







目录
前言
在这篇博客中我将介绍如何使用C++和Qt来创建一个简单的网页爬虫,用于从笔趣阁(beqege.com)上爬取小说内容。这个示例将演示如何使用Qt的网络访问类和正则表达式来获取和处理网页内容,并将小说章节保存到本地文本文件。
一、准备工作
在开始之前,确保你已经安装了Qt,并且创建了一个Qt控制台应用程序项目。同时在运行程序之前,请确保已经在Qt项目的.pro文件中添加了网络访问模块的依赖
QT += network
二、网页分析
1.分析笔趣阁网页
我们需要分析目标网站的URL结构以了解如何访问和抓取网页内容。在本示例中,我们选择了 笔趣阁 作为目标网站。笔趣阁上的每本小说都有一个唯一的ID,因此我们需要使用不同的ID来访问不同的小说。
每本小说的主页URL如下:
https://www.beqege.com/[书籍ID]/
为了获取小说的章节列表,我们需要分析小说主页上的HTML源代码。章节的URL排布如下:
<dd><a href="/63327/844361.html">第一章 床底</a></dd>
<dd><a href="/63327/844362.html">第二章 逝者关怀公司</a></dd>
<dd><a href="/63327/844363.html">第三章 坐起</a></dd>
<!-- 更多章节... -->
我们可以看到,每个章节都有一个URL和章节标题。为了提取章节URL,我们可以使用如下正则表达式:
QRegularExpression urlRegex("<dd><a href=\"([^\"]+)\">([^<]+)</a></dd>");
2.分析小说的具体章节网页
在抓取章节内容之前,我们需要分析小说的具体章节网页结构。小说的章节网页包含一系列HTML段落(<p>标签)来显示章节内容。示例如下:
<div id="content">
<p>昏黄的路灯下,杰夫将一根几乎烧到过滤嘴的烟头丢在了地上。</p>
<p>随即,</p>
<p>他的目光快速向两侧张望,同时习惯性地用皮鞋底踩住烟头,来回摩擦。</p>
<p>“嘶……该死……”</p>
<p>杰夫用力甩脚,他忘记了自己鞋底早就磨得很薄近乎可以透气了,这下子被烫到了脚底板。</p>
</div>
要提取章节内容,我们可以使用如下正则表达式:
QRegularExpression contentRegex("<p>(.*?)</p>");三、爬虫流程
1.启动爬虫流程
我们从创建一个函数开始,命名为process。process函数作为整个爬虫流程的入口点,它负责协调网络请求、响应处理和文件保存,从而完成小说内容的抓取。
void process(QString id) {
// 创建一个网络请求,指向小说的主页
QNetworkRequest request(QUrl(baseUrl + "/" + id + "/"));
QNetworkReply *reply = manager.get(request);
// 连接信号槽,等待响应完成
QObject::connect(reply, &QNetworkReply::finished, [=]() {
if (reply->error() == QNetworkReply::NoError) {
// 响应正常时,处理响应数据
// 提取小说的名称、提取每个章节的URL并逐一抓取章节内容
} else {
// 请求失败时,处理错误
}
// 处理完响应后释放reply对象
});
}
2.提取小说信息
在process函数中,我们首先创建一个网络请求对象,指向小说的主页。然后,我们通过manager发送请求,并等待响应的完成。如果响应正常,我们提取小说的名称和每个章节的URL,并逐一抓取章节内容,然后将内容保存到本地文件。最后,爬虫结束时,我们退出应用程序。
void process(QString id) {
// 创建一个网络请求,指向小说的主页
QNetworkRequest request(QUrl(baseUrl + "/" + id + "/"));
QNetworkReply *reply = manager.get(request);
// 连接信号槽,等待响应完成
QObject::connect(reply, &QNetworkReply::finished, [=]() {
if (reply->error() == QNetworkReply::NoError) {
// 响应正常时,处理响应数据
QByteArray responseData = reply->readAll();
QString responseString = QString::fromUtf8(responseData);
// 提取小说的名称
QRegularExpressionMatchIterator matchIterator = bookNameRegex.globalMatch(responseString);
QRegularExpressionMatch match = matchIterator.next();
bookName = match.captured(1);
// 提取每个章节的URL并逐一抓取章节内容
matchIterator = urlRegex.globalMatch(responseString);
match = matchIterator.next();
while (match.hasMatch()) {
QString url = match.captured(1);
qDebug() << url;
readNovel(url); // 调用readNovel函数抓取章节内容
match = matchIterator.next();
}
qDebug() << "爬取结束";
QCoreApplication::quit(); // 爬虫结束,退出应用程序
} else {
// 请求失败时,处理错误
qDebug() << "Error: " << reply->errorString();
}
// 处理完响应后释放reply对象
reply->deleteLater();
});
}
3. 抓取章节内容
在process函数中,我们调用了readNovel函数来抓取每个章节的内容。下面是readNovel函数的实现:
void readNovel(QString url) {
// 创建一个网络请求,指向章节的URL
QNetworkRequest request(QUrl(baseUrl + url));
QNetworkReply *reply = manager.get(request);
QEventLoop loop;
// 连接信号槽,等待响应完成
QObject::connect(reply, &QNetworkReply::finished, &loop, &QEventLoop::quit);
// 进入事件循环等待请求完成
loop.exec();
if (reply->error() == QNetworkReply::NoError) {
// 响应正常时,处理章节内容并保存到本地文件
} else {
// 请求失败时,处理错误
}
// 处理完响应后释放reply对象
reply->deleteLater();
}
在readNovel函数中,我们创建一个网络请求对象,指向章节的URL,并通过manager2发送请求。然后,我们使用事件循环等待响应完成。如果响应正常,我们提取章节内容并将其保存到本地文件。
四、完整代码
下面是完整的C++和Qt爬虫代码,包括上述讨论的各个部分:
#include <QCoreApplication>
#include <QNetworkAccessManager>
#include <QNetworkReply>
#include <QNetworkRequest>
#include <QUrl>
#include <QJsonDocument>
#include <QJsonObject>
#include <QDebug>
#include <QUrlQuery>
#include <QJsonArray>
#include <QFile>
#include <QTextStream>
QString bookName;
QString baseUrl("https://www.beqege.com");
QRegularExpression urlRegex("<dd><a href=\"([^\"]+)\">([^<]+)</a></dd>");
QRegularExpression contentRegex("<p>(.*?)</p>");
QRegularExpression bookNameRegex("<h1>(.*?)</h1>");
QRegularExpression titleRegex("var readtitle = \"(.*?)\";");
QNetworkAccessManager manager;
void readNovel(QString url){
if(url.contains(".html")){
QNetworkRequest request(QUrl(baseUrl+url));
QNetworkReply *reply = manager.get(request);
QEventLoop loop;
// 连接信号与事件循环的退出
QObject::connect(reply, &QNetworkReply::finished, &loop, &QEventLoop::quit);
// 进入事件循环等待请求完成
loop.exec();
if (reply->error() == QNetworkReply::NoError) {
QByteArray responseData = reply->readAll();
QString responseString = QString::fromUtf8(responseData);
//章节名
QString title = titleRegex.match(responseData).captured(1);
qDebug()<<"正在爬取 "<<title;
//正则匹配小说内容
QRegularExpressionMatchIterator contentMatches = contentRegex.globalMatch(responseString);
//将内容写入txt
QFile file(bookName+".txt");
if (file.open(QIODevice::Append | QIODevice::Text)) {
QTextStream stream(&file);
stream << title << "\n\n";
while (contentMatches.hasNext()) {
QRegularExpressionMatch contentMatch = contentMatches.next();
QString contentLine = contentMatch.captured(1);
stream << contentLine << "\n";
}
stream << "\n";
file.close();
} else {
qDebug() << "无法打开文件保存章节内容。";
}
} else {
qDebug() << "Error: " << reply->errorString();
}
reply->deleteLater();
} else {
qDebug()<<"异常结束";
QCoreApplication::quit();
}
}
void process(QString id){
QNetworkRequest request(QUrl(baseUrl+"/"+id+"/"));
QNetworkReply *reply = manager.get(request);
QObject::connect(reply, &QNetworkReply::finished, [=]() {
if (reply->error() == QNetworkReply::NoError) {
// 请求成功,处理响应内容
QByteArray responseData = reply->readAll();
QString responseString = QString::fromUtf8(responseData);
//提取书名
QRegularExpressionMatchIterator matchIterator = bookNameRegex.globalMatch(responseString);
QRegularExpressionMatch match = matchIterator.next();
bookName=match.captured(1);
//提取每一章的url,传入readNovel函数爬取对应章节内容
matchIterator = urlRegex.globalMatch(responseString);
match = matchIterator.next();
while(match.hasMatch()){
QString url=match.captured(1);
qDebug()<<url;
readNovel(url);
match = matchIterator.next();
}
qDebug()<<"爬取结束";
QCoreApplication::quit();
} else {
// 请求失败,处理错误
qDebug() << "Error: " << reply->errorString();
}
// 记得在处理完响应后释放reply对象
reply->deleteLater();
});
}
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
process("1");
return a.exec();
}
五、效果展示
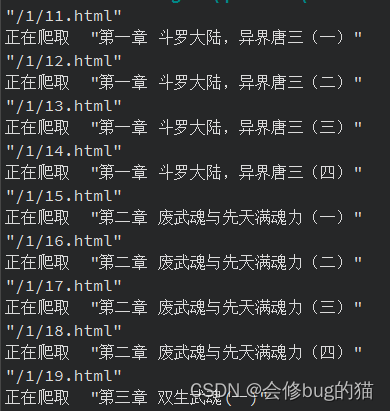
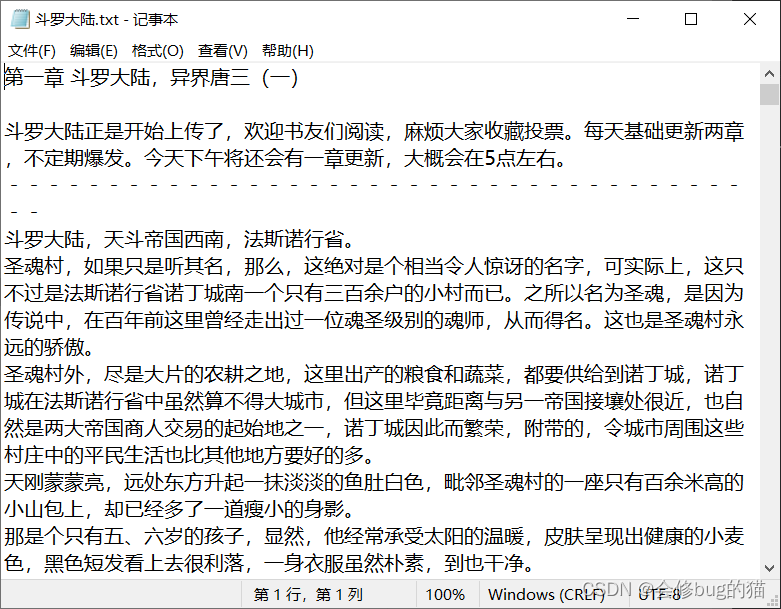
总结
通过这个示例,以爬取笔趣阁小说内容,简单介绍了如何使用C++和Qt创建一个简单的网页爬虫。
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











