







人体姿态追踪
数据集
- posetrack
这个数据集包括550个视频,66374帧
292个训练视频,50个验证视频,和208个测试视频
大多数数据集长度在41到151帧之间,大概是5s左右不同的视频长度具有不同的帧率
每个视频序列,注释中间的30帧
另外在验证和测试集中,每隔4帧进行稠密标注(with a step of four frames?),目的在于测试跟踪身体关节的稳定性以及长期跟踪身体关节的能力。
总共23,000标注帧,153,615个标注姿态
大部分的视频包含大量的人
单针的姿态估计,和MPII,MSCOCO关键点相似,但是使用的是pose track数据集
视频中的姿态估计,挑战是在单针上进行的,但是数据包含了改标注帧的前后帧,可以挖掘视频信息用于鲁棒的单帧姿态估计
姿态追踪,这个任务就是要求提供时间域上保持一致,姿态估计的结果,评估包括独立的姿态估计精度和ID时间域上一致性的评估
实验的评价指标是:用于评价一个身体部位预测正确于否,当预测的位置和gt距离小于阈值,就认为是正确预测,阈值gt中头部边界框对角线长度的60% 的 50%,即30%的头部边界框对角线长度。
两种评估指标:
多人姿态估计map
铰接式多人位姿跟踪:使用MOT的指标MOTA和MOTP
首先,对于每一帧的每一个关节种类,计算预测值与真值之间的距离
然后,使用匹配算法进行匹配
最后,计算MOTA和MOTP,Precision Recall
分两个阶段
第一阶段:结合人检测和单针姿态估计方法,在单针中进行人姿态估计,具体的单针估计打方法很多,最好的三种姿态跟踪方法基于不同的姿态估计方法(pro-Tracker(Mask-RCNN), BUTD,PoseTrack-baseline(PAF) 和 ArtTarck-baseline(Faster-RCNN+DeepCut))
第二个阶段就是单针姿态估计在时间域上联系起来,对于大多数的方法,分配是在身体姿态的层次上执行的,而不是单个部分。在实践中就是给定一个人的边界框,然后在边界框中进行姿态估计,最后热力图的最大值被认为是belongs together
训练数据:
大部分的作品都认为需要将我们的训练集与coco,mpi-pose等静态图像数据结合起来,得到一个具有更大外观异性的联合训练集,最常见的就是对外部数据进行与培训,然后对欲培训进行微调。将coco和MPII-pose结合,这俩数据集包含一个轻量级的更多的个人,但不提供运动信息,使用artTrackbaseline来量化额外数据培训带来的性能改进,扩展的训练数据集大大提高性能55.5->68.7说明比单独使用MPII-pose更好,表名数据集是互补的。
注意力机制与人体的姿态估计
1,attention是什么
当人们的目光关注一样东西的时候,该目标内部以及该场景每一处空间位置的注意力分布是不一样的 ,attention 分为空间和时间上的注意力。不同的时间和空间片上信息明显有差别。网络去学习空间和时间上的差距,模型就是负责给输入的上下文进行打分,告诉模型哪些输入是有效的,减小了处理高维输入数据的负担,结构化的选取输入的子集,降低数据维度,另外任务处理系统就会专注于找到与输入数据中显著的与当前输出相关的有用的信息,https://blog.csdn.net/joshuaxx316/article/details/70665388
- Multi-Context Attention for Human Pose Estimation
人觉得本文最大亮点就是文中通过CRF(条件随机场)来实现holistic attention model - 论文介绍
提出了将多语镜注意力机制的卷积神经网络结合到用于人体姿态估计都得端到端的框架中,主要方法有:
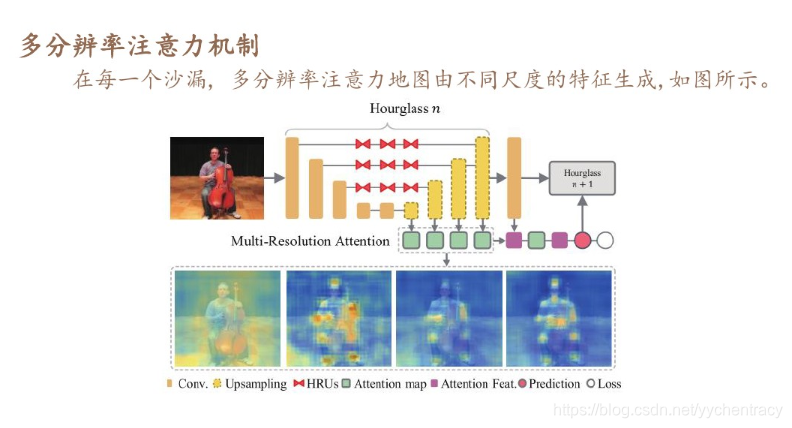
1,采用堆叠的沙漏网络,以多种分辨率和各种语义的特征产生注意力图
2,利用条件随机场CRF将注意力途中相邻区域之间的相关性进行建模
3,进一步结合整体的注意力模型,构建人体的全局一致性,结合身体部位的注意力模型,对不同的身体部位的详细描述
4,设计了新的沙漏残差单元来增加网络的接收范围
卷积神经网络应用于计算机视觉,方向的成效显著,但是具有局限性,肢体关联性,身体自遮挡和被遮挡,服装影响,复杂背景影响。注意力模型的构建是通过注意力模型生成整体注意力图和部分注意力图注意力机制的特点
提供了一种明确的方法来模拟人体各个部位之前的空间关系
部分注意映射可以解决重复计数问题来进一步细化部分的位置。注意力图由注意力模型生成,依赖于图像的特征,并提供一种有原则的方法来聚焦于可变形状的目标区域。
4,有助于恢复丢失的身体部位,并将模糊的背景区分开来。允许加上上下文的多样性,上下文区域可更好的适应每一张图像
5,设计了一种基于条件随机场的新型注意模型,该模型可以更好的模拟相邻区域之间的空间相关性,利用条件随机场对注意力途中相邻区域之间的相关性进行建模。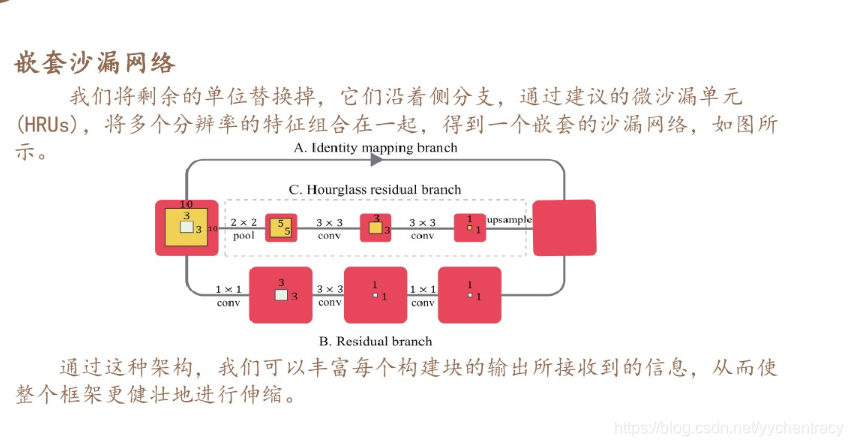
https://wenku.baidu.com/view/86194e68580102020740be1e650e52ea5418ce75.html(可以再去看,有需要的话,我自己没全看完)
若监督关键点估计
参考下面的连接人体https://blog.csdn.net/qiu931110/article/details/89430747
2. CornerNet
通过hourglass network进行特征提取,紧接着将网络得到的特征输入到两个模块,top-left corner pooling和bottom-right corner pooling 提取关键点的特征,对于每个corner pooling木块都会进行目标框的左上角关键点和右下角关键点的类别分类,(heatmaps)并找到每个目标的一对关键点,(embeddings)以及减少基于坐标回算目标位置时偏置(offsets)
- 两个Corner pooling
为了使得关键点的特征能够表征左上角和右下角关键点所包含的目标区域的特征,作者为求左上角关键点特征,需要求当前关键点同一行中的左边区域的最大值,和同一列中的下面区域的最大值,并将两个最大值相加才是当前位置的左上角关键点特征 - Embeddings模块
在Headmaps模块中对关键点类别的预测是没办法知道哪两个关键点能够构成一个目标,因此如何找到一个目标的两个关键点就是模块embedding做的工作。
Offsets模块
该模块主要用于弥补由于网络降采样得到的特征图,在反算关键点原始位置时的精度丢失。如下公式所示,由于向下取整,所以会导致精度丢失,而作者利用L1损失来减少这种精度损失。
2.CenterNet【CVPR092109】
CenterNet网络主要是基于CornerNet网络存在的问题,而提出的基于关键点目标检测的网络。其实现了目前为止在one-stage系类算法中最高的MAP。CenterNet的作者发现,CornerNet是通过检测物体的左上角点和右下角点来确定目标,但在此过程中CornetNet使用corner pooling仅仅能够提取到目标边缘的特征,而导致CornetNet会产生很多的误检。基于此,CenterNet利用关键点三元组即中心点、左上角关键点和右下角关键点三个关键点而不是两个点来确定一个目标,使得网络能够获取到目标内部的特征。而CornerNet在论文中也说道了,约束其网络性能最重要的部分是关键点的提取,因此CenterNet提出了Center Pooling和cascade corner Pooling用来更好的提取本文提出的三个关键点。
Center Pooling
作者基于Corner Pooling的系列思想,提出了Center Pooling的思想,使得网络提取到的中心点特征能够更好的表征目标物体。
cascade corner Pooling
作者基于Corner Pooling的系列思想,提出了cascade corner Pooling的思想,使得网络提取到的中心点特征能够更好的表征目标物体。
- CornetNet-Lite
普林斯顿大学在4月19号提出了两种更高效的基于关键点的目标检测算法,分别为:CornetNet-Saccade和CornetNet-Squeeze,若将两种策略结合则称为CornerNet-Lite。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









