







YOLOv5如何训练自己的数据集
学会如何简单使用YOLOv5和如何制作yolo数据集后,我们便要开始学习如何使用YOLOv5来训练自己的数据集了,那么接下来便开始我们的愉快学习吧!
一.将制作好的数据集放入
制作好数据集后我们需要把数据集放到代码根目录下,直接复制丢进去就行。当然在此之前你最好再检查一下数据集有没有出什么问题,比如图片与标签数量对应不上等问题,所以最好检查一下,数量多的话最好编写程序来检查,没问题之后我们便可以进行接下来的操作了。
二.参数调整
将数据集放入代码根目录后,便要对代码的参数进行调整。我们按下面步骤来依次进行参数调整。
(1)在data文件夹下复制一份voc.yaml文件,并重新命名为xxx.yaml文件,把这里面的文件内容改成如下形式:(只要写没有#的即可)
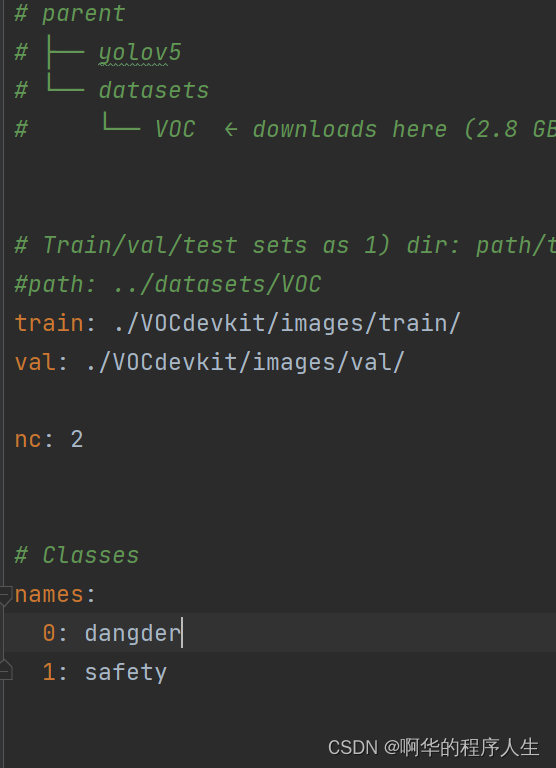
其中train代表训练集图片路径,val表示验证集图片路径,nc表示类别数,names代表类别名称(英文),注意类别名称一定要按你标注的顺序写,不然会乱掉这个顺序在哪里看呢?在你标注的labels文件夹里有一个classes.txt文件,在你标注时,标注软件已经给你添加好了,你也可以在标注前自己写一个这个文档放里面。
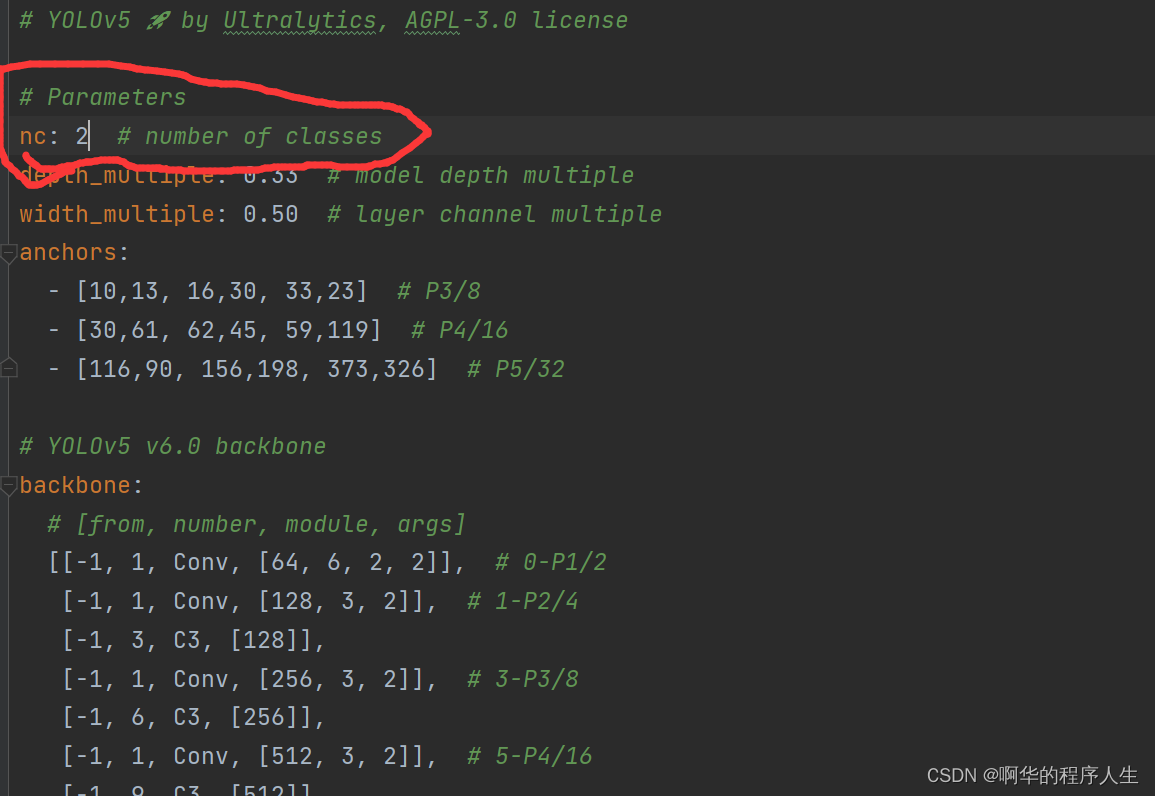
(2)由于该项目使用的是yolov5s.pt这个预训练权重,所以要使用models目录下的yolov5s.yaml文件中的相应参数(因为不同的预训练权重对应着不同的网络层数,所以用错预训练权重会报错)。同上修改data目录下的yaml文件一样,我们最好将yolov5s.yaml文件复制一份,然后将其重命名,我将其重命名为swimming.yaml。我们只需要修改其中的nc为你 的类别数量即可,其它暂时不要动。如下图:
(3)上面俩个文件调整好之后,便开始调整train.py中的参数了,我们先对train中的参数做一个简单介绍:
opt模型主要参数解析:
–weights:初始化的权重文件的路径地址
–cfg:模型yaml文件的路径地址
–data:数据yaml文件的路径地址
–hyp:超参数文件路径地址
–epochs:训练轮次
–batch-size:喂入批次文件的多少
–img-size:输入图片尺寸
–rect:是否采用矩形训练,默认False
–resume:接着打断训练上次的结果接着训练
–nosave:不保存模型,默认False
–notest:不进行test,默认False
–noautoanchor:不自动调整anchor,默认False
–evolve:是否进行超参数进化,默认False
–bucket:谷歌云盘bucket,一般不会用到
–cache-images:是否提前缓存图片到内存,以加快训练速度,默认False
–image-weights:使用加权图像选择进行训练
–device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)
–multi-scale:是否进行多尺度训练,默认False
–single-cls:数据集是否只有一个类别,默认False
–adam:是否使用adam优化器
–sync-bn:是否使用跨卡同步BN,在DDP模式使用
–local_rank:DDP参数,请勿修改
–workers:最大工作核心数
–project:训练模型的保存位置
–name:模型保存的目录名称
–exist-ok:模型目录是否存在,不存在就创建
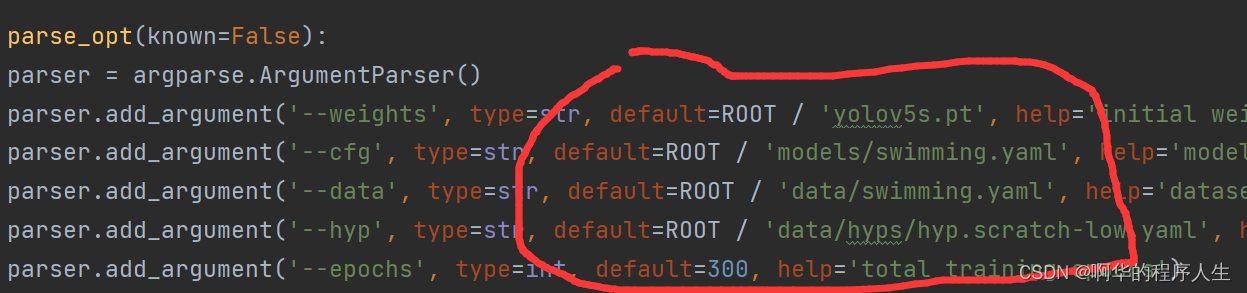
接下来我们一个一个参数来修改,首先是weights参数,这个参数代表初始权重文件,如果有就写,没有就不写,默认用yolov5s.pt文件,表示从该权重文件基础上进行训练,因为我们用的就是yolov5s.pt来进行训练的,所以可以不动。
下一个参数是cfg:模型yaml文件的路径地址,将在这个改成之前 让你复制并重命名的models目录下的yolov5s.yaml文件即可,我这里是swimming.yaml。
下一个参数是data:数据yaml文件的路径地址,将在这个改成之前 让你复制并重命名的data目录下的yolov5s.yaml文件即可,我这里是swimming.yaml。
上面参数修改后如下图所示:
接下来还需要调整epochs参数,代表训练轮次,默认100,我这里填的300,这个看情况填吧,不满意后面可以在训练基础上接着训练。这个后面再讲。
下面还有几个参数你要看情况修改,一般情况下如果能跑起来就不需要动,参数截图如下:


batch-size代表喂入批次文件的多少,默认16,如果运行程序出现分页面文件太小,无法完成操作的问题,就把它调小,调的时候按2的基数来调,当然越大越好就是了。
workers代表最大工作核心数,默认为8,如果运行程序显存溢出的问题,就把它调小,调的时候按2的基数来调,当然越大越好就是了。这个一般看你电脑显存。跟着batch-size一起调就行。主要报错信息如下:

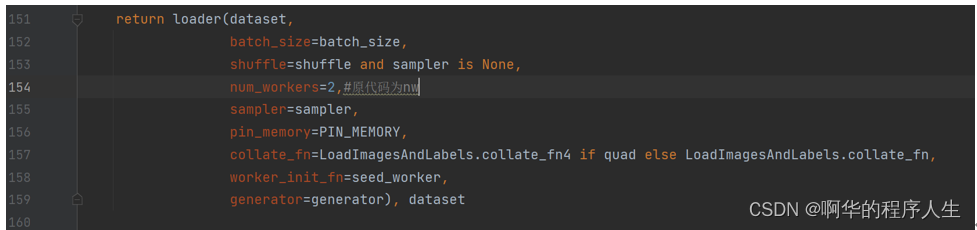
当然就算调整了上面俩个参数也还是可能会出现运行程序出现分页面文件太小,无法完成操作的问题;,接下来我们就还需要调整一个参数,这个参数再utils文件夹下的dataloaders.py文件,大概在154行左右(上下浮动)有一个num_works参数,把它调小一点即可,我这里调的2,原来为nw.
这个原因最主要还是虚拟内存不够导致的,如果还是出现运行程序出现分页面文件太小,无法完成操作的问题,就要去调整该代码文件所在磁盘的虚拟内存了,怎么调自己去搜索,就搜索怎么调整自己电脑的虚拟内存就行。解决这个问题后还需要调整一个参数,device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备),这里填个0就行。之后就可以跑起来了,看起来并不是很复杂。
当然如果程序启动过程中又出现了如下错误:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.
Process finished with exit code 3
类似这样的问题,本问题出现主要是因为torch包中包含了名为libiomp5md.dll的文件,与Anaconda环境中的同一个文件出现了某种冲突,所以需要删除一个。
我们需要删除Anaconda中的该文件,文件路径一般在安装位置里面的\Library\bin\libiomp5md.dll*,当然这是在base环境下,如果你运行的环境是你新建的一个环境,如果是在某个env(例如名为work)下:删除*…\Anaconda3\envs\work\Library\bin\libiomp5md.dll*
这样就可以运行了。
之后基本是便可以开始训练了。
训练完成后出现的各个指标含义如下:
P: 表示准确率,给出了“预测为真值的样本中确实有多少比例为真值”,
R:表示召回率,给出了“本来就是真值的样本模型预测出来了多少”。
训练完成后会在runs文件夹里面的weights文件里面生成2个文件,best.pt last.pt,
分别代表训练的最好的权重文件和最后一次权重文件,一般用最好的权重文件,
然后去到delect.py文件下,找到—weight这个参数,改成best.py文件的路径即可。如图:

注意—source参数,代表要预测东西的来源,default=ROOT / 'data/images'
代表预测根目录下data文件夹下images里面的图片
default=ROOT / 'data/video'
代表预测根目录下data文件夹下video里面的视频
如果default=0代表要调用本地摄像头来进行预测
那么好,利用yolov5训练自己的数据集我们已经讲完了,但还有一个问题我们需要讲解如果制作数据集过程中要标注的数据图片数量过多怎么办?我们难道还要一张一张去标注吗?后面我来为大家介绍如何利用yolov5来进行半自动辅助标注。
















 1911
1911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









