







概述
Pod 是k8s 系统中可以创建和管理的最小单元
k8s 不会直接处理容器,而是 Pod
Pod 是由一个或多个container (容器)组成
一个pod中容器共享网络命令空间(如果一个pod里面有三个容器,那么这三个容器之间的网络是共享的)
pod是短暂存在的(假设一个pod重新创建或启动后,其ip是会变化的)
每一个 Pod 都有一个特殊的被称为”根容器“的 Pause容器
Pause 容器对应的镜 像属于 Kubernetes 平台的一部分,除了 Pause 容器,每个 Pod还包含一个或多个紧密相关的用户业务容器

pod存在的意义
(1)创建容器使用docker,一个docker对应一个容器,一个容器有进程,一个容器运行一个应用程序
创建一个容器(docker),docker的设计是一个单进程,而一个容器运行一个应用程序,当然也可以运行多个,但是现在多个的话是不方便管理的
(2)pod是多进程设计,运行多个应用程序
一个pod里面有多个容器,每个容器里面都可以运行一个应用程序
(3)Pod的存在也是为了亲密性应用
- 两个应用或多个
应用直接进行交互(一个pod里面的多个容器进行信息的交互)- 里面的容器进行
网络直接的调用(一个Pod里面的多个容器进行网络调用时,可以通过socket和127.0.0.1等进行网络的调用)- Pod里面的
多个应用需要频繁调用
Pod的实现机制
机制一:共享网络
容器使用docker创建,所以容器本身之间是相互隔离的,这个隔离是通过Linux中的namespace和group进行隔离的
在pod中有多个容器,那么在Pod里面是怎么实现共享网络的?
共享网络的前提条件:
- 容器在同一个namespace里面
pod的实现:
- Pod里面有多个容器,在pod的操作中,首先会创建一个容器,这个容器是pod自己默认创建的根容器:Pause,也被称为info容器
- 当在pod里面创建业务容器时,这些业务容器都会加入到info容器/Pause里面,加入之后,info容器便会独立出一个地方有IP地址、mac地址、port,并且加入的容器都会有同一个namespace。
- 这些创建的容器便会生成对应的信息,存放到同一个namespace里面,然后,他们便会共享同一个ip、mac和port
- 简单来说,就是通过一个Pause容器,将创建的业务容器加入到同一个namespace空间中,实现网络的共享
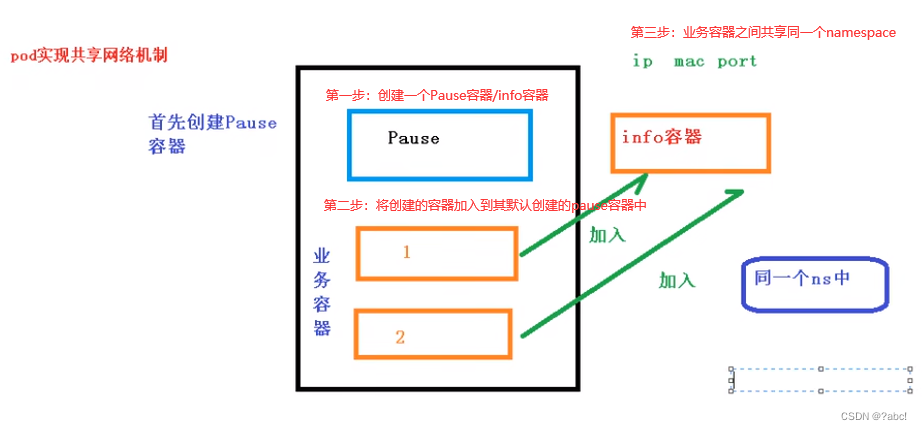
总结:通过Pause容器,把其他业务容器加入到Pause容器里面,让所有业务容器在同一个名称空间中,可以实现网络共享
示例如下:
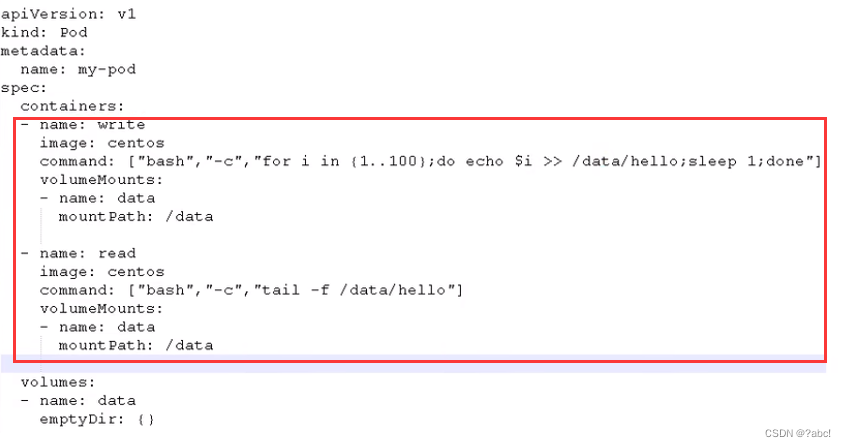
在一个 Pod 里的多个容器共享 Pod 的 IP 和端口 namespace,所以一个 Pod 内的多个容器之间可以通过 localhost 来进行通信,所需要注意的是不同容器要注意不要有端口冲突即可。不同的 Pod 有不同的 IP,不同 Pod 内的多个容器之前通信,不可以使用 IPC(如果没有特殊指定的话)通信,通常情况下使用 Pod的 IP 进行通信
机制二:共享存储
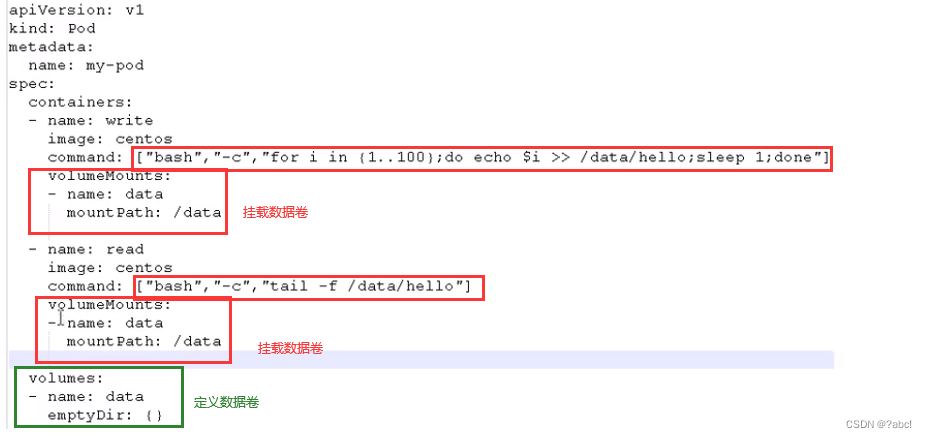
一个 Pod 里的多个容器可以共享存储卷,这个存储卷会被定义为 Pod 的一部分,并且可 以挂载到该 Pod 里的所有容器的文件系统上。
在pod的容器中操作的时候,会产生许多的数据,而这些数据,当这些数据需要一直使用,这时候便需要对这些数据进行持久化
比如持久化操作日志数据、业务数据
这个持久的操作是怎么实现的?
如当有三个node节点,在node节点上可以去创建pod,当第一个节点node1挂掉了,那么这时候就需要其他节点去操作,这时候便需要去获取node1的数据去重新创建运行镜像
这个持久化的操作,便使用了数据卷(Volumn)这个概念去解决
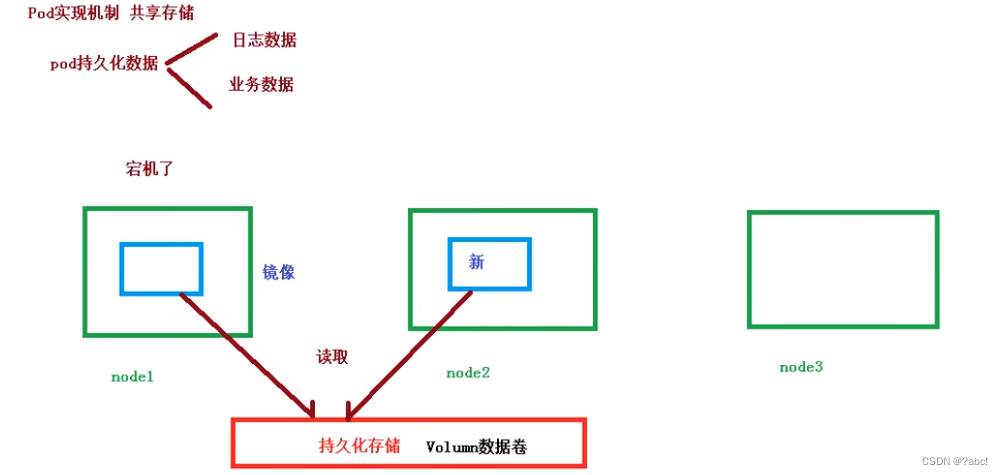
总结:引入数据卷概念Volumn,使用数据卷进行持久化存储
示例如下:
Pod镜像拉取策略
在其pod的配置文件中,有这么一段,其中圈住的便是对该pod的该镜像拉取时,所做的策略配置,这种策略一共有三种:
- IfNotPresent:默认,镜像在宿主机上不存在时才拉取
- Always:每次创建Pod都会重新拉取一次镜像
- Never:Pod永远不会主动拉取这个镜像

Pod资源限制
在pod创建后,会调度到某一个node节点上去,在调度过程中有这么一个特点:举例如下
- 当前集群中有三个node节点:node1(2核4g内存)、node2(4核16g内存)、node3(1核2g内存);pod至少要一个支持2核4g的要求
- 当pod在创建后,node1和node2满足要求,node3不满足
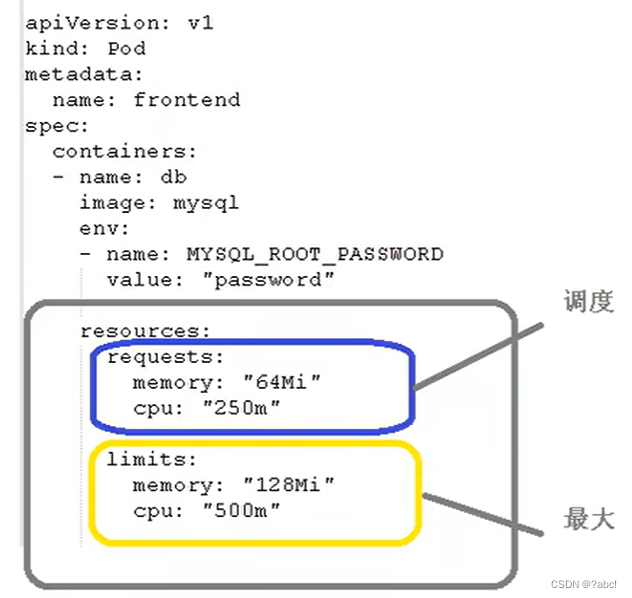
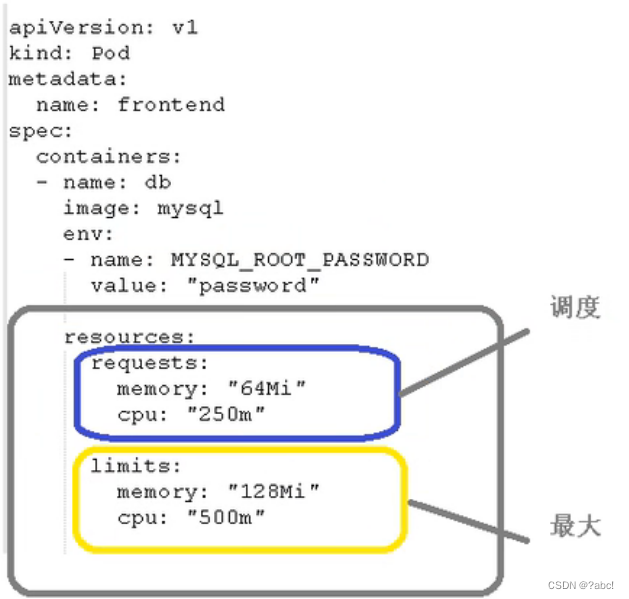
这个所做的配置在如下图所示的位置(cpu大小:1核等于1000m)
- requests:在pod调度时所做的限制:cpu250m、内存64m;通过这个限制去找到对应的node节点
- limits:限定调度时,最大的大小:cpu不超过500m、内存不超过128m
- 这两个配置便是限制最大是多大,没有最小
- 这个限制本身不是pod做到的,而是docker做到的,docker在创建pod里容器时做到这个资源的限制
Pod重启机制
当pod里面的容器终止或退出后,后续还要做什么操作(重启或结束等)
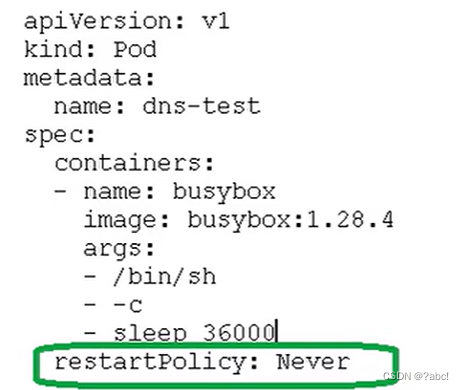
这个配置的设置是下面下面的yaml文件位置设置(框中内容),其有三种重启机制:
-
Always:当容器终止退出后,总是重启容器,默认策略。
用在不断提供服务的地方 -
onFailure:当容器异常退出(退出状态码非0)时,才重启容器。
其状态码如下框中所示

-
Never:当容器终止退出,从不重启容器。
当有一个批量任务,只需要执行一次
Pod健康检查
比如之前,我们需要检查k8s中集群的状态,通过容器检查是否正常运行,其检查的过程中有一个特点,如下,
- 通过查看,可以发现容器的目前状态是running的,输入这个容器是running状态,但是这个容器可能本身有问题,但是还是running状态

- 比如java中的java堆内存溢出,这个进程还存在,但是目前是不能提供服务
- 所以,通过容器检查,是不能检查其是否能正常提供服务的(虽然容器是running状态的)
在k8s集群中,要检查状态,是根据容器检查,但是虽然容器是running状态,但是有时候其是不能对外提供服务的,所以通过容器检查是不能正常检查其状态的
所以,便需要在应用层面进行检查,在k8s集群中提供了两种检查机制,可以通过这两个方法去检查,如下:
- livenessProbe(存活检查):如果检查失败,将杀死容器,根据Pod的restartPolicy来操作。
- readinessProbe(就绪检查):如果检查失败,Kubernetes会把pod从service endpoints中剔除。
Probe支持以下三种检查方法:
- httpGet:发送HTTP请求,返回200-400范围状态码为成功。
- exec:执行shel1命令返回状态码是0为成功。
- tcpsocket:发起TCP Socket建立成功。
举例如下:
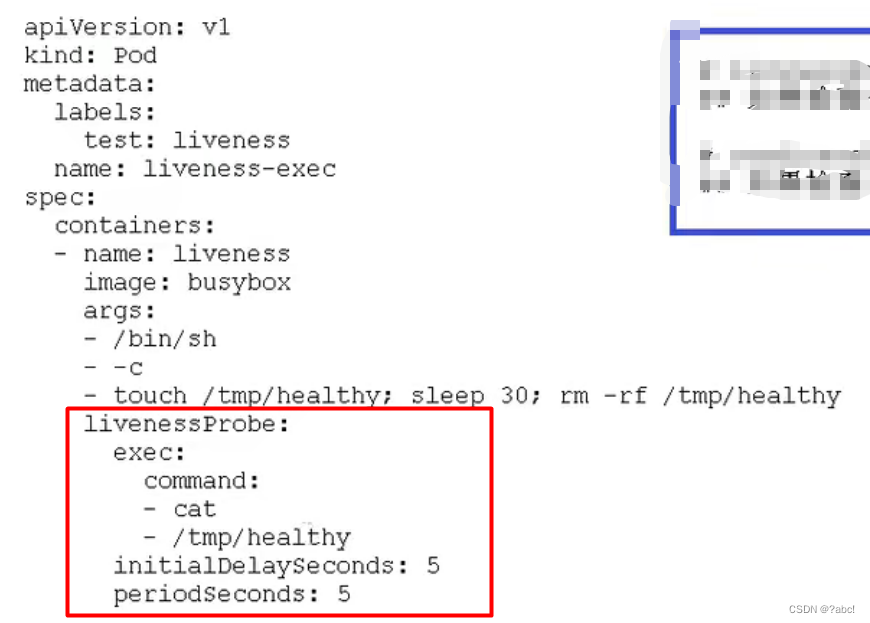
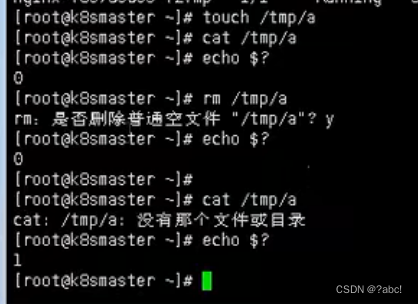
通过健康检查,集群的状态
Pod调度策略

创建Pod流程
先将总体的图给出,下面便对该图进行说明
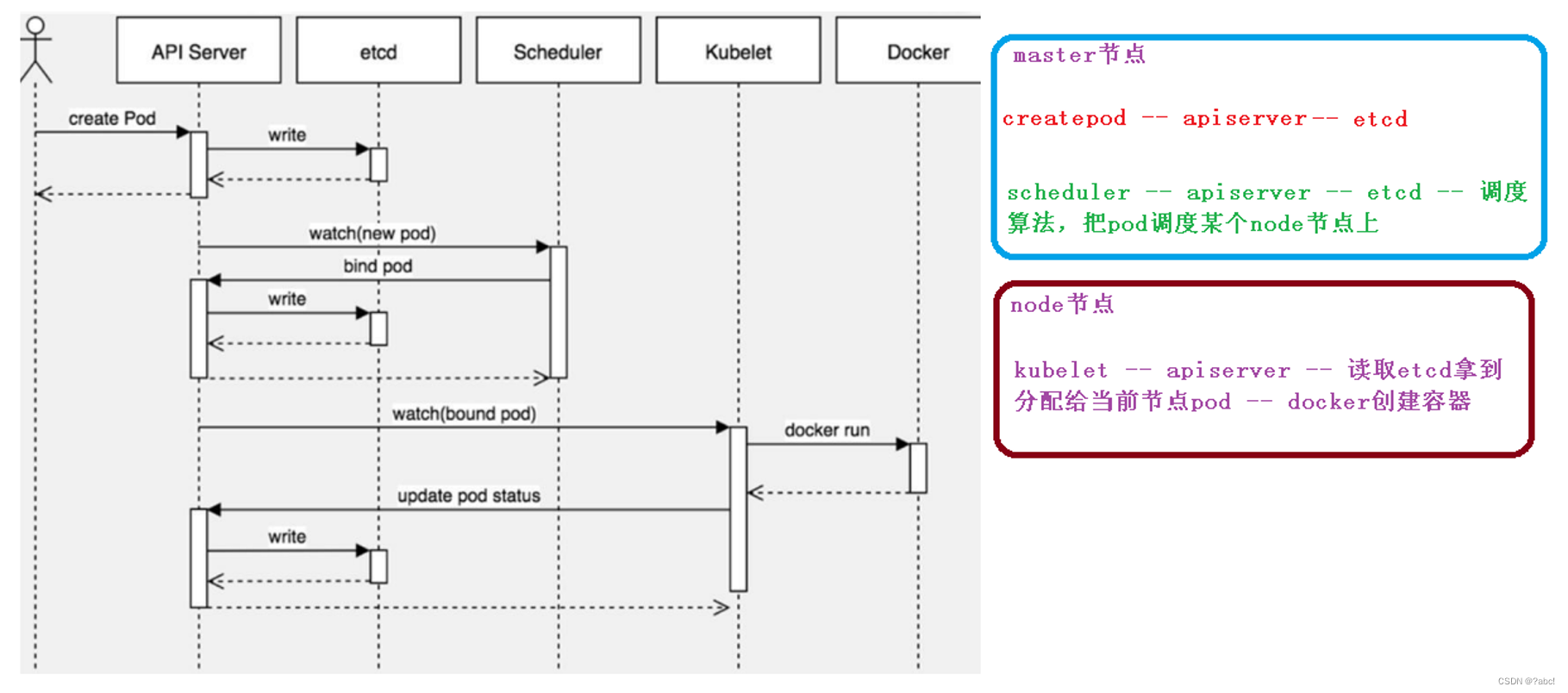
步骤如下:
- 创建一个pod,首先会进入到API Server里面,过后将其一些信息存储到etcd里面
- 这时候,scheduler通过监听,明白有没有新pod的创建,当有新pod创建后,其便会监听到其是否新pod的创建,当监听到有新pod创建后,便首先会到API Server里面,然后去etcd里面去读取到创建的那个pod,读取到过后,通过调度算法将其分配到某个的node节点中
- 上面的两个步骤,都是在master节点上进行的操作,过后便进入node节点上,第二步调度到某一个node节点后,便再会去对应的node节点做对应的操作,node节点上的操作如下:
- node节点里面有一个组件kubelet,通过kubelet,先去访问API Server,然后也会去读取etcd,拿到分配给当前节点的pod的信息(分配到了的话才会读取到,没有分配到便不会读取到),读取到过后,会通过docker去创建这个容器,创建之后,会将创建的状态返回给API Server,然后在etcd中存储
- 以上便是创建的过程
影响pod调度的属性
有下面三个影响属性
- Pod资源限制
- 节点选择器标签
- 节点亲和性
- 污点和污点容忍
Pod资源限制
Pod资源限制影响pod调用:上面说明过这个资源限制
- 在调度过程,这个限制,会在进行pod调度时,会根据request找到满足要求的node节点进行调度
节点选择器标签
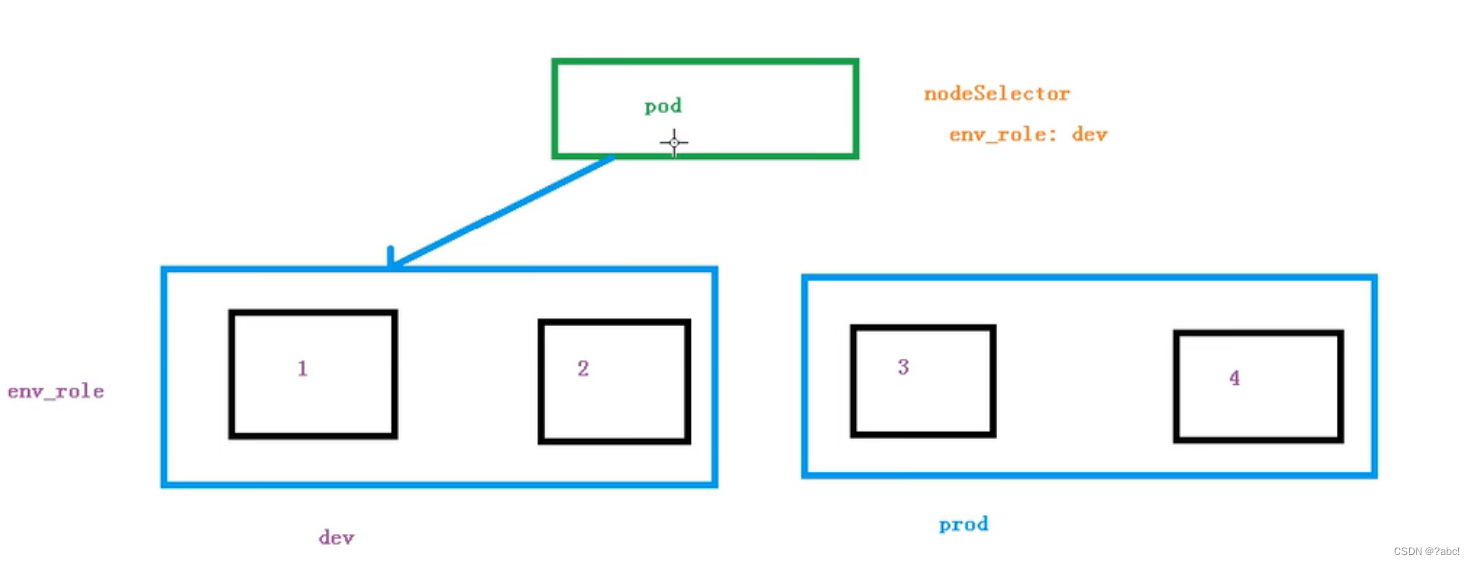
节点选择器标签影响pod调度:这个属性是在yaml文件里面配置的,如下
- 下面的配置说明的是将当前的node调度到dev(开发环境)中去

- 一个pod中有多个节点,这些节点分为不同的环境:如当前集群有四个node节点,node1和node2是开发环境(dev),node3和node4是p生产环境(prod),当在创建才pod的时配置了上面的节点选择器属性,那么在调度中,该pod便会在node1和node2这两个节点中进行调度
- 在进行这个操作时,之前便必须给node节点起一个别名,这个操作如下:给node1节点起一个标签名字dev,然后便可以在pod的配置文件里面进行配置

- 查看

节点亲和性
这个的配置也是在pod的yaml文件里面进行配置的,配置位置如下
- 节点亲和性 modeAffinit和之前nodeSelector基本一样的,根据节点上标签约束来绝对Pod调度到哪些节点上
但是modeAffinit的功能更加强大,nodeSelector需要k8s集群中的node节点有对应的标签,如果没有的话,便不能进行调度,处于等待状态。如果使用modeAffinit的话,即使没有这个节点,也可以继续向下运行,另外其还支持常用操作符。
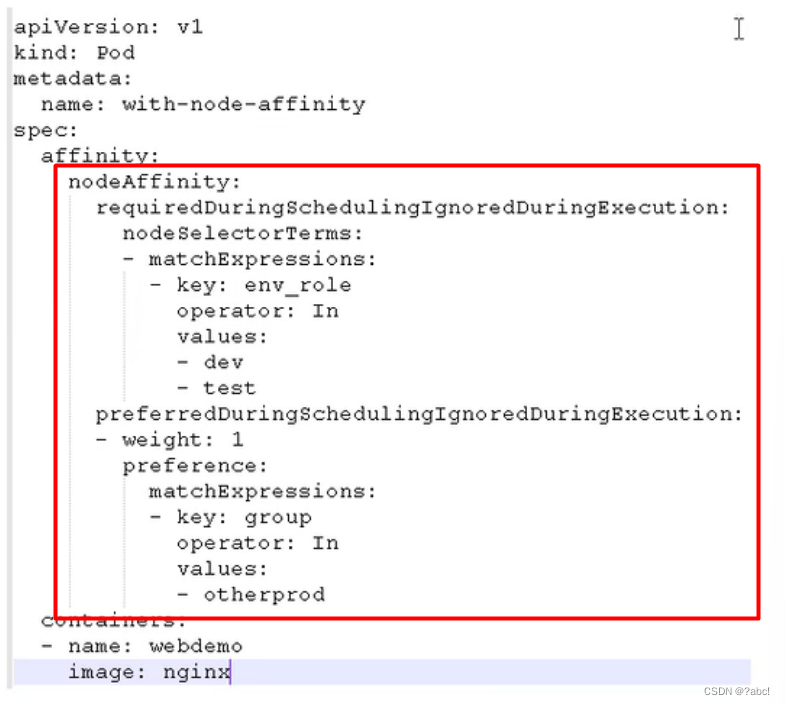
- 其有两种配置:
硬亲和性:约束条件必须满足,如果满足不了就处于等待状态,和nodeSelector类似
软亲和性:尝试满足,不满足的话也可以

这里也还可以配置一个属性:反亲和性,比如上面的DoseNotExists
污点(Taint)和污点容忍
modeAffinit和之前nodeSelector:都是将Pod调度到某些节点上,是Pod属性,在调度的时候实现
Taint污点:节点不做普通分配调度,是节点属性,其针对特定的场景进行分配,其使用的场景如下
- 专用节点
- 配置特点硬件节点
- 基于Taint驱逐:其本身不做分配,分配到当前节点以外的其他节点中去。比如集群有三个节点,node1和node2中加这个驱逐,那么创建的对应的pod将会分配到node3中去
演示:
- 会使用的一些命令
-
查看当前节点污点情况

-
污点中的值主要有三个
- NoScheduler:该节点一定不会被调到
- PreferNoScheduler:尽量不被调度,但是也有被调度的几率
- NoExecute:不会调度,并且还会驱逐到node已有的pod(当前节点不会调度,而且还会把节点驱逐到其他节点中去)
-
为节点添加污点
kubectl taint node [node节点主机名称:如node1/node2] key=value:污点三个值演示如下:
-
查看集群中node的情况
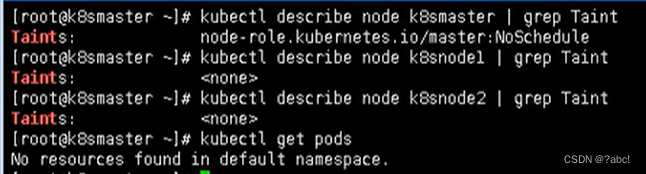
-
创建一个node,并查看情况


-
添加污点演示
删除所有的pod
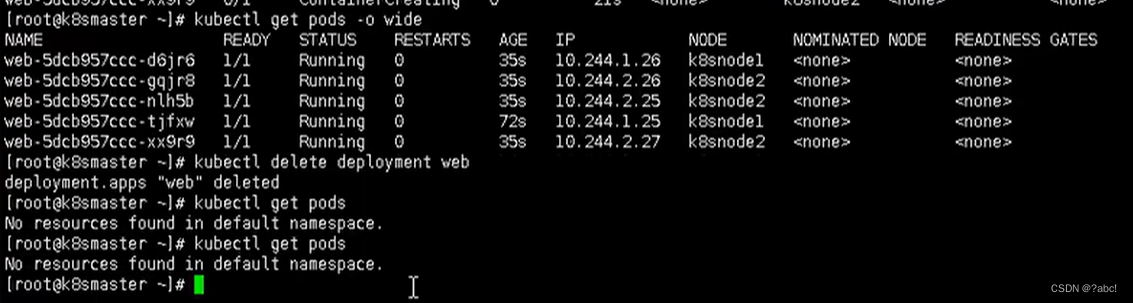
-
打污点

现在去创建pod,查看之前创建pod后的情况,可以发现现在创建的都是在node2这个节点上
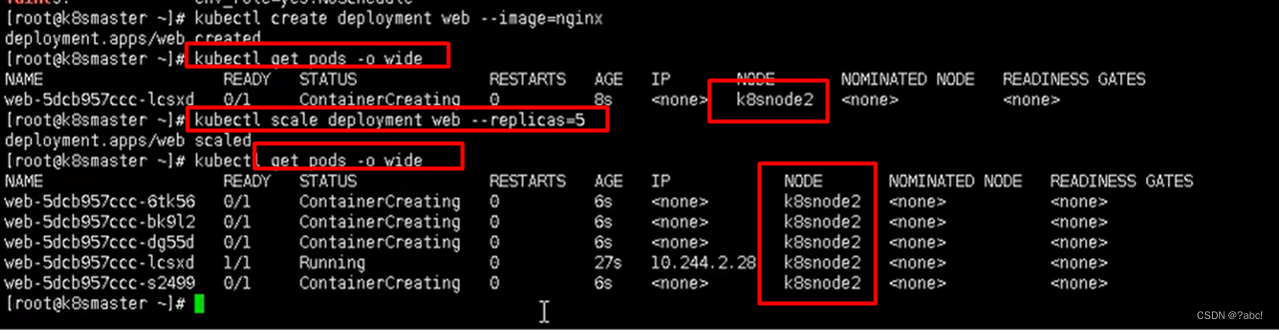
-
删除污点
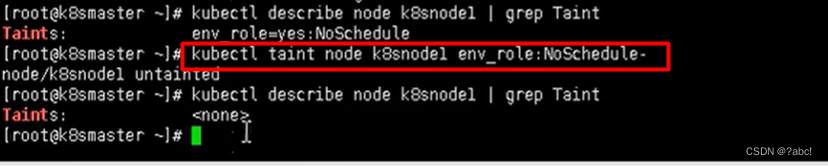
-
-
污点容忍:就算是设置值为NoSchedule(一定不会被调度)后,这个节点也可能会被调度到,有可能不会被调度到。
这个的实现其实也是在yaml文件中,做下面的修改下面配置中的key是之前设置的内容(比如之前我们设置的是env_role,NoSchedule,那么在这个地方key的值也为env_role和effect的值也是NoSchedule)

-

















 785
785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











