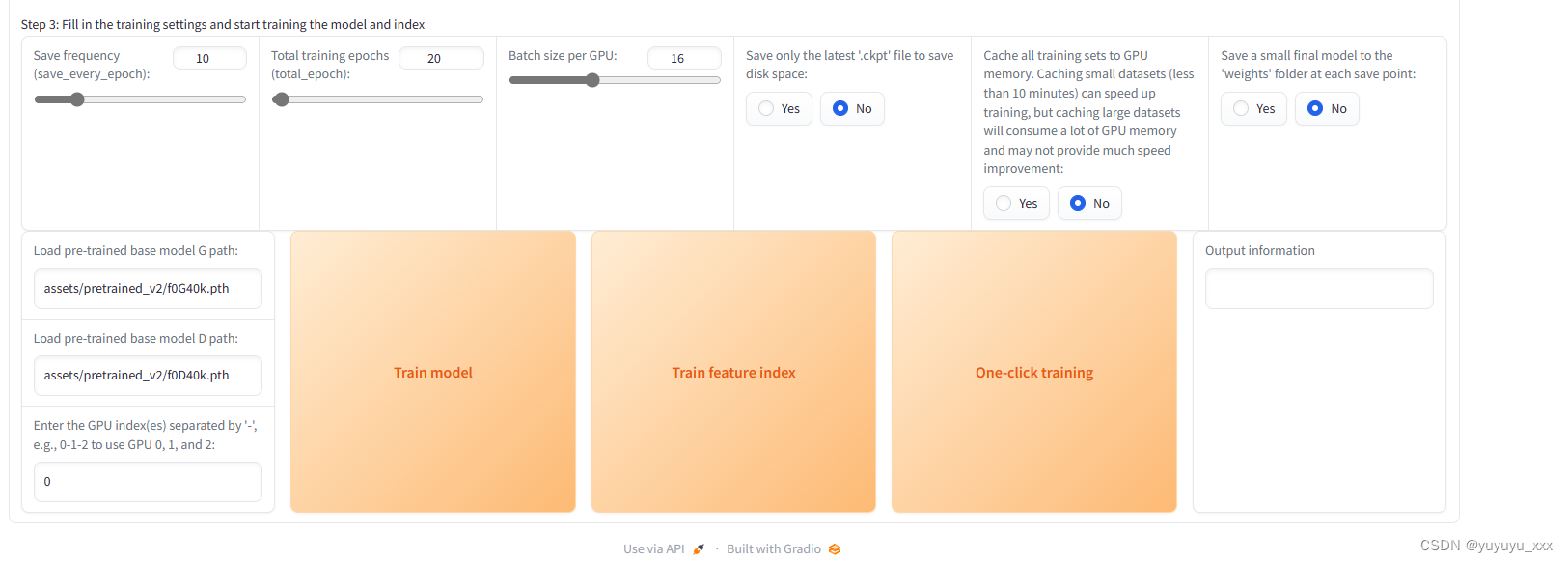
然后点击 train model


再点击 train feature index

四 推理 用自己的声音唱歌
4.1 刷新推理模型并选择
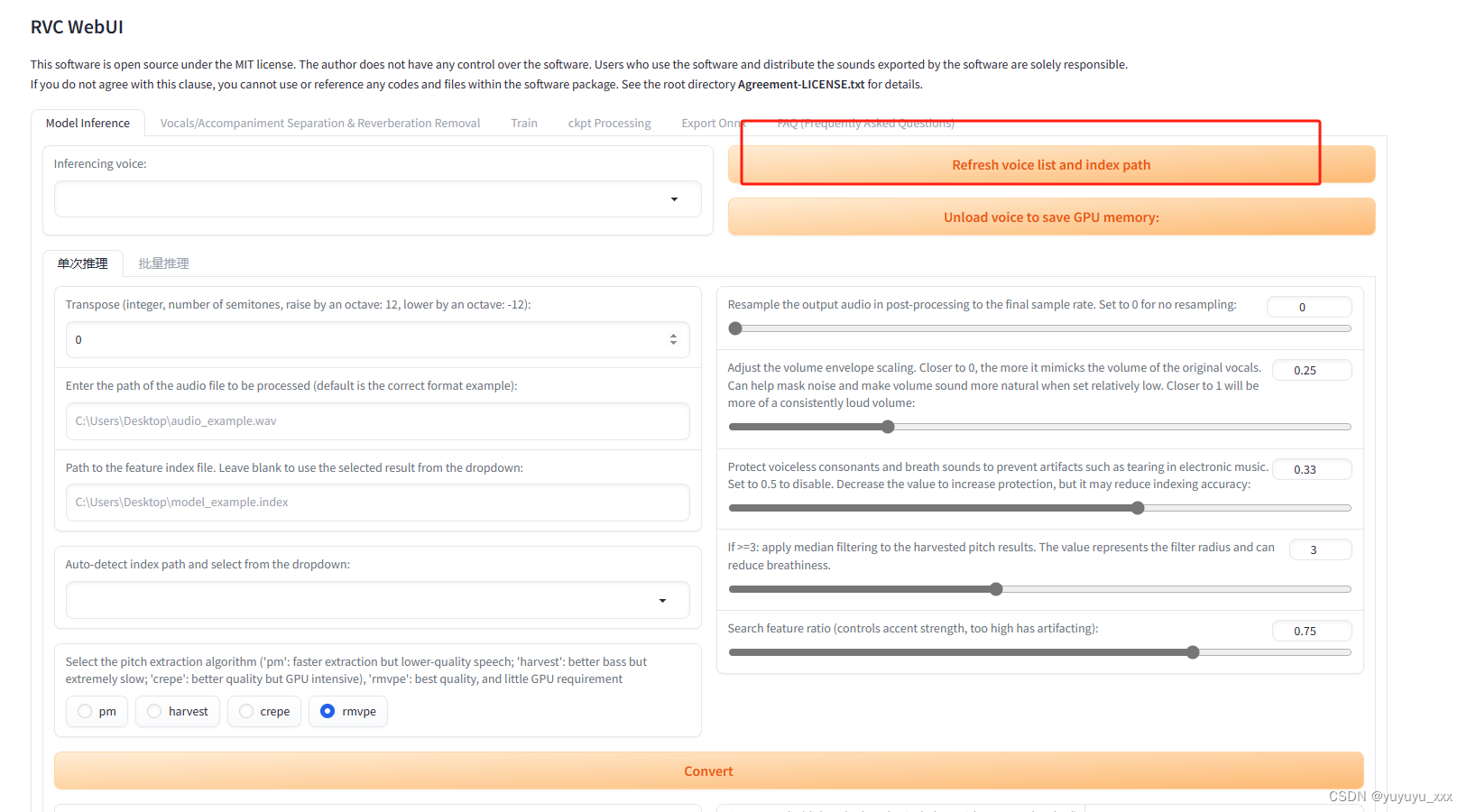
4.2 预处理要唱的歌曲
按图中设置即可
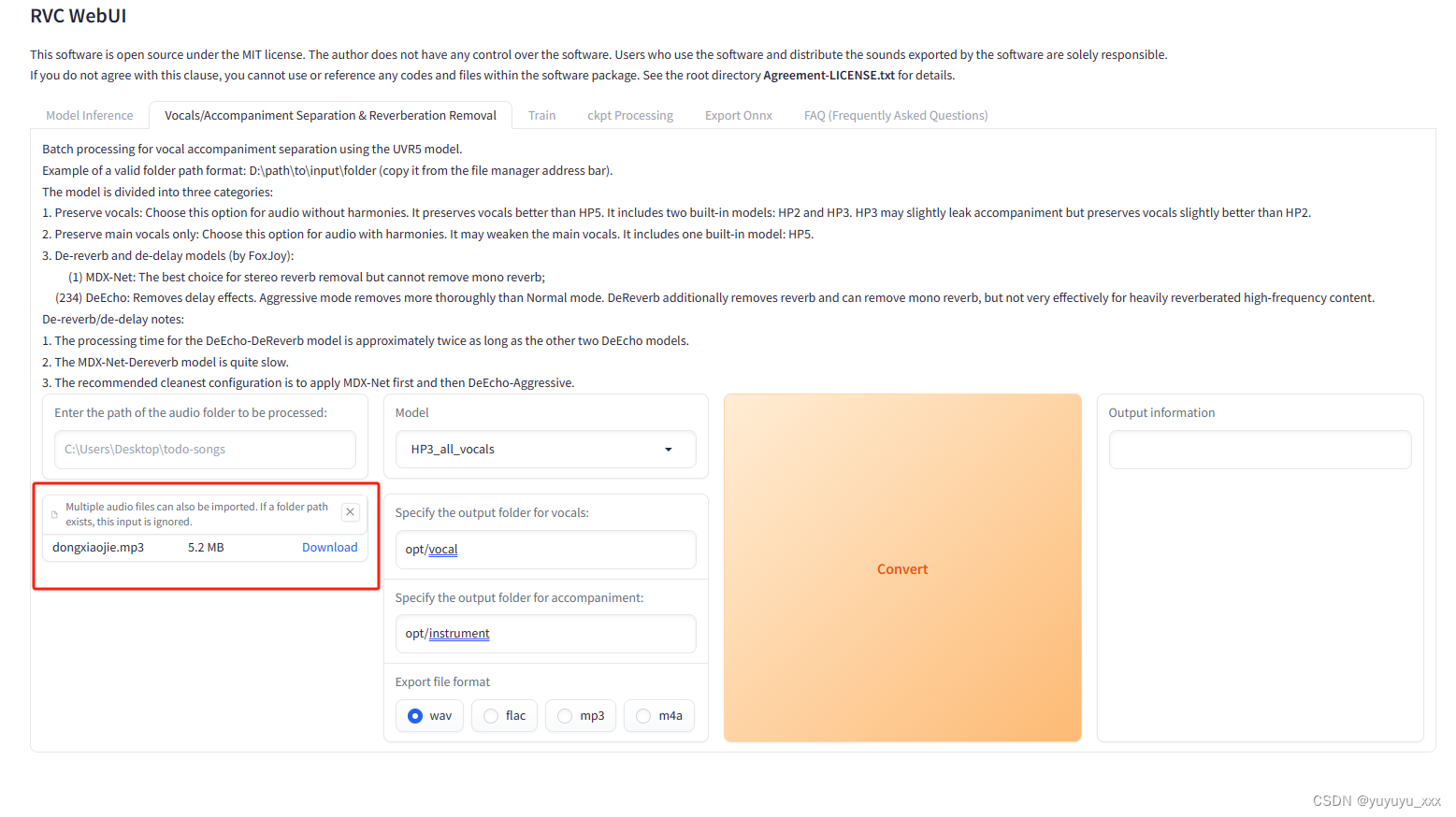
点击convet 就会有 声音 和 背景音乐 两个文件

注意名字不能有中文
4.3 模型推理
1)选择对应模型和index

2)放入指定的音色点击convert
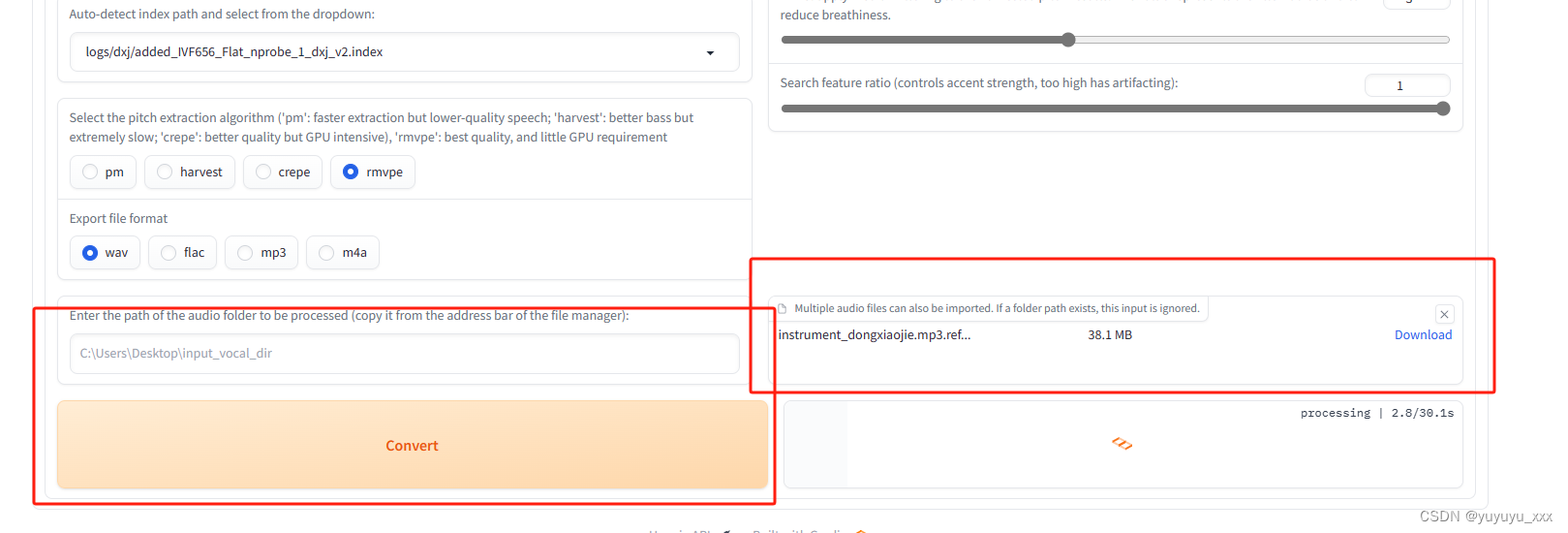
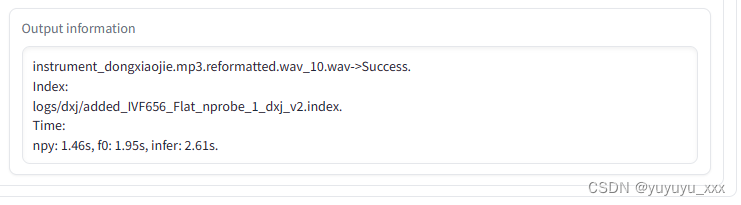
3)完成推理
若感觉声音太尖了修改下图中的值,降到-8再进行推理,声音会更低

总结
效果可用,但是会带着电音,还需要后续进行更多的调试

















 5479
5479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









