







 该文详细介绍了如何下载和运行yolov5开源项目,包括下载预训练权重,运行detect.py进行测试,标注和转换自定义数据集,以及使用这些数据训练模型。作者强调了标注和配置文件的正确性,并提供了训练命令。文章最后指出,尽管使用了迷你数据集,实际目标检测效果可能不佳。
该文详细介绍了如何下载和运行yolov5开源项目,包括下载预训练权重,运行detect.py进行测试,标注和转换自定义数据集,以及使用这些数据训练模型。作者强调了标注和配置文件的正确性,并提供了训练命令。文章最后指出,尽管使用了迷你数据集,实际目标检测效果可能不佳。
下载yolov5开源项目
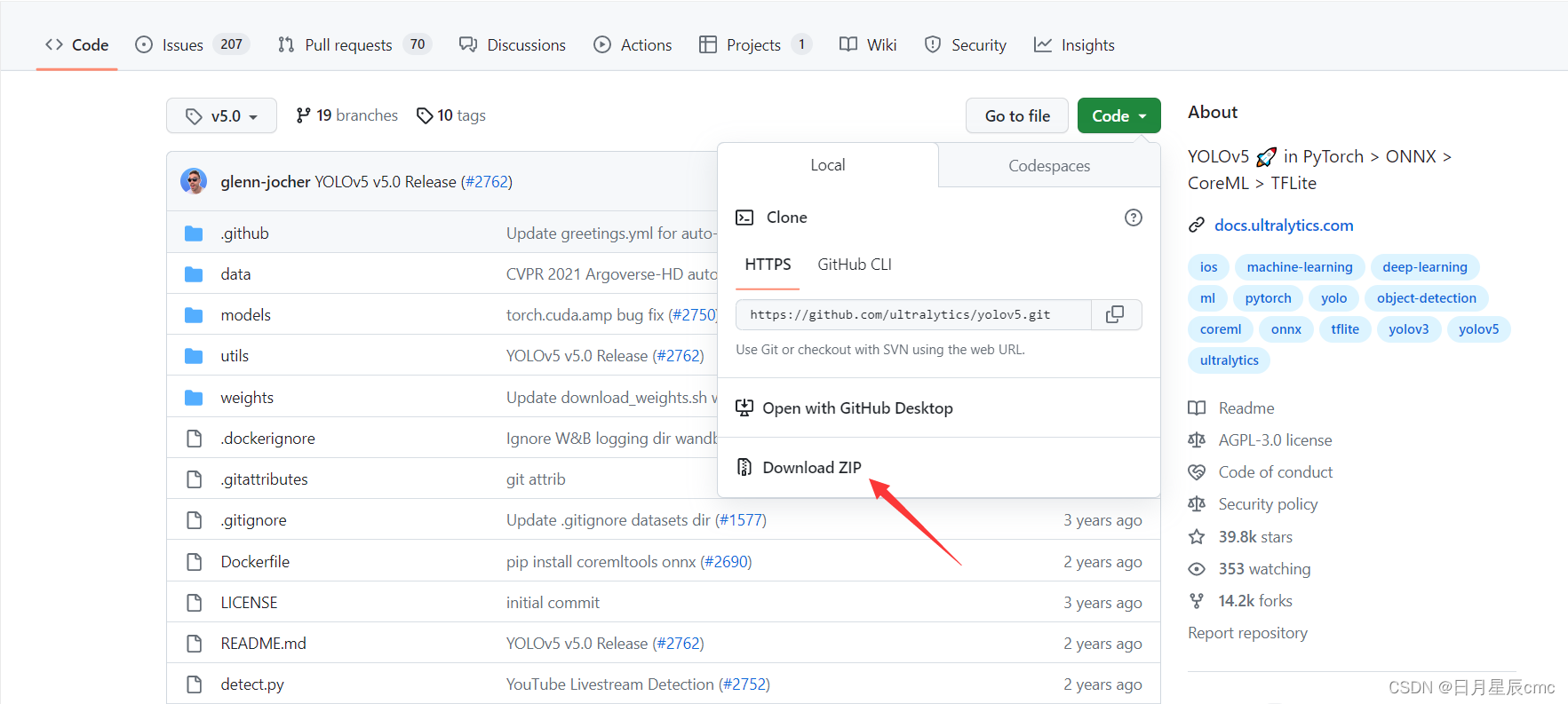
将整个yolov5压缩包下载下来(注意路径不要有中文),发现是没有预训练权重文件的,这时我们要自己下载一个,这里我下载yolo5s.pt
运行一下yolov5的detect.py文件
这里运行是应为这个项目可能遇到一些问题,先解决一下。这里我一遍就过了,如果有问题的话,就请各位观众老爷们自己去寻找了。
如果在runs/detect里面看到这张图片,那么恭喜你成功了。

开始yolov5训练自己的数据集
先标注好自己要训练的数据集
标注的办法我用labelimg。这里我仅简单标注20张图片,分为Person和Dog个类别,用于演示。
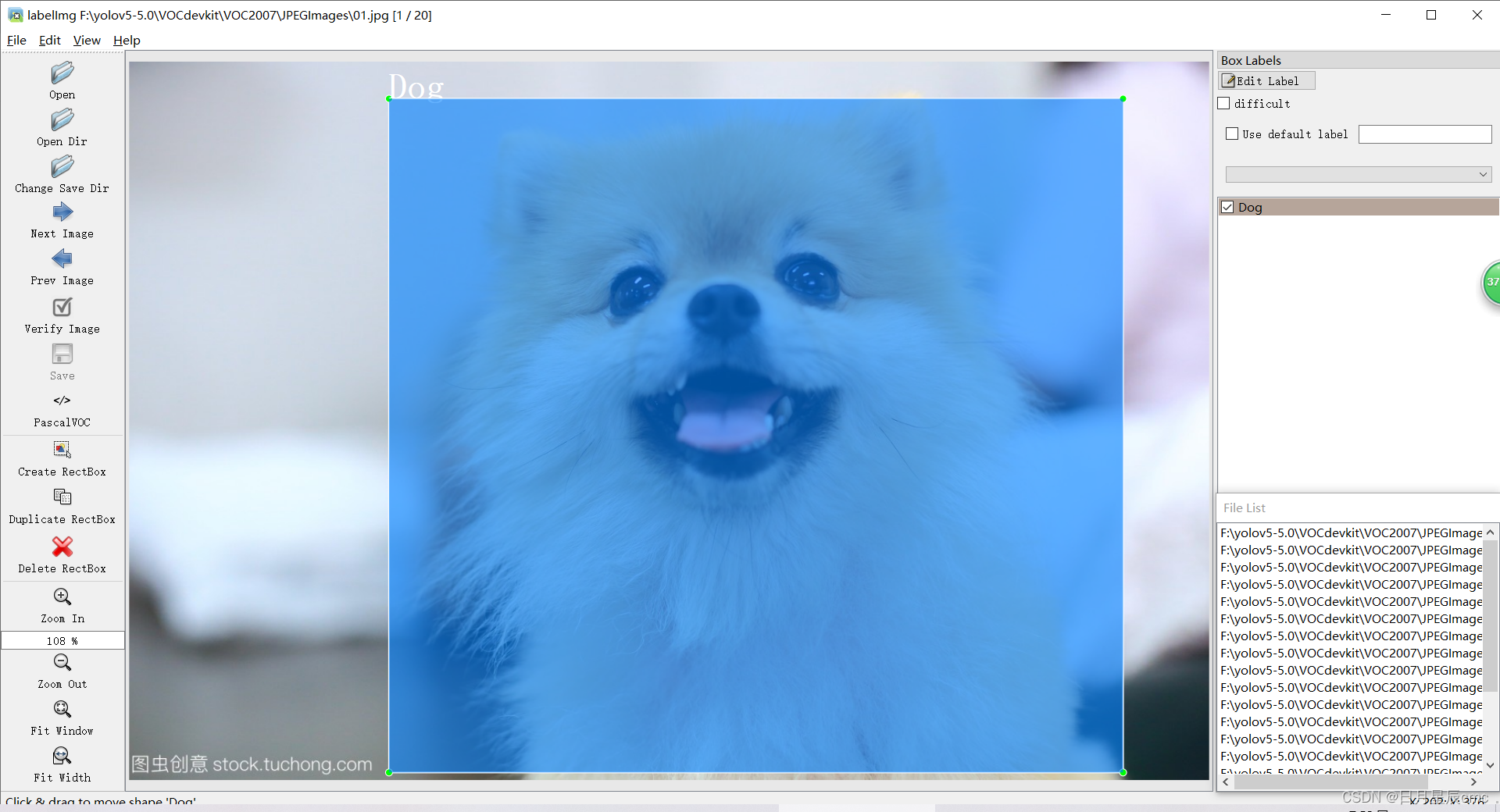
然后检查一下这些xml文件,看看有没有问题。
将xml文件转换为yolo可以识别的txt文件
这里我有一个python脚本,你可以随意命名一下,复制后新建在你的yolov5目录下。这里我命名为prepare_data.py。这里我强调一下要注意两点:
1.数据集的路径别输错了。
2.如果你是自己的数据集,请修改这里的classes类别,务必修改为和你打标签时一样的类别。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ['Dog', 'Person']
#classes=["ball"]
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
# in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id, encoding='UTF-8')
# out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w')
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w', encoding='UTF-8')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if(prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
好了之后,运行代码,结束后检查一下txt文件看看有没有东西。每运行一步都检查一下,步步为营。
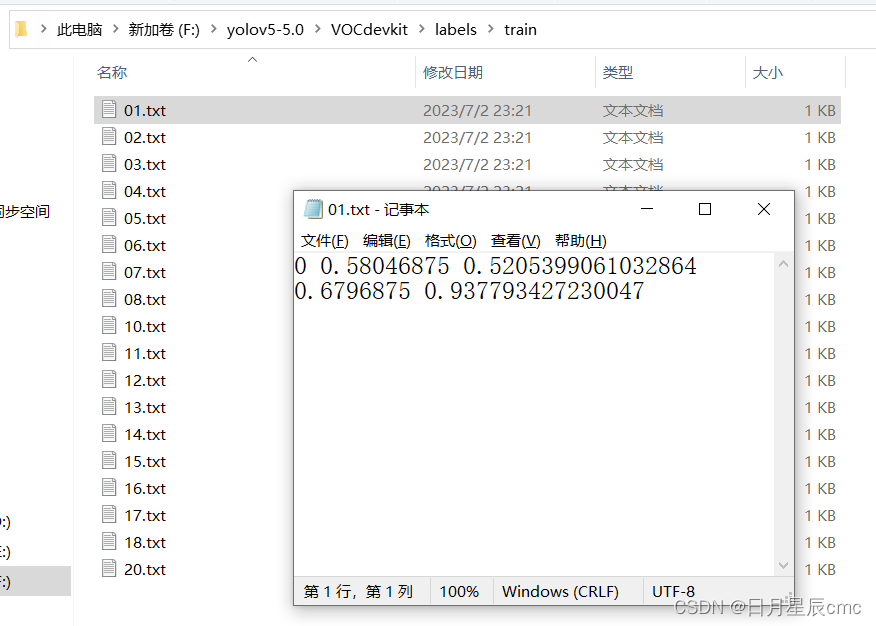
修改一些配置文件
首先要在data文件夹里新建一个配置文件myvoc.yaml。修改为你的类别。
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC/
# Train command: python train.py --data voc.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /VOC
# /yolov5
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: F:/yolov5-5.0/VOCdevkit/images/train
val: F:/yolov5-5.0/VOCdevkit/images/val
# number of classes
nc: 2
# class names
names: [ 'Dog', 'Person' ]
然后是model文件夹里复制一下yolo5s.yaml并命名为yolo5s_mine.yaml。修改类别的数量。本来nc是80,这里我改为2
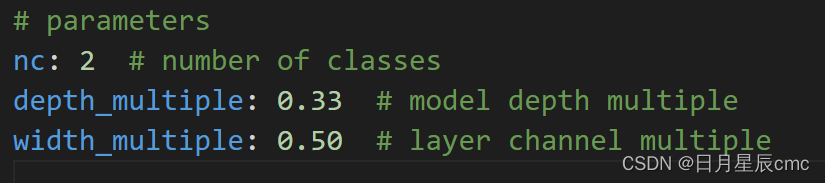
开始训练
python train.py --weights yolov5s.pt --cfg models/yolov5s_mine.yaml --data data/myvoc.yaml --epoch 50 --batch-size 4 --img 640 --device cpu在终端中输入这条命令。这条命令的意思是用yolov5.pt这个预训练权重文件,用我们配置的文件,训练50轮,一组为4张图片,用cpu跑。

如果你看到了这种进度条的话,那么你已经成功了。
只用cpu训练的时间一般很长,看个人电脑配置,我这里这个迷你数据集就训练了快十分钟了
查看结果
在runs/train可以看到训练结果。weights文件夹里有你的训练好了的权重文件best.pt和last.pt。
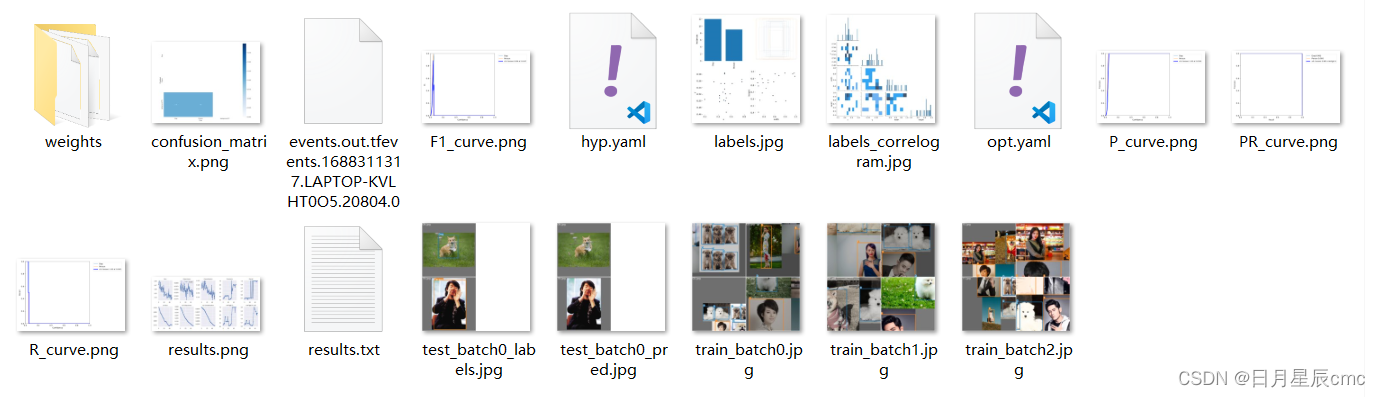
同时还有一些关于训练结果的各种参数。
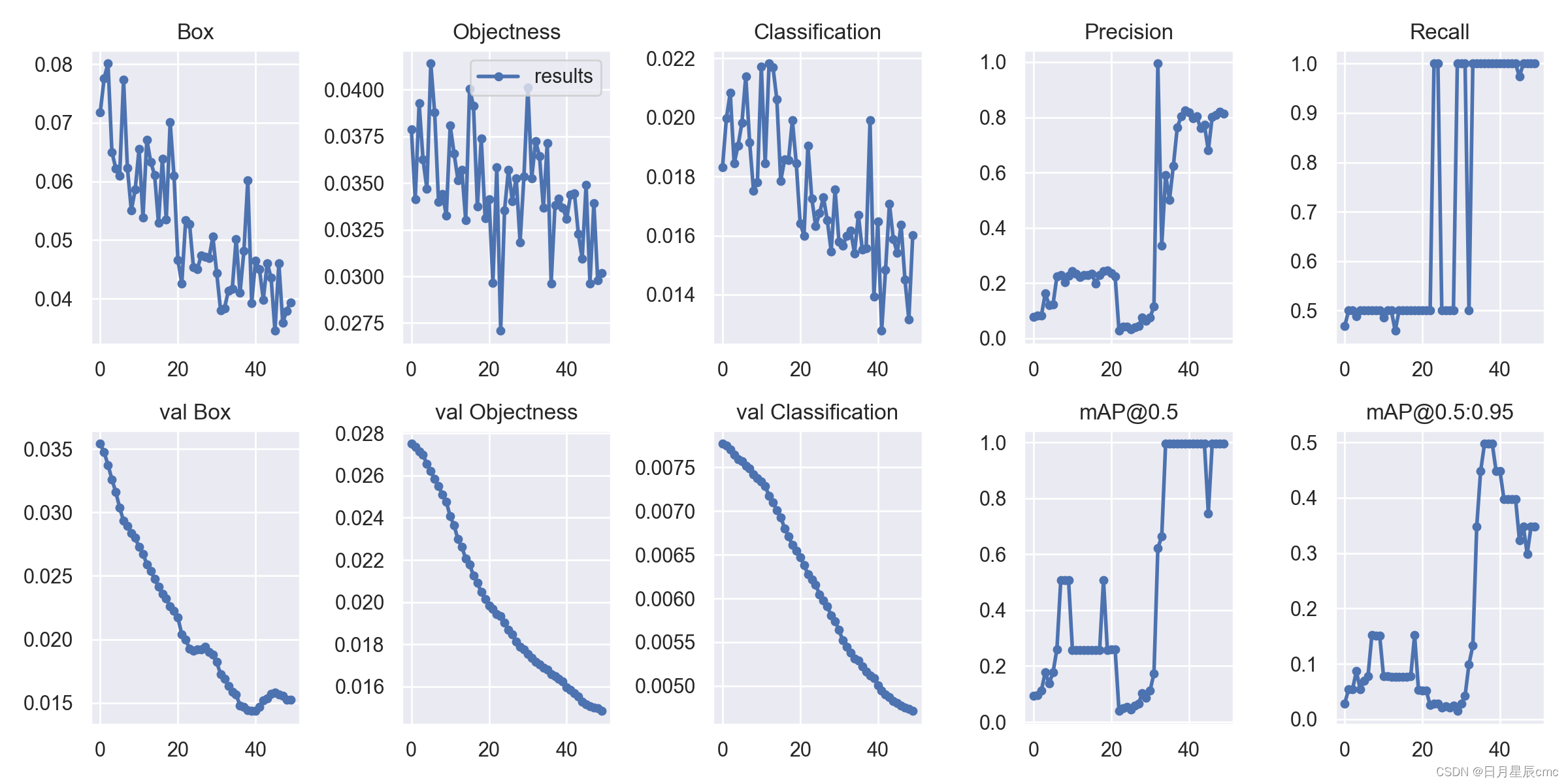
最后,问题来了,这个仅由20张图片构成的迷你数据集能不能目标检测人和狗呢?
当然是啥也测不出来。

















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









