






如何你是不仅仅满足如何使用ES,而是想知道发动机内部原理的有追求的同学,可以看看这篇文档,有助于你在写入ES文档碰到奇怪问题时的排查,也有助于提高系统设计能力。
建索引(Indexing)
索引文件存储在磁盘中(结构高度优化)
建索引流程

创建文档
(将进来的文档(json)分析出多个Field,然后将这些Field组装进入Lucene的Document中)
Directory
Lucene采用了NIO和MMAP等先进的文件夹实现方式。
IndexWriter(我真的是核心!)
IndexWriter是负责写索引的核心。
index的逻辑单元segment是不可变的。
索引文件一旦写入,是不可变的(Immutable),只能追加(append only)。
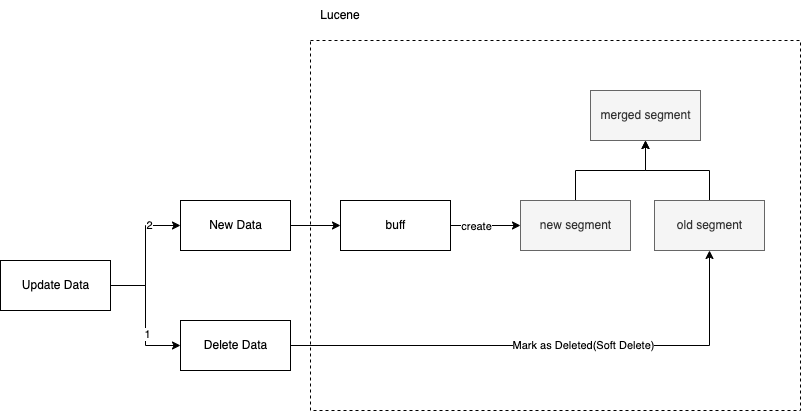
Lucene为每个并发分配一个DWPT。
DWPT(DocumentsWriterPerThread) 内的buffer,会生成一个segment(segment: lucene的数据logic unit)。
更细节的是:新写入的数据会暂存在translog文件里,在commit动作后,才会生成1个segment
这样,写索引和搜索是可以并行的(不需要锁)。
在flush之后,新进来的搜索才能查到刚才新增的segment数据。
如何触发Flush?
1 写入doc后触发
IndexWriter在写入一个doc后,会判断是否需要flush。
整个IndexWriter的所有DWPT的buffer达到阈值(堆内存的10%),则标记 DWPT中当前buffer最大的那个为 等待flush。
当前DWPT的buffer达到Lucene阈值(默认1945MB)
2 ES周期refresh
3 人手动refresh
执行Flush,会影响写入吗?
不会。
DWPT为等待Flush状态时,新的待写入数据不会进入这个DWPT(从perThreadPool中checkout出来了)
(下面这个图很全面)
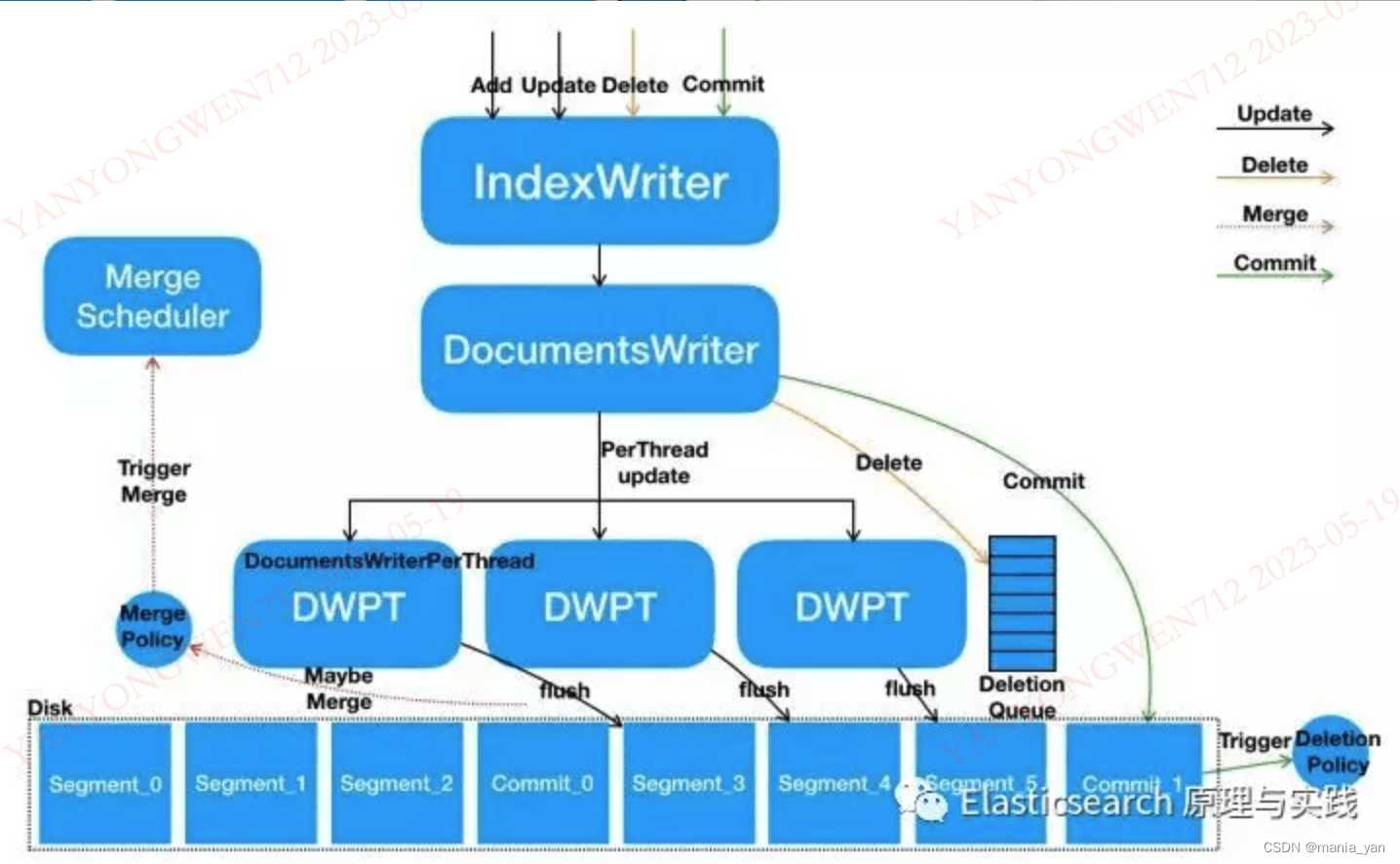
尽量批量插入文档
ES和常见的nosql数据库一样,具有读快写慢的特点(相比关系型数据库)。
ES内部的写过程是昂贵的,尽量采用ES的bulk api批量写入
采用bulk周期批量写入有如下优点:
- 明显的提高了写性能;
- 可以减少重复的写入(例如一个字段多次更新,实际只需要更新最后一次的结果)
删除文档
segment merge之前
由于segment是不可变的,实际的删除动作,不会变更segment,而是另外记录在其他文件(.liv, .dvm, .dvd)中。
正常的搜索,这些被删除的文档还是会被搜索到,但是会在过滤阶段,依据上述的文件过滤掉。
segment merge之后
在下一次segment merge中,这些待删除文档才会实际在segment中消失掉。
索引文件的结构
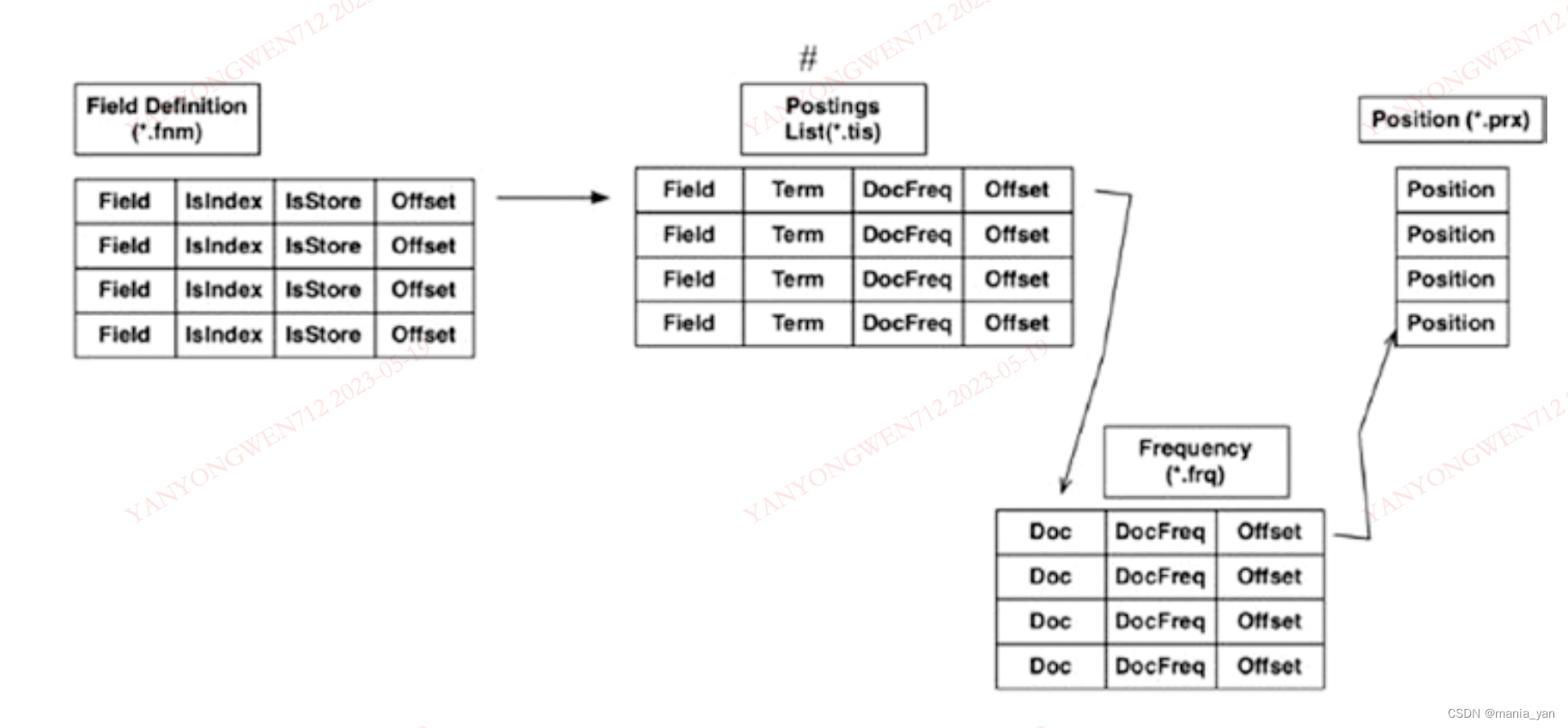
Field级别信息
Field Infos(.fnm)
其中,FieldBits(Byte)采用每个bit存储不同状态(不同功能开关的打开/关闭)
Term级别信息
Term Info文件(.tis)
存储term的metadata,以及可以帮助lucene构建高效访问term相关的文档的有用信息。
词频级别信息
Frequencies 文件(.frq)
包含某个term的文档信息(同时包含词频)
词位置级别信息
Positions 文件(.prx)
一个词在一个文档中的位置信息(positions)
搜索(Querying)
分为:
- Query预处理(Text Analysis)
- 检索
- 排序
Query预处理(Text Analysis)
Reference: Text analysis | Elasticsearch Guide [8.11] | Elastic
无论是建索引还是搜索,只要涉及Text类型,就会执行text analysis模块,具体为analyzer实施执行。

字符过滤器(character filters)
对字符流的增删改。
项目中用于 清洗Html样式的文本 (如:接收到的知识点正文内容是Html样式,需要通过character filter进行过滤清洗才能进入索引,否则会有很多杂乱无效的符号)。
分词器(tokenizer)
有且只能有一个。
(The tokenizer is also responsible for recording the order or position of each term and the start and end character offsets of the original word which the term represents.)token graph
词过滤器(token filters)
对词流的增删改。
最典型的应用为:
- 对词进行小写转换(lowercase)
- 去停用词(stop)
- 同义词替换(synonym)
(Token filters are not allowed to change the position or character offsets of each token.)
搜索
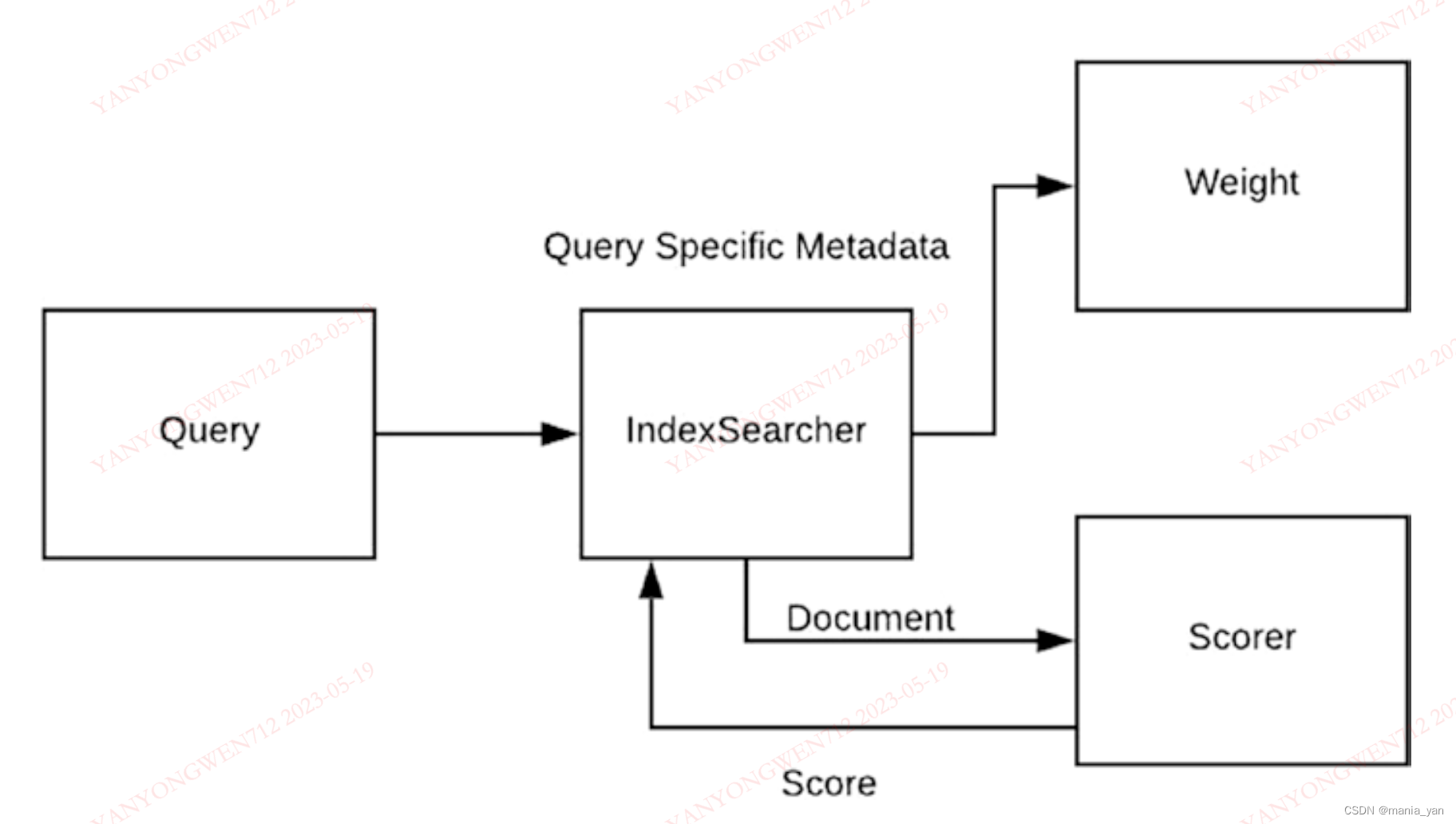
QueryCache
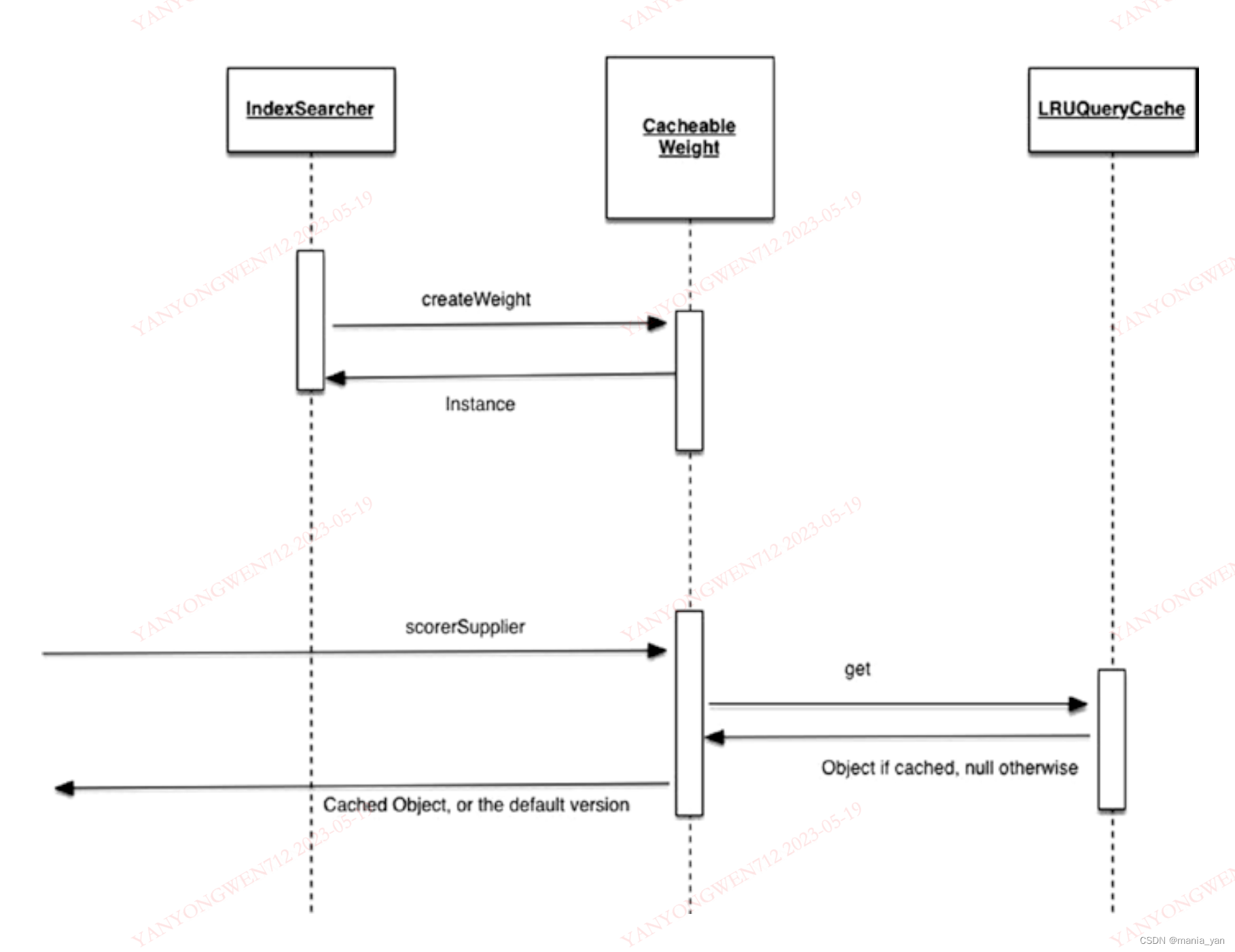
应用DocValues解决聚合功能
倒排索引的结构决定了,会丢失一些功能,如,根据Field分组,排序,分面(facet)等。为了解决如聚合等功能,引入docValues。
DocValues是一个列存储的结构。
排序
Scorer

打分算法
基于VSM(Vector Space Model, 向量空间模型),通过余弦相似度等算法来计算文档之间的相似度。
VSM是一个稀疏空间向量,总维度等于词袋里的词总数,向量里每个词位置的数字,就是TF*IDF等相似度算法的值(或其他如BM25)
注意:
打分是基于Field而不是Document。
(这种打分算法的缺点包含但不限于:将文档表示为上述的向量模型,会丢失词与词之间的关系信息)
Boost
Boost包含文档级,字段级与query级,影响最终相关性得分。
IndexReader
读取 postings, doc values, terms, stored fields的真实文件。 (原子操作)















 2819
2819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









