






Flink版本1.17
Hive版本3.1.3
1、Paimon集成Hive
将paimon-hive-connector.jar复制到auxlib中,下载链接Index of /groups/snapshots/org/apache/![]() https://repository.apache.org/snapshots/org/apache/paimon/
https://repository.apache.org/snapshots/org/apache/paimon/
通过flink进入查看paimon
/opt/softwares/flink-1.17.0/bin/sql-client.sh -s yarn-session -i /opt/softwares/flink-1.17.0/conf/sql-client-init.sqlsql-client-init.sql
CREATE CATALOG fs_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs://node154:8020/paimon/fs'
);
CREATE CATALOG hive_catalog WITH (
'type' = 'paimon',
'metastore' = 'hive',
'uri' = 'thrift://node154:9083',
'hive-conf-dir' = '/opt/softwares/hive/conf',
'warehouse' = 'hdfs://node154:8020/paimon/hive'
);
USE CATALOG hive_catalog;
SET 'sql-client.execution.result-mode' = 'tableau';
注意,加载配置文件进入flink之后,虽然说使用的是hive_catalog,但是使用的database是default的,需要使用test,否则找不到表欧。
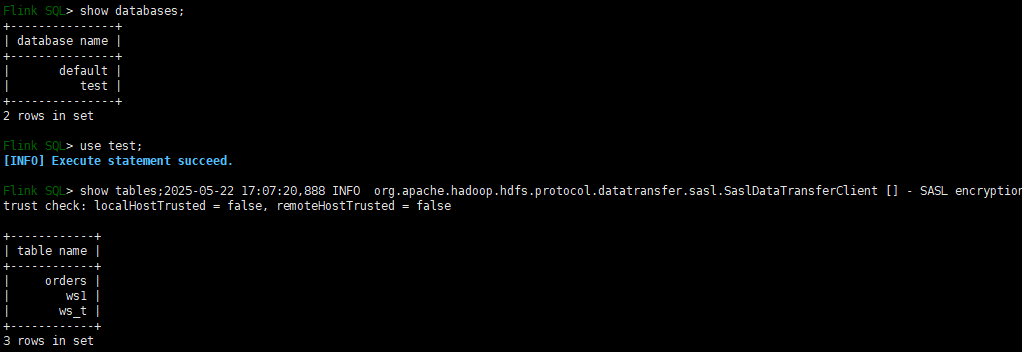
表ws_t;和名为test的database都是之前是在flink中操作paimon在hive_catalog 创建出来的,步骤看
进入hive
hive中
use test;
SELECT * FROM ws_t;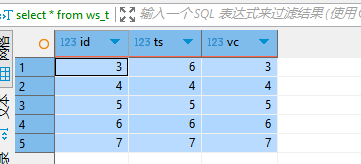
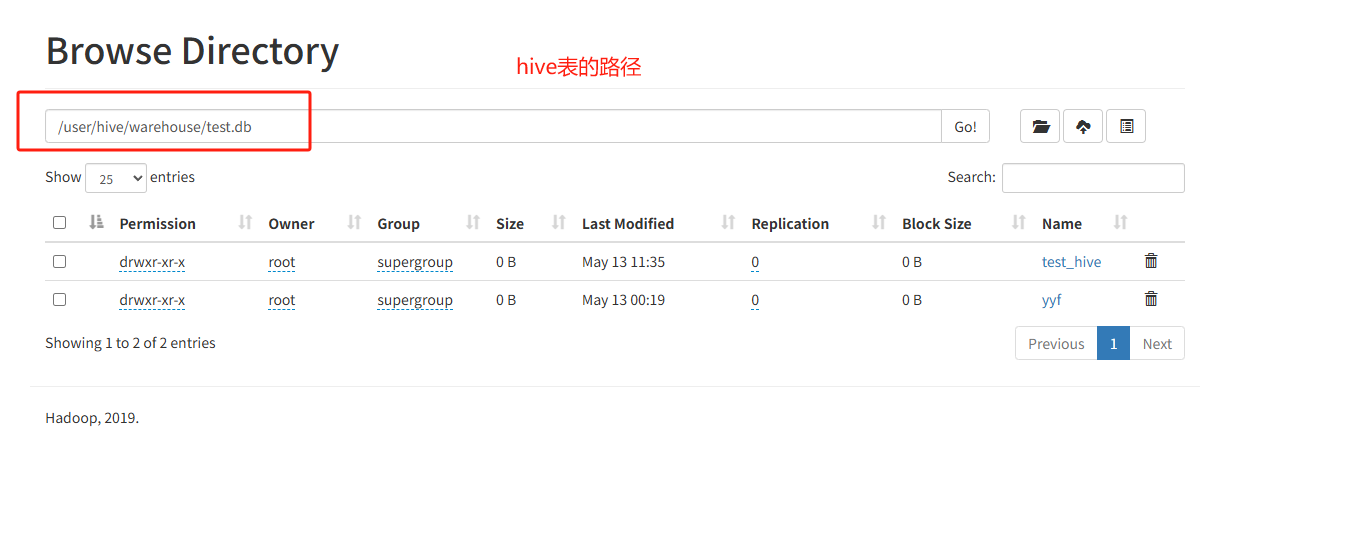
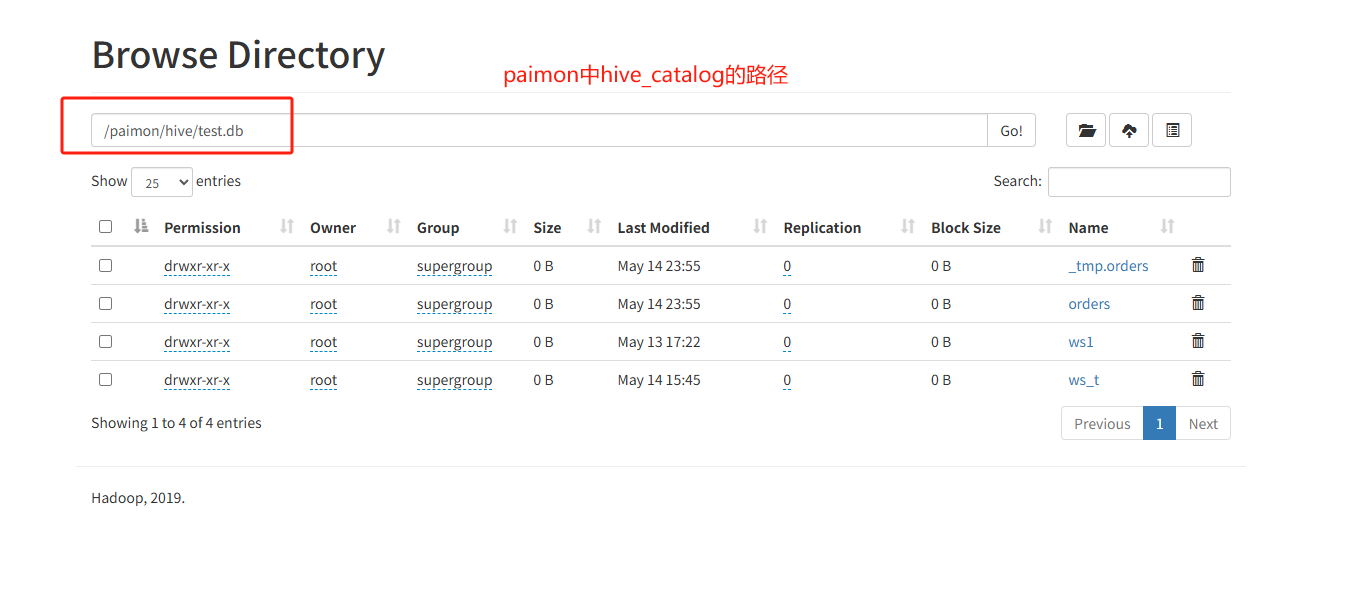
补充知识点,hive中使用【test】database来创建hive表和paimon中使用使用hive_catalog中【test】的database创建出的paimon表存储位置不同,建表语句也能看出来。但是都能在hive中【test】的database查到。
hive查看test库中的表为
orders paimon表
ws1 paimon表
ws_t paimon表
test_hive hive表
yyf hive表文件存储为如图:
---------------paimon表---------------------
CREATE TABLE `ws_t`(
`id` int COMMENT 'from deserializer',
`ts` bigint COMMENT 'from deserializer',
`vc` int COMMENT 'from deserializer')
ROW FORMAT SERDE
'org.apache.paimon.hive.PaimonSerDe'
STORED BY
'org.apache.paimon.hive.PaimonStorageHandler'
LOCATION
'hdfs://node154:8020/paimon/hive/test.db/ws_t'
TBLPROPERTIES (
'transient_lastDdlTime'='1747128118')
-----------------hive表------------------
CREATE TABLE `yyf`(
`a` int)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://node154:8020/user/hive/warehouse/test.db/yyf'
TBLPROPERTIES (
'bucketing_version'='2',
'transient_lastDdlTime'='1747066788')在hive中创建paimon表
--使用hive_catalog的存储路径
SET hive.metastore.warehouse.dir=hdfs://node154:8020/paimon/hive;
--数据处理按照paimon来
CREATE TABLE test_h(
a INT COMMENT 'The a field',
b STRING COMMENT 'The b field'
)
STORED BY 'org.apache.paimon.hive.PaimonStorageHandler'
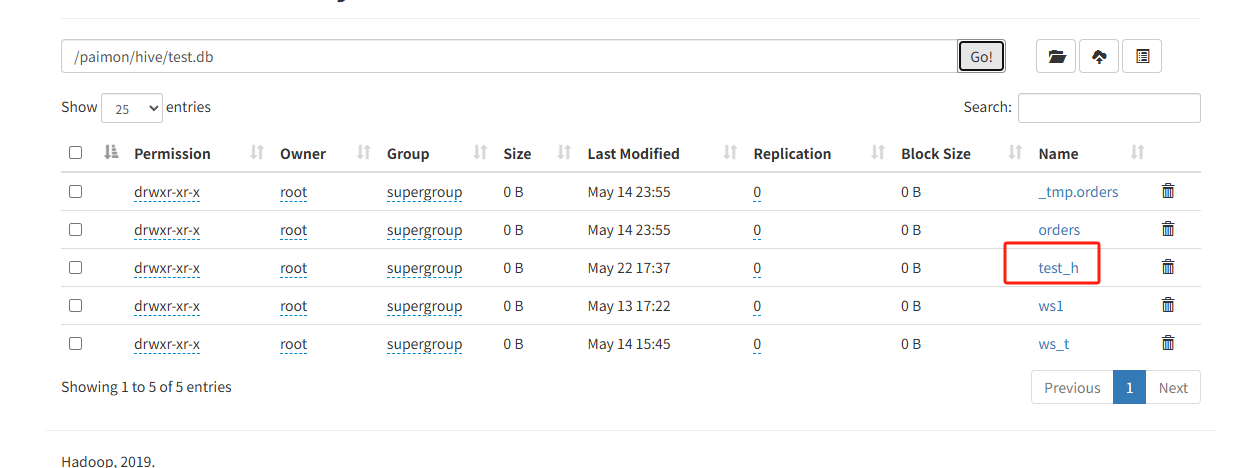
通过创建hive外部表来使用现有的paimon表
字段随着paimon源表的修改而自动变动,paimon表的特性
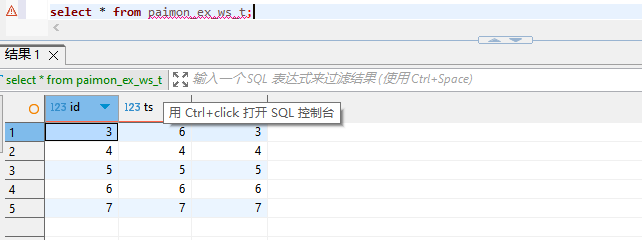
CREATE EXTERNAL TABLE test.paimon_ex_ws_t
STORED BY 'org.apache.paimon.hive.PaimonStorageHandler'
LOCATION 'hdfs://node154:8020/paimon/hive/test.db/ws_t';
--或将路径写在表属性中:
CREATE EXTERNAL TABLE paimon_ex_ws_t
STORED BY 'org.apache.paimon.hive.PaimonStorageHandler'
TBLPROPERTIES (
'paimon_location' ='hdfs://node154:8020/paimon/hive/test.db/ws_t'
);


















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









