






在 Apache Spark 和 PySpark 中的 Spark driver 是什么?在多机集群模式下,PySpark 使用 master(driver) – slave(worker)架构工作,这些机器通过网络相互协作使得任务执行完毕。对于这样的 spark 系统,我们需要单独的机器管理集群,比如:Spark driver。
这篇文章讨论 spark 架构、driver 管理内容极其配置。
1. Apache Spark Architecture
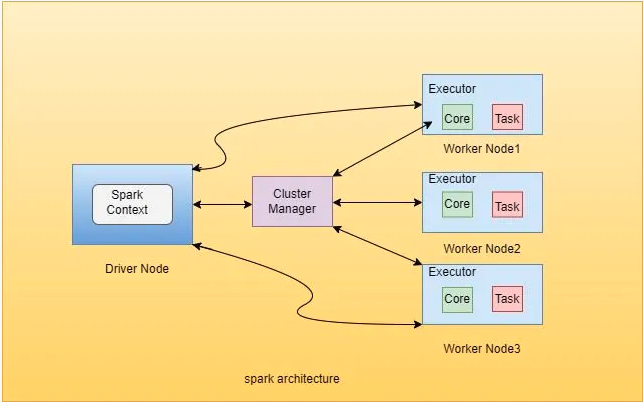
Apache Spark 是一个用于处理大量结构化、非结构化、半结构化的数据的开源框架。它采用一主多从的架构,由一个作为 master 的 driver、clusterManager 和多个工作节点构成。master 所在的物理机称为 master,其余的都是 slave。
1.1 Spark Cluster Manager
spark cluster manager 负责分配 workers 执行数据处理所需的资源。于此类似的集群管理器有:Hadoop Yarn、Apache Mesos 和 Standalone Scheduler(spark 在 standalone 模式下的集群管理器)。
1.2 Spark Driver Program
在应用程序中,spark driver 的任务之一是创建 SparkContext 对象。一旦我们提交 spark job,driver 程序运行 main() 方法并且创建 DAG 表示内部的数据流动。基于DAG 工作流,driver 从 cluster manager 申请资源。资源分配成功后,driver 通过 sparkContext 发送序列化后的结果(原文是:the serialized result (code+data))给 worker 作为一个 task 执行并且捕获执行的结果。
关键点:
- Spark Context:它通过 driver 程序连接到 cluster manager 申请处理数据所需的 executors 是,然后返送序列化后的结果给 workers 作为任务执行。
- RDD: 弹性分布式数据集是一组数据的集合,可以存储在 worker 节点的内存中或者磁盘中。
- Directed Acyclic Graph (DAG):DAG 表示数据的计算序列图。Apache spark 使用直接无环图 (DAG) 中表示的数据流以 RDD 的形式处理数据。
1.3 Spark Executors
spark Exector 或者 worker是分布部署在集群物理机上。每个 executor 拥有称之为核的带宽处理数据(这里说的就是cpu cores)。基于 executor 获得的 core 数量,它们从 driver 中拉取任务从而在数据上处理用户写的应用程序的逻辑(代码在数据集上按照编写顺序执行一遍)同时将这些数据保存在内存或者磁盘上。exector 可以从内部、外部的存储系统读取数据。
2. What Does Spark Driver do?
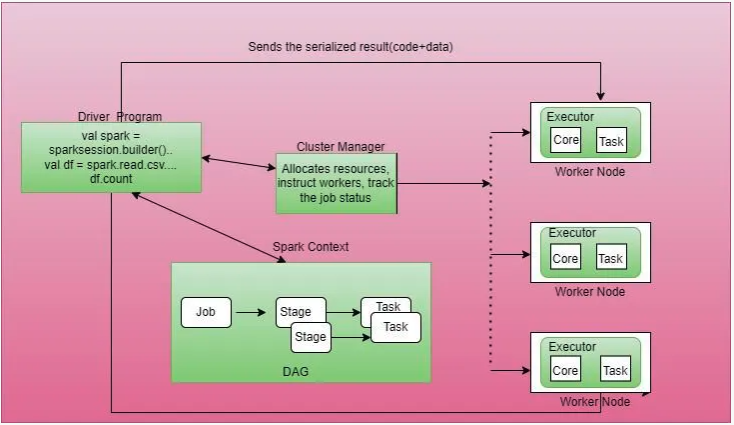
当 spark 任务提交后驱动程序就按照配置启动了。执行应用程序的 main 方法同时创建 SparkContext,在此基础上按照编写的程序代码创建 sparkContext、transform 算子和 action 算子。
直到执行算子被调用时,所有的转换算子将被放入 sparkContext 以 DAG 的形式存在,有向无环图(DAG)创建依赖关系(也叫血统)。当执行算子被调用时持有多个 task 的 job 将会被创建。然后 driver 向 cluster manager 申请资源分配给 executor 去执行这些 task。
资源分配成功后,在 taskScheduler 的帮助下,cluster manager 在 worker 节点依据应用配置发起任务。
task分发给了 exector,但是 driver 拥有着所有 task 的 metadata,并且存储着 task 的状态信息 ,当 task 执行完成后 exectutor 会将结果传回给 driver。
关键点:
- driver 运行应用程序的 main 方法。
- driver 创建 SparkContext 和 SparkSession。
- 将应用程序的代码转换成有向无环图。
- 帮助创建 DAG Execution Plan、 Logical Plan 和 Physical Plan。
- 在 cluster manager 的帮助下 Driver 中的 taskScheduler 调度 task 给 exector。
- Driver 与 exectutor 协调并追踪存储在 exectutor 中的数据。
3. Spark Driver Configuration
这里只写几个关键的 driver 配置
spark.driver.cores: 表示 cpu 的计算能力,默认是 1。spark.driver.maxResultSize: 这个属性定义了 driver 可以存储的序列化后的结果的上限。默认 1G,最小 1M,当设置成 -1 时表示没有上线,但可能会发生 driver OOM。”序列化后的结果“是什么东东?原文中的是 serialized result,我理解的这分为两个部分:(1)是 driver 生成的有向无环图,task ,这些对象都是要占存储空闲的;(2)task 执行完毕后的回传给 driver 的 result。spark.driver.memory: 表示 spark Driver 最大谁用的内存上限,提交的任务超过该上限会抛异常。默认 1G。
4. spark.sql.shuffle.partitions和spark.default.parallelism的区别
spark.default.parallelism 只有在处理RDD时才会起作用,对Spark SQL的无效。
spark.sql.shuffle.partitions 则是对Spark SQL专用的设置。















 1906
1906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









