







一、对象的本质(锁在对象中的体现)
1.1、对象的结构
对象由多部分构成的,对象头、属性字段、补齐字段等。补齐字段是指如果对象总大小不是4字节的整数倍,会填充上一段内存地址是之成为4的整数倍。
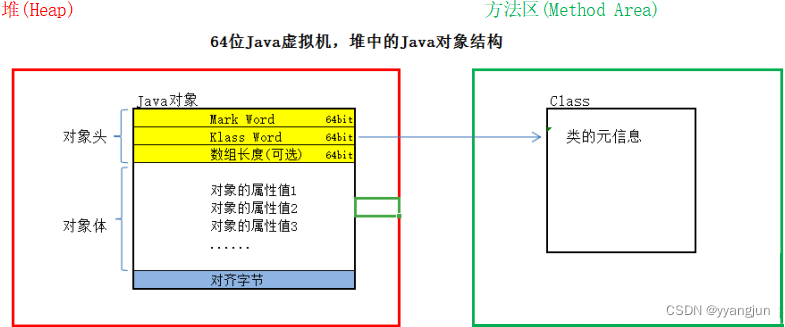
其中,对象头在对象的最前端,包含两部分或者三部分:Mark Words、Klass words,如果对象是一个数组,那么还可能包含第三部分:数组的长度。
1)Klass word里面存的是一个地址,占32位或者64位,是一个指向当前对象所属于的类的地址,可以通过这个地址获取到它的元数据信息。
2)Mark Word主要包含对象的hash值、年龄分代、hashcode、锁标志位等。
ps:如何查看对象的这部分内容?
1、引入JOL依赖,具体如下图:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency>
2、创建实体类
public class JOLObject {}
3、创建测试类
public class JOLExample1 {
static JOLObject jolObject;
public static void main(String[] args) {
jolObject=new JOLObject();
//打印JVM的详细信息
System.out.println(VM.current().details());
System.out.println("==============");
//打印对应的对象头信息
System.out.println(ClassLayout.parseInstance(jolObject).toPrintable());
}
}
运行结果如下:
# Running 64-bit HotSpot VM.
# Using compressed oop with 3-bit shift.
# Using compressed klass with 3-bit shift.
# WARNING | Compressed references base/shifts are guessed by the experiment!
# WARNING | Therefore, computed addresses are just guesses, and ARE NOT RELIABLE.
# WARNING | Make sure to attach Serviceability Agent to get the reliable addresses.
# Objects are 8 bytes aligned.
# Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
==============
com.yang.java.lock.domain.JOLObject object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 48 72 06 00 (01001000 01110010 00000110 00000000) (422472)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
Process finished with exit code 0
不是说Klass是64bits(8个字节)但是这儿只有4个字节,是因为我们开启了指针压缩,我们可以关闭指针压缩看看,是不是8个字节。我们只需要使用以下的JVM运行参数
-XX:-UseCompressedOops
输出结构:
com.yang.java.lock.domain.JOLObject object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) b0 5c 20 ae (10110000 01011100 00100000 10101110) (-1373610832)
12 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
- 关于对象结构,后续会专门写一篇介绍对象结构的文章
二、锁结构为什么要升级
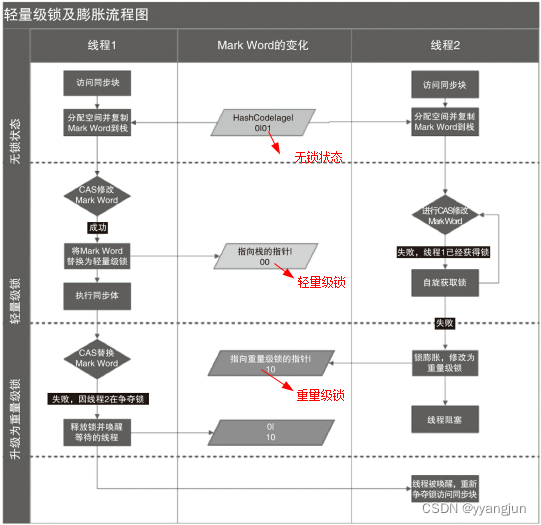
首先,这四种锁结构都是针对synchronized来说的。锁的升级是由于竞争的激烈程度导致的,竞争越大,锁结构越重量化。
先看一段比较基本的synchronized代码
public class SynchronizedDemo2 {
Object object=new Object();
public void method1(){
synchronized (object){
}
method2();
}
private static void method2(){
}
}
通过指令javac SynchronizedDemo2.java编译生成.class文件,使用javap -verbose SynchronizedDemo2.class查看.class文件信息
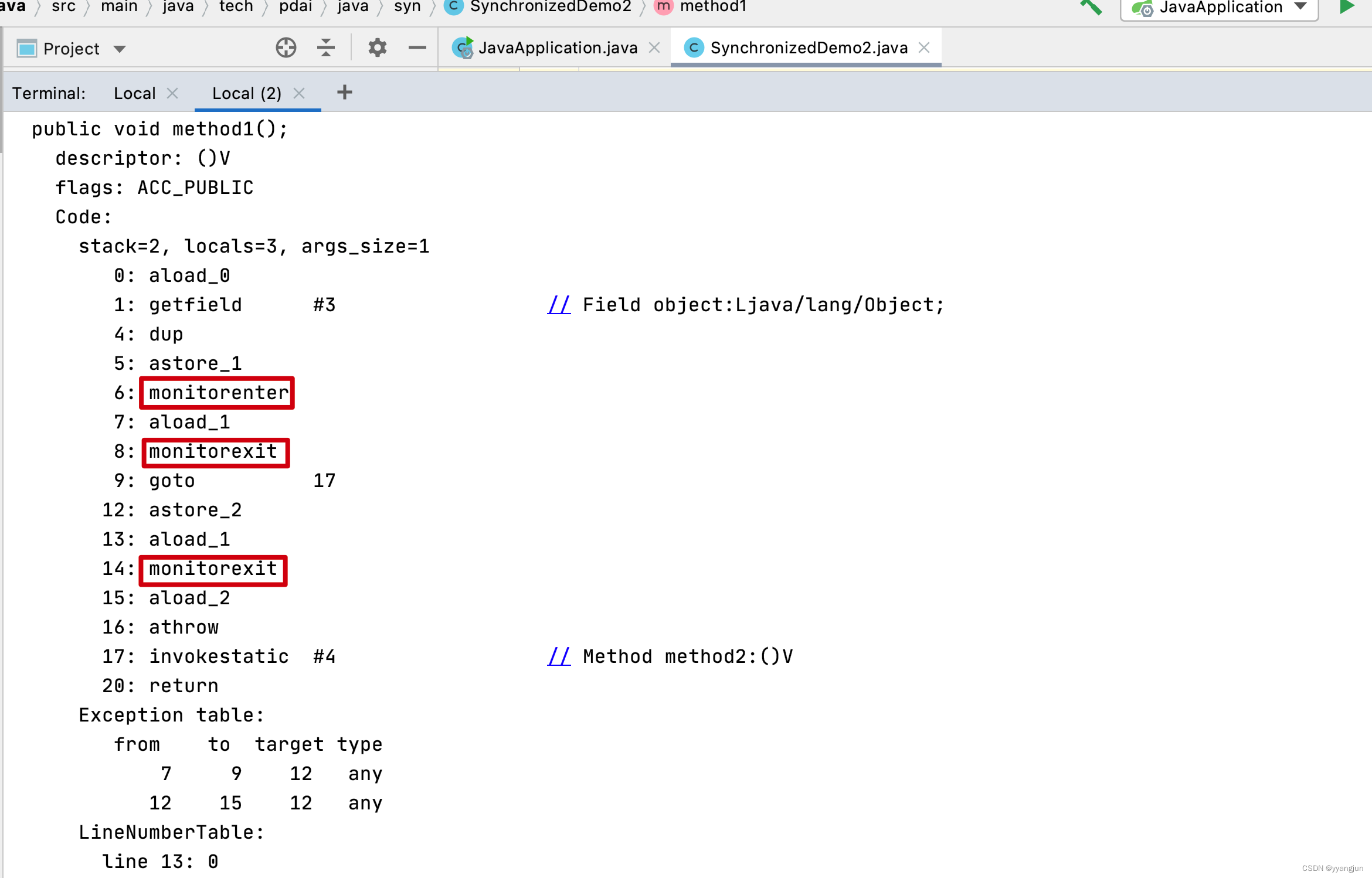
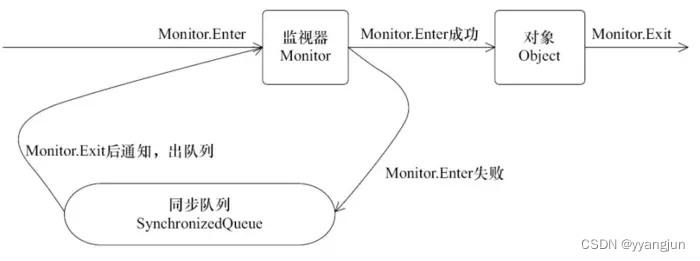
关注红色方框里的monitorenter和monitorexit即可。 Monitorenter和Monitorexit指令,会让对象在执行,使其锁计数器加1或者减1。每一个对象在同一时间只与一个monitor(锁)相关联,而一个monitor在同一时间只能被一个线程获得,一个对象在尝试获得与这个对象相关联的Monitor锁的所有权的时候,monitorenter指令会发生如下3中情况之一: monitor计数器为0,意味着目前还没有被获得,那这个线程就会立刻获得然后把锁计数器+1,一旦+1,别的线程再想获取,就需要等待 如果这个monitor已经拿到了这个锁的所有权,又重入了这把锁,那锁计数器就会累加,变成2,并且随着重入的次数,会一直累加 这把锁已经被别的线程获取了,等待锁释放 monitorexit指令:释放对于monitor的所有权,释放过程很简单,就是讲monitor的计数器减1,如果减完以后,计数器不是0,则代表刚才是重入进来的,当前线程还继续持有这把锁的所有权,如果计数器变成0,则代表当前线程不再拥有该monitor的所有权,即释放锁。 下图表现了对象,对象监视器,同步队列以及执行线程状态之间的关系:
三、锁结构升级的实现
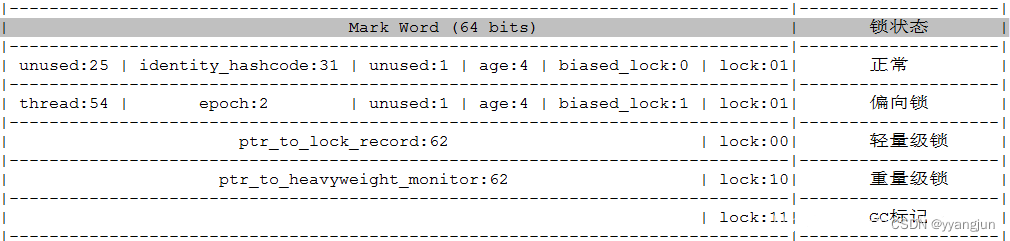
markword相关字段详细解释:
- identity_hashcode:31位的对象标识hashcode,采用延迟加载技术。调用方法System.identityHashCode()计算,并会将结果写到该对象头中。当对象加锁后(偏向、轻量级、重量级),MarkWord的字节没有足够的空间保存hashCode,因此该值会移动到管程Monitor中。(待验证)
- age:4位的对象年龄。在GC中,如果对象在Survivor区复制一次,年龄增加1.当对象达到设定的阈值时,将会晋升到老年代。默认情况下,并行GC的年龄阈值为15,并发GC的年龄阈值为6.由于age只有4位,所以最大值为15,这就是-XX:MaxTenuringThreshold选项最大值为15的原因。
- biased_lock标志位:对象是否启用偏向锁标记,只占1个二进制位。为1时表示对象启用偏向锁,为0时表示对象没有偏向锁。lock和biased_lock共同表示对象处于什么锁状态。
- lock:2位的锁状态标记位,由于希望用尽可能少的二进制位表示尽可能多的信息,所以设置了lock标记。该标记的值不同,整个Mark Word表示的含义不同。biased_lock和lock一起,表达的锁状态含义如下:
| biased | lock | 状态 |
|---|---|---|
| 0 | 01 | 无锁 |
| 1 | 01 | 偏向锁 |
| 00 | 轻量级锁 | |
| 01 | 重量级锁 | |
| 11 | GC标记 |
- thread: 持有偏向锁的线程ID
- epoch:偏向锁的时间戳
- ptr_to_lock_record:轻量级锁状态下,指向栈中锁记录的指针
- ptr_to_heavyweight_monitor:重量级锁状态下,指向对象监视器Monitor的指针
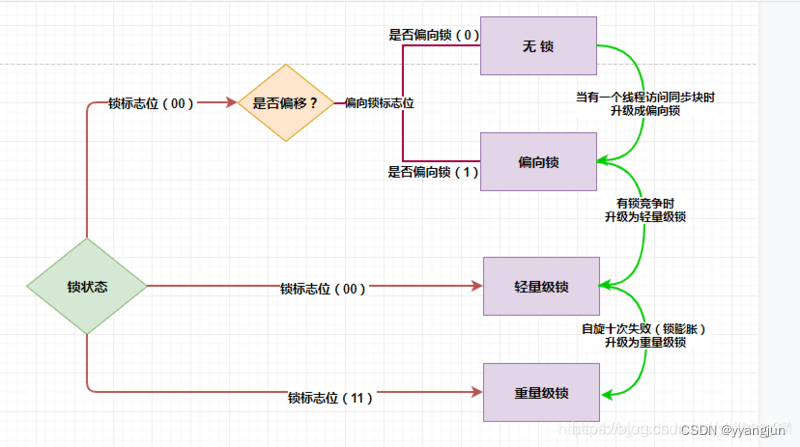
我们通常说的通过synchronized实现的同步锁,真实名称叫做重量级锁。但是重量级锁会造成线程排队(串行执行),且会使CPU在用户态和核心态之间频繁切换,所以代价高、效率低。为了提高效率,不会一开始就使用重量级锁,JVM在内部会根据需要,按如下步骤进行锁的升级:
3.1、无锁->偏向锁
初期锁对象刚创建时,还没有任何线程来竞争,对象的Mark Word是下图的第一种情形,这偏向锁标识位是0,锁状态01,说明该对象处于无锁状态(无线程竞争它)。

当有一个线程来竞争锁时,先用偏向锁,表示锁对象偏爱这个线程,这个线程要执行这个锁关联的任何代码,不需要再做任何检查和切换,这种竞争不激烈的情况下,效率非常高。这时Mark Word会记录自己偏爱的线程的ID,把该线程当做自己的熟人。

3.2、偏向锁->轻量级锁
当有两个线程开始竞争这个锁对象,情况发生变化了,不再是偏向(独占)锁了,锁会升级为轻量级锁,两个线程公平竞争,哪个线程先占有锁对象并执行代码,锁对象的Mark Word就执行哪个线程的栈帧中的锁记录。

3.3、轻量级锁->重量级锁
如果竞争的这个锁对象的线程更多,导致了更多的切换和等待,JVM会把该锁对象的锁升级为重量级锁,这个就叫做同步锁,这个锁对象Mark Word再次发生变化,会指向一个监视器对象,这个监视器对象用集合的形式,来登记和管理排队的线程。

3.4、GC标记

3.5、锁是否可以越级升级
这里产生了一个疑问:锁升级是否会出现直接由偏向锁直接转为重量级锁,跳过中间轻量级锁的过程。现在看来,应该是不会,因为锁升级的内在驱动是多个线程对锁对象的竞争从而导致锁对象中的mark word中相关字段的改写。而线程不可能突然并行执行成千上万个,因为线程可以并行执行的数量取决于CPU核心数(虽然有超线程的存在,但是也不可能超过CPU核心数太多),而对于CPU来说,是以CPU时间片分配给线程执行的,只有拿到了CPU时间片的线程才能获取到CPU的控制权。所以即使在应用层面同时创建多个线程,在线程执行层面(即CPU层面)还是依然是通过时间片的机制执行线程的,一定是存在着线程并发数由少变多的过程,而锁升级也伴随着线程并发数增多,抢占锁更激烈而升级。
四、锁升级的代码实现
4.1 无锁->偏向锁
public class NoLockExample {
static JOLObject jolObject=new JOLObject();
public static void main(String[] args) {
//打印对应的对象头信息
System.out.println(ClassLayout.parseInstance(jolObject).toPrintable());
}
}
输出结果:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 48 72 06 00 (01001000 01110010 00000110 00000000) (422472)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
结果分析:这里显示的是偏向锁,当创建的时候,会有其他的线程使用对象而使对象的锁结构从无锁转为偏向锁。
4.2、偏向锁转为轻量级锁
未完待续
五、不同锁结构应用场景
5.1、无锁结构
无锁结构的应用在业务中比较常见,如果特定的业务场景没有多线程共享访问全局变量的话,就不需要使用锁结构,因为不涉及线程安全问题。
5.2、偏向锁结构
根据偏向锁自身的特点,如果只有单个线程对共享变量进行访问的场景,可以将此全局变量设置为偏向锁对象,即该锁对象对特定的线程具有优先级。常见业务类型有在主线程中的全局变量没有其他变量访问的场景。
5.3、轻量级锁结构
根据轻量级锁特点,常见于多个线程竞争锁资源的场景,轻量级锁不是公平锁,但是可以通过轻量级锁实现公平锁。常见业务场景:秒杀活动等。
5.4、重量级锁结构
重量级锁由于阻塞其他线程的原因,所以在对全局变量的访问上具有最高的安全性,常见于金融系统等安全系数要求较高的场景。
















 1191
1191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









