






一部分网站对于数据的管控相对不严,可以直接从文本文案中得到相应的数据(即没有反爬措施),但是随着技术的发展,部分数据将被隐藏,我们需要通过解析的手段来获取相应的数据内容。本期以某网站的期货板块为例,进行爬虫教学。
1.网站解析
进入网站,找到需要爬取的数据源,本次进行的是期货中的橡胶模块。
可以发现“Ctrl+U”查看源码后,所需要的数据并不能出现在其中,所以采取另一种方式进行爬取。
按“F12”进入开发者模式,随后按“Ctrl+R”进行页面刷新,成功获取数据的采集。
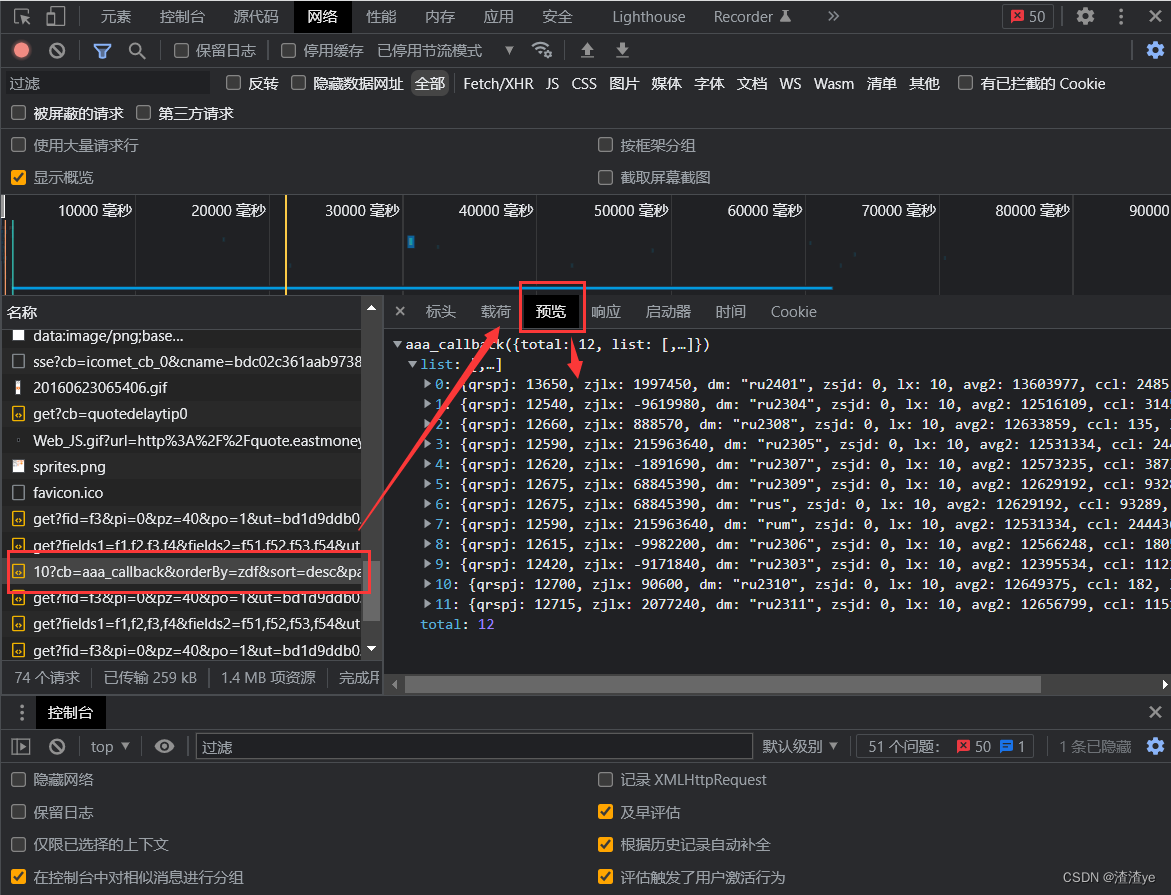
2.构建Requests
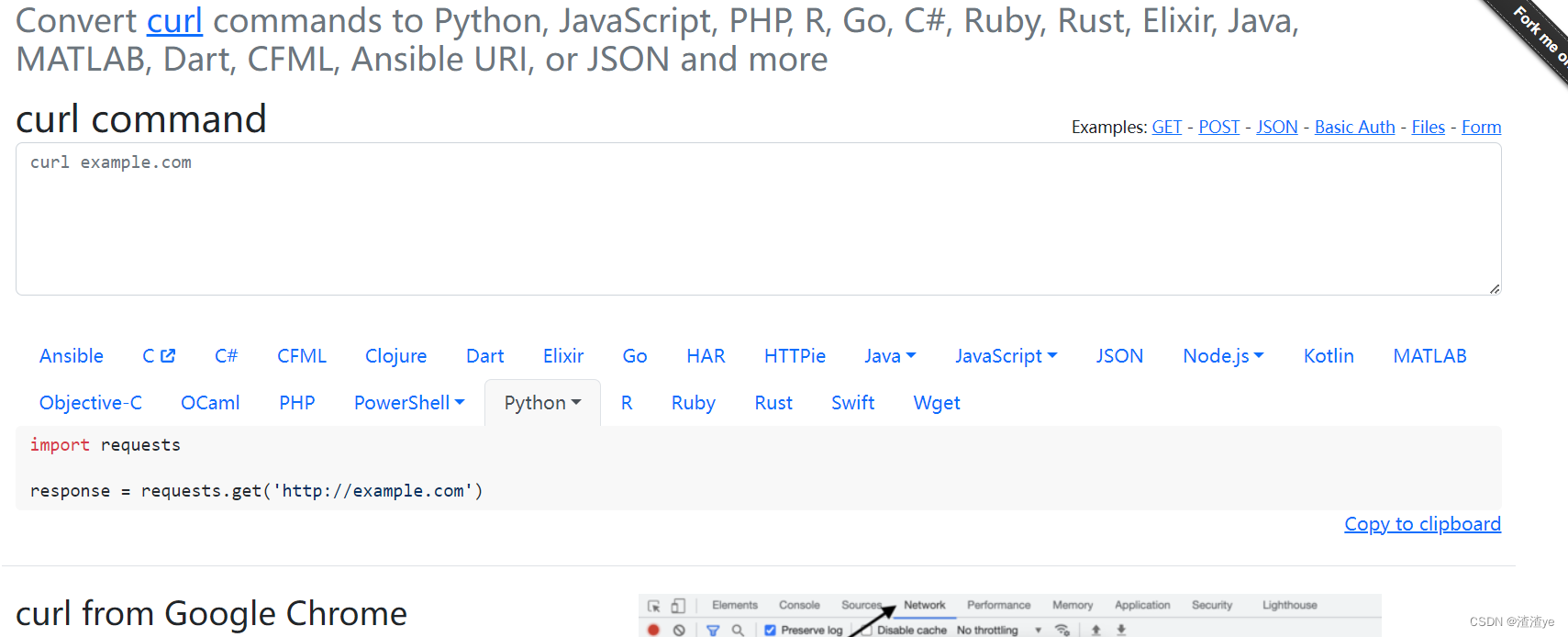
进入下列网站,进行具体Requests的解析
https://curlconverter.com/python/
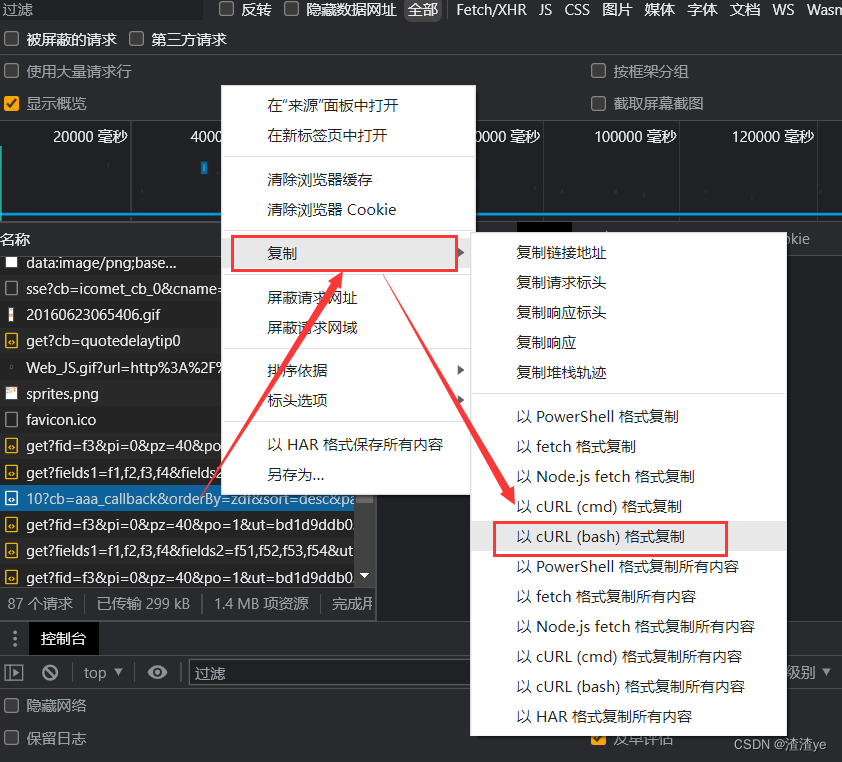
3.具体获取数据并存入EXCEL
具体分析内部内容,在表单后方完成数据获取
dm=re.findall('"dm":(.*?),',response.text)
ccl=re.findall('"ccl":(.*?),',response.text)
o=re.findall('"o":(.*?),',response.text)
p=re.findall('"p":(.*?),', response.text)
vol=re.findall('"vol":(.*?),',response.text)
print(vol)
print(p)
print(o)
print(dm)
print(ccl)
teq=["\"ru2304\"","\"ru2305\"","\"ru2306\""]
name=["","",""]
kpj=["","",""]
spj=["","",""]
cjl=["","",""]
cc=["","",""]
for i in range(12):
if(dm[i]==teq[0]):
name[0]=dm[i]
kpj[0]=o[i]
spj[0]=p[i]
cjl[0]=vol[i]
cc[0]=ccl[i]
if(dm[i]==teq[1]):
name[1]=dm[i]
kpj[1]=o[i]
spj[1]=p[i]
cjl[1]=vol[i]
cc[1]=ccl[i]
if(dm[i]==teq[2]):
name[2]=dm[i]
kpj[2]=o[i]
spj[2]=p[i]
cjl[2]=vol[i]
cc[2]=ccl[i]
wb=openpyxl.load_workbook('a.xlsx')
table1=wb.worksheets[5]
nrows=table1.max_row
biaoji=nrows
print("row:",nrows)
table1.cell(nrows+1,14,"RU2304")
table1.cell(nrows+2,14,"RU2305")
table1.cell(nrows+3,14,"RU2306")
cjl=[int(x) for x in cjl]
kpj=[int(float(x)) for x in kpj]
spj=[int(float(x)) for x in spj]
cc=[int(x) for x in cc]
for i in range(3):
table1.cell(nrows+1+i,16,kpj[i])
table1.cell(nrows+1+i,17,spj[i])
table1.cell(nrows+1+i,18,cjl[i])
table1.cell(nrows+1+i,20,cc[i])
table1.cell(nrows+1+i,19,int(cjl[i])-int(table1.cell(nrows+1+i-3,18).value))
table1.cell(nrows+1,15,time.strftime("%Y/%m/%d",time.localtime()))
table1.cell(nrows+1,21,cc[0]+cc[1]+cc[2])
table1.cell(nrows+1,22,cc[0]+cc[1]+cc[2]-int(table1.cell(nrows+1-3,21).value))
table1.cell(nrows+1,23,cjl[0]+cjl[1]+cjl[2])
table1.cell(nrows+1,24,cjl[0]+cjl[1]+cjl[2]-int(table1.cell(nrows+1-3,23).value))
wb.save(filename='a.xlsx')


















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











