










快速排序是排序算法中效率相对较高的,但使用的人却是比较少,大家一般信手拈来的排序算法就是冒泡排序。因为冒泡排序主观,容易理解,而快速排序使用到了递归,大家可能就有点不知所措了。
算法分析
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
我看了下网上有些bolg写排序算法,有的是理解错误了;有的呢是太过于复杂;还有的呢就干脆是用临时数组,而不是就地排序。当然我的也并没有多好,只是提够一种思路;
说说我的基本思路:每次都取数组的第一个元素作为比较标准(哨兵元素),凡是大于这个哨兵元素的都放在它的右边,凡是小于这个哨兵元素的都放在它的左边;
大概的步骤:
1、判断参数条件,其实这是递归的出口;
2、以数组的第一个元素为哨兵元素,让其他元素和它比较大小;(记住这时候第一个元素位置是口的,因为里面的值被作为哨兵元素保存起来了)
3、开始从数组尾部往前循环得到一个小于哨兵元素的 元素A ,把该 元素A 放到第一个元素位置(也就是哨兵元素位置上,因为哨兵元素位置是空的);(这时候要记住 元素A 的位置是空的了)
4、开始从数组头部往后循环得到一个大于哨兵元素的 元素B ,把该 元素B 放在上一步中移出的 元素A 的位置上;
5、依次循环上面3、4步,直到最后一个元素为止,那么最后一个元素就存放哨兵元素了。
6、把小于哨兵元素的那一部分和大于哨兵元素的那一部分分别递归调用本函数,依次递归排序好所有元素;
实现代码
代码部分:
#include<stdio.h>
// 打印数组
void print_array(int *array, int length)
{
int index = 0;
printf("array:\n");
for(; index < length; index++){
printf(" %d,", *(array+index));
}
printf("\n\n");
}
void quickSort(int array[], int length)
{
int start = 0;
int end = length-1;
int value = array[start];// 得到哨兵元素
if (1 > length) return;// 递归出口
while(start < end){// 以哨兵元素为标准,分成大于它和小于它的两列元素
while(start < end){// 从数组尾部往前循环得到小于哨兵元素的一个元素
if ( array[end--] < value ){
array[start++] = array[++end];
break;
}
}
while( start < end ){// 从数组头部往后循环得到大于哨兵元素的一个元素
if( array[start++] > value){
array[end--] = array[--start];
break;
}
}
}
array[start] = value;// 放置哨兵元素
printf("\nstart:%d, end:%d\n", start, end);// 这个是测试下start和end是否一样
quickSort(array, start);// 递归排序小于哨兵元素的那一列元素
quickSort(array + start + 1, length - start - 1);// 递归排序大于哨兵元素的那一列
}
int main(void)
{
int array[12] = {1,11,12,4,2,6,9,0,3,7,8,2};
print_array(array, 12);// 开始前打印下
quickSort(array, 12);// 快速排序
print_array(array, 12);// 排序后打印下
return 0;
}
运行结果:
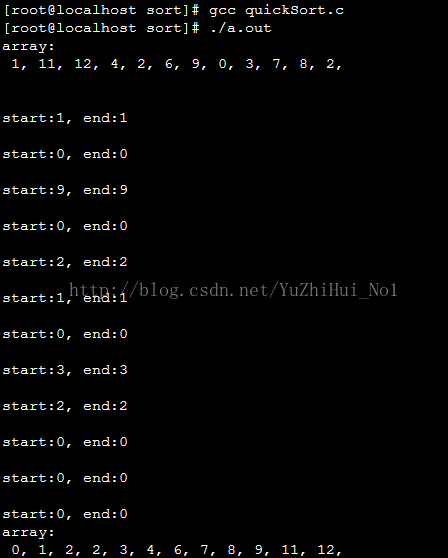
时间复杂度
最优情况下时间复杂度
令:n = n/2 = 2 { 2 T[n/4] + (n/2) } + n ----------------第二次递归
= 2^2 T[ n/ (2^2) ] + 2n
令:n = n/(2^2) = 2^2 { 2 T[n/ (2^3) ] + n/(2^2)} + 2n ----------------第三次递归
= 2^3 T[ n/ (2^3) ] + 3n
......................................................................................
令:n = n/( 2^(m-1) ) = 2^m T[1] + mn ----------------第m次递归(m次后结束)
当最后平分的不能再平分时,也就是说把公式一直往下跌倒,到最后得到T[1]时,说明这个公式已经迭代完了(T[1]是常量了)。
得到:T[n/ (2^m) ] = T[1] ===>> n = 2^m ====>> m = logn;
T[n] = 2^m T[1] + mn ;其中m = logn;
T[n] = 2^(logn) T[1] + nlogn = n T[1] + nlogn = n + nlogn ;其中n为元素个数
又因为当n >= 2时:nlogn >= n (也就是logn > 1),所以取后面的 nlogn;
综上所述:快速排序最优的情况下时间复杂度为:O( nlogn )
最差情况下时间复杂度
最差的情况就是每一次取到的元素就是数组中最小/最大的,这种情况其实就是冒泡排序了(每一次都排好一个元素的顺序)
这种情况时间复杂度就好计算了,就是冒泡排序的时间复杂度:T[n] = n * (n-1) = n^2 + n;
综上所述:快速排序最差的情况下时间复杂度为:O( n^2 )
平均时间复杂度
空间复杂度
转载请注明作者和原文出处,原文地址:http://blog.csdn.net/yuzhihui_no1/article/details/44198701
若有不正确之处,望大家指正,共同学习!谢谢!!!














 2895
2895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









