




 本文深入解析现代推荐系统的架构与算法,涵盖在线、近线及离线处理流程,详细阐述基于内容、协同过滤、模型等推荐方法,以及矩阵分解、神经网络等高级技术,助力构建精准个性化推荐。
本文深入解析现代推荐系统的架构与算法,涵盖在线、近线及离线处理流程,详细阐述基于内容、协同过滤、模型等推荐方法,以及矩阵分解、神经网络等高级技术,助力构建精准个性化推荐。
现代推荐系统
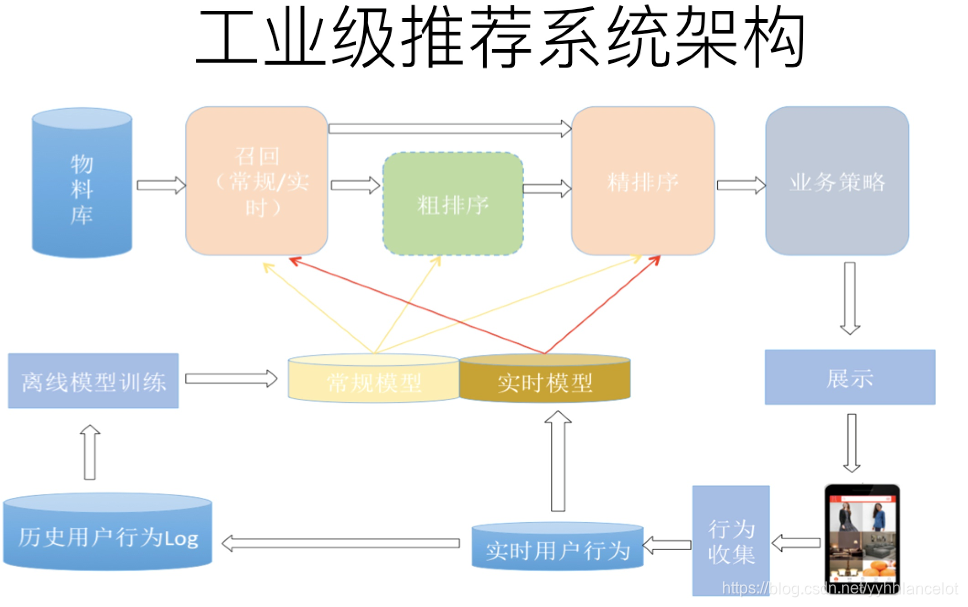
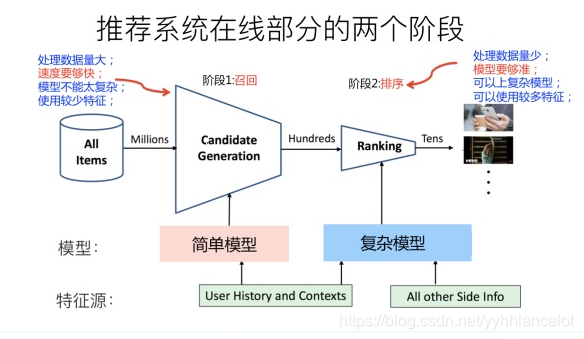
对于在线部分来说,一般要经历几个阶段。首先通过召回环节,将给用户推荐的物品降到千以下规模(因为在具备一定规模的公司里,是百万到千万级别,甚至上亿。所以对于每一个用户,如果对于千万级别物品都使用先进的模型挨个进行排序打分,明显速度上是算不过来的,资源投入考虑这么做也不划算);如果召回阶段返回的物品还是太多,可以加入粗排阶段,这个阶段是可选的,粗排可以通过一些简单排序模型进一步减少往后续环节传递的物品;再往后是精排阶段,这里可以使用复杂的模型来对少量物品精准排序(打分),排序阶段核心目标是要精准,因为它处理的物品数据量小,所以可以采用尽可能多的特征,使用比较复杂的模型,一切以精准为目标。对某个用户来说,即使精排推荐结果出来了,一般并不会直接展示给用户,可能还要上一些业务策略,比如去已读,推荐多样化,加入广告等各种业务策略。之后形成最终推荐结果,将结果展示给用户。
对于近线部分来说,主要目的是实时收集用户行为反馈,并选择训练实例,实时抽取拼接特征,并近乎实时地更新在线推荐模型。这样做的好处是用户的最新兴趣能够近乎实时地体现到推荐结果里。
对于离线部分而言,通过对线上用户点击日志的存储和清理,整理离线训练数据,并周期性地更新推荐模型。对于超大规模数据和机器学习模型来说,往往需要高效地分布式机器学习平台来对离线训练进行支持。
方法概述
(1)基于内容的推荐:根据物品内容(文本信息、属性信息、分类信息等),基于用户以往的喜欢记录,对用户的兴趣爱好进行建模(即用户画像,user profile),以及表达物品的特征(即物品画像,item profile)。然后在物品集合中计算物品画像与用户画像的相似度,选择最相近的N个物品(Top-N)推荐给用户。
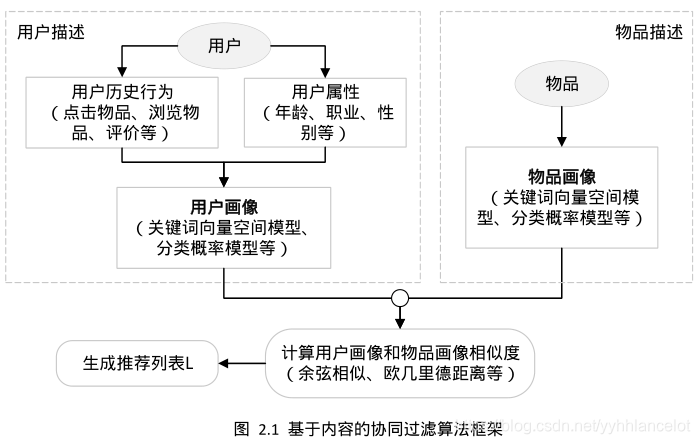
基于内容的方法通常会抽取推荐物品的信息进行描述,常用的方法是加权关键词向量,用户画像和物品特征可以表示为![]() 。抽取的关键词作为推荐对象的特征,权重可以用TF-IDF、熵、信息增益和互信息等进行计算。例如在新闻等文本相关推荐领域,就可以先进行分词,然后利用TF-IDF计算权重,抽取关键词形成特征,建立加权关键字向量。对于用户画像,则可以使用户所有交互过的物品的加权关键字向量进行加权平均来表示。
。抽取的关键词作为推荐对象的特征,权重可以用TF-IDF、熵、信息增益和互信息等进行计算。例如在新闻等文本相关推荐领域,就可以先进行分词,然后利用TF-IDF计算权重,抽取关键词形成特征,建立加权关键字向量。对于用户画像,则可以使用户所有交互过的物品的加权关键字向量进行加权平均来表示。
优点:
- 不需要用户的评分数据
- 没有数据稀疏问题
- 在文本相关的推荐领域有成熟的信息检索技术和分类技术支持
- 不存在物品冷启动问题。“冷启动”指的是,某些模型需要基于历史数据进行推荐,而没有历史数据,就可以理解为“冷启动”。
缺点:
- 推荐结果稳定单一,难以出现令用户惊讶的推荐结果
- 在多媒体领域如音乐视频图片等,难以根据物品的内容信息进行特征抽取
- 需要基于用户历史数据来做推荐,对于新用户会有“冷启动”的问题
(2)基于人口统计信息的推荐:简单根据用户基本信息来发现用户的相关程度,然后推荐,比较简单也比较少用。

比如系统对每个用户有个资料建模,然后根据用户的资料计算互相之间的相似度,比如图中认为A和C相似,推荐系统中称他们为“邻居”。基于这种相似用户,将用户A喜欢的物品A推荐给用户C。
优点:
- 不依赖物品数据,在不同领域的物品都可以使用。
- 由于不依赖历史数据,所以对新用户没有“冷启动”的问题。“冷启动”指的是,某些模型需要基于历史数据进行推荐,而没有历史数据,就可以理解为“冷启动”。
缺点:
- 在对个人画像需要更为精准评价的领域,如图书、电影等,无法得到较好推荐效果。
(3)基于规则的推荐:比如基于最多点击、最多用户浏览等,属于大众型的推荐算法,类似的比如“热门推荐排行榜”。目前不是主流。
(4)社会化推荐:基于社交网络,利用用户的社会化关系进行推荐,例如基于信任传播的推荐。
(5)上下文推荐:这类算法会充分利用上下文信息(例如位置、时间、天气、情感等)提高推荐的精度和用户的满意度,常用于移动推荐、音乐推荐等。
(6)基于集成学习和混合推荐:模型融合,通过多个推荐算法的结合,得到一个更好的推荐算法。但是随之算法复杂度也会增加。实际推荐应用中没有单一的协同过滤或者逻辑回归应用广泛。几种比较流行的方法:
- 加权的混合:通过线性方法将几种不同的推荐组合起
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1355
1355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









