






LocED:Location-aware Energy Disggregation Framework
标签(空格分隔): smartMeters
翻译来自论文:LocED:Location-aware Energy Disggregation Framework,仅做学术研究用,限于水平,可能有一些错误,敬请量解,谢绝转载!
摘要:
提供用电器级的能量消耗信息或是会导致消费者理解他们消费习惯,鼓励他们优化能源消耗。NILM:Non-intrusive load monitoring(非侵入负载监测)或是从聚合的家庭能源数据解聚合的目的是为了获取用电器能源级的消耗。由于NILM算法的复杂性,NILM算法提出至今,都是需要高性能的硬件或系统来采集用电器级的数据。这种算法的提出与可拓展性相私人消费数据相关。这篇文章中,我们提出了一种Location-aware Energy Disaggregation Framework(LocED)方法,它获取用电器级的用户数据。LocED框架限制用电器是为了基于当前的居住者来做解聚合。因此,LocED中的嵌入式系统能提供用电器级的能量消耗。我们提供了一些准确的度量来学习locED框架的表现,为了测试这个框架的稳定性,我们用其它公开的数据集来测试,当以指数形式减少计算复杂度时,locED有着比较高的能量解聚合准确度。我们同样将我们的数据集合公开,DRED(Dutch Residential Energy DataSet)包括电气特性,居住环境和电气参数。
关键字
NILM,energy disaggregation, localization,public dataset,smart metering
Introduction(总结后的介绍)
世界上的能源消费30-40%来自居住和商业建筑,预计还会大量的增加,用电器级的消费统计将会是更有意义的,这将会导致5-15%的能源消耗,一些家庭的自动系统现在能提供部分能源消耗数据,但这种系统缺少实时的推荐功能,一个自动的个性推荐系统对于节约能源来说是非常有利的。这个推荐系统在电价低的时候推荐给居住者。而且好的信息可以被用来鉴别错误或是异常用用电器,同时提醒居住者,能源都消费在什么用电器上,现在用一些公司开始给他们的消费者提供一些能源级的服务。
通过对每一个用电器部署一个传感器是最简单获取用电器级信息的方式,但这种方式需是有侵入的,需要维护的,花费高的。相对的,最新家庭能源监测技术提出了NILM算法,这种算法的目的就是为了将总线上的数据解聚合成单个的用电器,NILM之所以流行是因为低成本,不需要大量传感器的部署,大规模智能电表的部署使NILM算法更多的用在解聚合中。
NILM算法依然存的比较大的挑战:
1,大多数算法的提出都只是基于用电器的一个子集–一部分用电器的解聚合,这是因为随着用电器数量的增加,计算复杂度成指数的增加。
2,一些用电器有相同的能源消耗,每一个用电器又可能有多种状态,用模型准确的推理出来是不轻松的。
3,NILM经常会夹带第三方的服务,这样对消费者隐私信息有影响。商用的NILM系统要求将智能电表的数据放到云服务器作能源的解聚合。这样就涉及可扩展性和隐私。
4,只有一些NILM系统提供近似实时的能源解聚合,要求更多更详细的用户相关信息和云服务器。
最后,这篇文章提出了locED框架,利用用户的居住信息和聚合的准确用电器级的信息。目的包括三个方面:
1,利用居住者的位置信息,NILM算法能够减少一定数据潜在用电器
2,by reducing the state explosion, the processing power and storage capacity required for disaggre-gation are also reduced, making NILM algorithms tractable and implementable.
3,with the large-scale proliferation of smartphones and wearables, it is now possible to monitor location of the occupants (indoor room-level localization) in a non-intrusive and cost-effective manner.
locED 能源解聚合在房子里面是低成本的嵌入式系统,它部署到本地,避免敏感有用户信息泄露。
这篇文章主要目的是发展一种本地的能源解聚合框架,这种框架能:
1,提供一种实时的用电器级的能源解聚合
2,低复杂度的算法部署到本地的嵌入式系统中
我们公开DRED数据集,并不断的更新。
这篇文章的主要贡献包括:
1,我们提出了一种新的实时的、低复杂度能源解聚合框架(locED)
2,我们提供我们的数据集DRED,包含用电器级和聚合的能源数据,也包含居住者和环境的一些信息。
3,我们从用电器级和单个用户级提出了一些准确度来衡量LocED的效率,并用这个框架去估计一些开源的数据集。
相关工作
一些关于NILM算法的提出和很多因素有关,例如算法是监督的,半监督的,无监督的还有包括一些额外的附加数据。先介绍一些先前的工作。
1.无监督NILM技术:
这种技术不需要先验知识,但是一般需要人为的贴标签,且工作在较低的工作频率下(1HZ)这种技术典型的依耐聚合总线上状态的改变的发现,有一些文章中提出了这种算法,FHMMS这种算法在[5,9,10]中提出,而且一绡机器学习的算法被提出来像ANN和遗传算法【10】。上述方法在计算复杂度上比较集中,从HMM模型的多状态中精确推理是困难的。
2.监督NILM技术:
带签名的数据库用来学习用电器状态,另一些算法部署需要用有功功率和无功功率来做能量分解
3.半监督的NILM技术:
这种技术避免监督的部署传感器来获取用电器的数据签名。同时高的计算复杂度不符合这种嵌入式系统。
附加数据被用在NILM上:
NILM算法也用不同的额外数据来做能源解聚合和增加他的正确率,一些算法仅仅只依赖房间的功率消耗。有一些算法用是有功功率和无功功率做能源分解。有一些算法用较高的采样频率来分析瞬时状态。然而,高的采样速率要求比较昂贵的硬件,通过不同的相位来决定用电器的分布,有的人测量用电器周围的电磁场来判断状态改变来估计能源的消耗。上面说的这些方法来提高NILM的准确率,他们也要求额外的部署和维持传感器。
关于NILM算法的一个大的问题是NILM算法的可扩展性,提出的LocED框架用combinatorial optimization algorithm(CO)来减少计算复杂性提高用电器识别的准确率。我们的框架能被用来任何数据集合包括实际居住者的位置信息,我们的DRED数据集合不需要部署任何额外的传感器来获取居住信息,但需要用WIFI/BT接收智能手机和可穿戴设备上获取位置信息。我们评价这个LocED框架的效率通过我们的数据和一些公开的数据集。我们同时也公开我们的数据集。
3.位置相关的能源解聚合
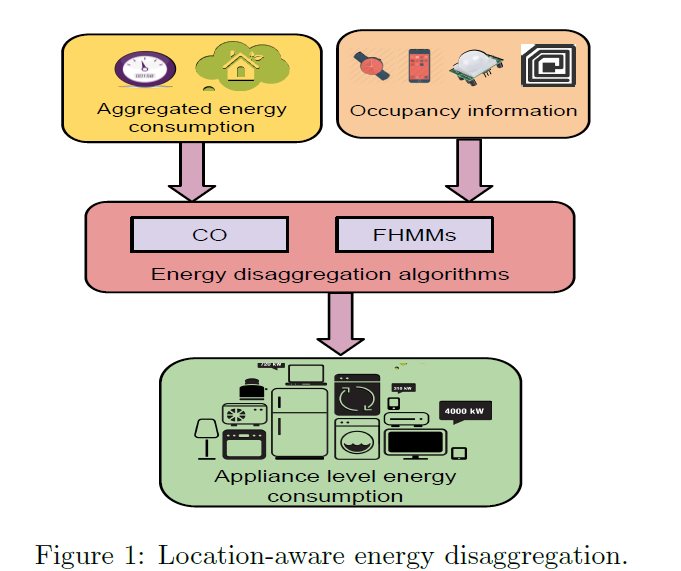
上图是正个位置相关能源解聚合的框图。
3.1 用户入住模型
居住信息一般用在智能家庭中做能耗管理,例如当人不在房间时,这个系统能调节空调的效率和关掉不需要的用电器例如电灯。
我们部署居住信息来改进NILM算法,所用的用电器仅在当前居住环境下作解聚合。还有一些直接或是间接的方法被用来获取居住信息。直接的方法是通过部署便宜的传感器像PIR,读开关,RFID标签来决定用户级的居住信息。即使这些方式是高成本的,难维护的,也是侵入的。
在我们的工作中,我们部署了一种非侵入的方式来获取居住信息用智能手机或是可穿戴设备的帮助。这种方式不需要额外的硬件部署,只依耐存在的信息来定位,通过wifi或是BT来传输位置信息,To save battery and also to derive accurate location, a radio scan is performed only upon detection of a user movement (i.e., change in accelerometer data or step detection).用这中方式获取的算法有很多中像贝叶斯,SVM,K-nearest,决策树等。我们的位置算法基于贝叶斯分类技术包含两步,训练和测试如图2所示
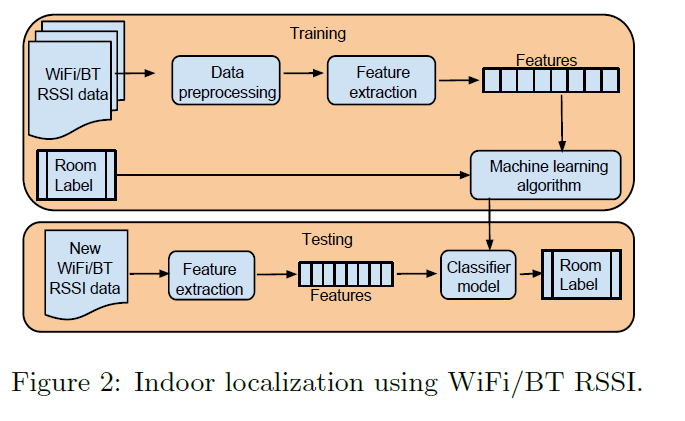
在训练时,数据收集从每一个房间,然后得到一个分类模型,在测试阶段,一个新的数据送入模型来获取房间级的用户信息。
这个LocED框架是用独立的方法来获取位置信息。
3.2 集合能源消费模型
我们提供一种简单的描述,关于能量解聚合的CO算法,然后,我们提出一种适合我们框架的CO算法。
Combinatorial Optimization(CO):能源解聚合的目标通过聚合的能源数据解出每一个用电器。

这种方法要求一个知道每一个用电器在一个状态下能量消耗的具体情况,这被用来预测这个这个用电器的状态,这个计算的复杂性是这样定义的,O(TS^N),N是用电器的种数,S是用电器的状态数,T是相对时间。
CO算法有一些缺点 ,首先,优化问题的子集和是复杂的,而且,CO的复杂性随着用电器总数的增加而增加,第二点,这个算法对于相似的功耗的用电器和状态时不能识别出来。第三点,这个算法假如所有的用电器都在被监视,即使没有使用时,也会给一点的能量消耗。
3.3LocED 框架
LocED框架包括处理程序的技术,这种技术能简单的用NILM计算来提高能量解聚合的准确率,LocED框架用集合的能源数据和居住的位置信息来获取准确的用电器级的相关信息。
我们提出的CO算法克服了传统CO算法的一些缺点,我们修改过的CO算法包含一些当前居住环境下的用电器,减少了解聚合下状态数,,我们部署了一个能源消耗的数据库,这个数据库能提供一一段时间内能量消耗的最大值和相应用模型数,这个信息可以被用来做为用电器的先验知识,我们改进的CO算法要求知道知道用电器的数量和他们在房间的位置,这些开始数据在部署时一次收集,除了一些用电器像真空吸尘器,吹风机等。

数据处理和缩减取样:为了获取不能的数据集,我们的框架能用不同的采样速率来采样,一般来说,当传感器失灵、网络连接错误时可能得到一些错误的数据结果,因此,我们通过移除一些数据或是用一统计的方法来平滑,插入等方法,不同的数据集有不同的采样率,从1秒到15分钟不等,LocED applies a downsampling mechanism similar to NILMTK, to lter transients that occur due to high starting current of an appliance.
优先组合:在传统的CO算法中,在每一个时间段就找这个用电器属于那一类,这和当前的能源聚合相似,但是在同一个时间可能不只存在一个用电器,例如,在时间t内,CO算法可以能决定是TV+microware 在t+1时他可能会选择fan+microware,这是因为电风扇有电视可能有相似的功耗,这个结果就会导致错误,因此,保留用电器状态的一至性是必要的,LocED定义了一个优先组合 ,就是当前用电器的运行状态,这个信息从NILM的迭代中回复,在每一人时间段,LocED框架会先估计先前状态的优先组合,检查和当前的聚合状态是否合适,如果不超过当前所设定的阈值,那么就预测是先前的状态,然后开始估计下一状态

Occupancy based appliance selection:
当现在的优化组合策略不匹配集合能量消耗,LocED框架就估计上一个用电器。这种鉴别的方式和当前用户的位置有关,如果这个用户包含厨房和卧室,只有在当前的位置存在有用电器才被认为是合法的解聚合。一般来说,这个用电器被估计包含以下步骤:
1.用电器当前在有居住环境下
2.用电器是在工作状态
3.appliance that are always on,these are autonomous appliance such as refrigerator
4.用电器能被远程控制,像电灯或是其它智能设备
我们叫这种用电器叫“被考虑的用电器”
LocED用这种用电器做能源解聚合,而不是房间里的所有有电器。
CO based NILM算法:

Validation:
我们现在在之前的状态上验证用电器集合,用基于居住的用电器选择,LocED保证在没有人时候用电器不会开。然而,验证状态会保证用电器在已经开了之后就不会关闭,像过程控制用电器,这依赖于用电器的类型。
在这项工作中,我们广泛的将用电器分类:
1.用户依赖用电器,一个用电器需要用户接口去关闭,例如,TV,Fan等;
2.用户不依赖用电器,这种电器能自动的关闭,不需要用户接口,像微波炉,洗衣机,洗碗机等,
当居住的位置不同于用电器的位置时,如果这个选择的用电器在之前的状态包含一个或多个用户依赖的用电器将被关闭,验证状态消除不同用电器之间的优化组合,LocED框架会选择第二种接近的优化组合从之前的状态来进行优化组合。
4.The DRED dataset
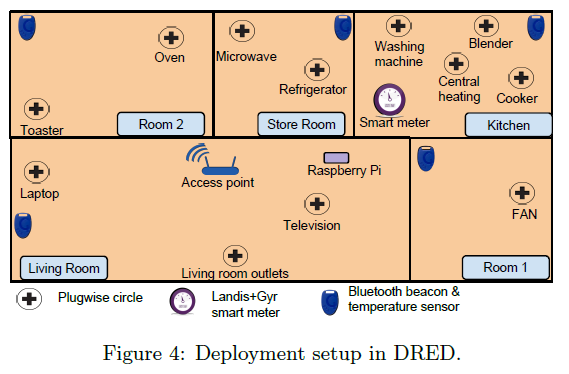
在这一部分,我们将描述我们实际部署传感器数据在荷兰的一个房间,这个数据集包括用电器级和主要消费级的能量消耗数据,我们现在释放大概两个月的数据在这个研究社区,我们将这个数据集叫DRED(Dutch Residential Energy Dataset)图4显示我们实际在房间部署的布局。
4.1 传感器和数据收集
我们实际部署的传感器包括:电相关,居住相关,环境参数。收集这种客观数据来测试能源的解集合算法,像smart* 和iAWE,我们决定测试所有可能的参数,为了不打扰受测试者,这些传感器都是小心的安装。
电气监测:用off-the-shelf传感器来监测能源消耗,采样频率1Hz
1.Mains level:安装一块landis+Gyr E350的智能电表,用来采集房间的能源消耗信息,电表数据的获取采用Plugwise Smile
2.用电器级,用off-the-shelf来采集用电器的能源消耗数据,12个smart plugs被用来监测这个房间的用电器。
(1):电冰箱 (2):洗衣机 (3):中央供暖系统 (4):微波炉 (5):烤箱 (6):炊具 (7):搅拌机 (8):烤箱 (9):TV (10):风扇(11):Living room outlets (12)台灯
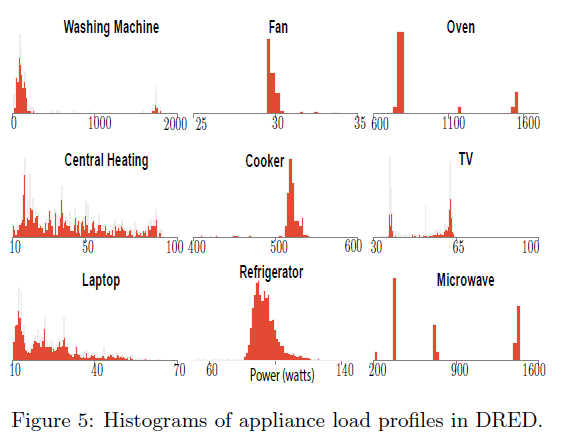
插座的通信通过zigbee协议来组网,用开源的库来获取插座数据,采样速率1HZ。A Raspberry Pi被部署在在本地用来获取和存储数据,数据同时被发送到远程服务器,图5显示了我们用电器消耗的直方图数据集合,可以看出有的用电器有多个状态,有和用电器只有两个状态。
环境监测:
除了收集电能相关的数据外,我们还采集房间内外的温度,风速,湿度。在测温度时用到用低功耗蓝牙,这个电池能用4-5个月,用智能手机和可穿戴来获取蓝牙数据,采样频率1分钟,风速,降水,湿度数据从KNMI网站上采集,1小时一次。
居住监测:
在我们的部署环境中我们每隔1分中扫描wifi接入点和蓝牙信号,这个数据进一步用其它机器学习的算法来确定居住者的位置,用wifi定位没有额外的传感器部署,蓝牙定位是通过我们的蓝牙部署设备来定位。
家庭电表数据:数据还包括一些用户的电表数据,房间格局,用电器的位置映射,这些电表数据用于NILM算法,关于电表更进一步的细节可以在第17篇引用中找到。
4.2 数据集特征和存在数据集的对比
用不同国家数据集合来对比和评价这个数据集合的算法是重要的,同一类用电器在不同的国家会有不同。这个数据集第一个公开测试NILM算法,还有相应很多数据集,像BLUED,SMART ,AMP, IAWE, ECO,UK-DALE Pecan street .
1.在我们的DRED中,总是有一些用电器存在额外的消耗,这种额外消耗是存在的或是我们没提到的,非常受欢迎的数据集REDD,smart*,iawe ,ECO都这种问题,这个额外的消耗对NILM 算法有一定的阻碍 。
2.REDD数据集有5%的误码率,这个误码率是通信问题或是传感器故障,,大多数的误码率像samart*达到10-20%
3.我们的部署还在继续,数据集合包含仅两个月的数据,而且每个月我们都会更新,现在只有ECO and UK-Dale的数据集超过100天
4.即使是ECO ,Smart*,iAWE数据集包含居住信息,他们有很在的漏洞或是错误数据,然而,DRED 用间接的传感器方式或取房间级的居住信息,有较高的可信率。
我们相信上述DRED数据集在NILM算法和分析能量数据方面相比其它数据集合会更有用、更可靠。而且,我们提供HDF5版本的DRED数据集做NILMTK的直接使用。
5.评价
5.1 数据集
我们估计这个评价结果通过多种数据集合,我们的框架除了用DRED外,还有REDD,Smart*,iAWE。因此,因此我们用不同国家的不同数据集合来评价这个表现。
数据统计: 不同的数据集在一定的时间内收集不同的用电器数据。为了评价locED框架在不同的数据集合的表现,理解每一个数据集的统计表现是必要的。图6显示了数据的统计信息。
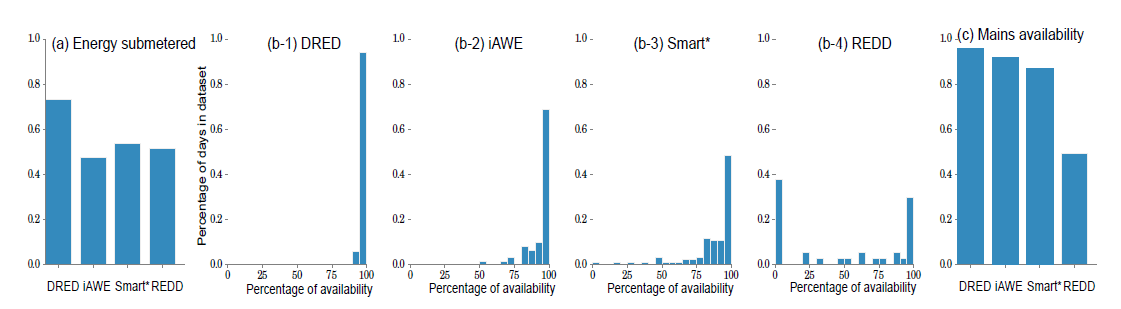
NILMTK已经提供了一些基本的功能,像总线数据,子电表的能量百分比,top-k用电器分析数据集,然而,我们进一步扩展LocED的功能。
图6shows the percentage of total energy measured at the appliance level for all days in the dataset。大多数的数据集合只监测了部分用电器,Furthermore, the variation of this unaccounted energy data signi cantly reduces the accuracy of disaggregation algorithms.DRED has around 75% of energy sub metered and all other datasets have around 45% of energy measured at the appliance level.iAWE数据集合在用电器级有很低的能量采集率。
另一个重要统计数据需要被考虑的是聚合数据在数据集合中的百分比,就是数据记录在一天可收集数据总数中的记录。图6显示的直方图是平均聚合数据在整个数据的比率。y是一天数据的百分比,x是数据的可用性。REDD有90%的聚合数据可用率 图6(b-1).其它数据集有比较低的数据可信率,这获许是通信问题或是传感器的部署问题。
和前面的统计一样,图6(C)显示了总线上数据占总数据集的百分比,DRED数据在所在监测的用电器中有大概95%的数据可信率。其它的数据集合只有90%,86%,50%的可用数据集合。REDD只有50%的集合可用率可能是因为采样间隔过长。
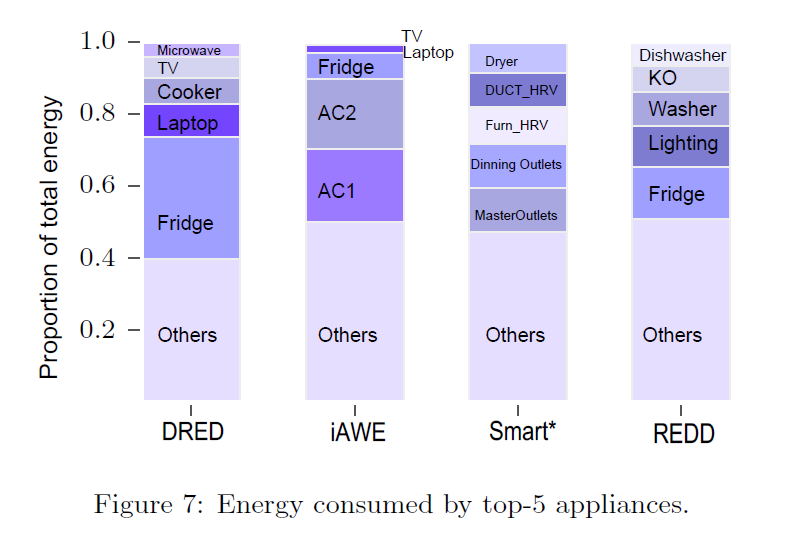
最后,LocED依赖居住的信息,发现居住信息的可信率是很重要的,DRED ,iAWE ,Smart* 分别是81%,76% 36%,我们进一步决定这段时间内的相一致的用电器,例如,如果一个用电器在当前还包括居住的一些信息,这个居住信息就被认为是相关的,ERED iAWE有68%,53%的居住信息,Smart*只有10%的相关信息。
5,2 准确率的度量
一些方式来从房间级和用电器级来评价LocED框架,不同的度量方式如下面所示:
1.正确的总能量分配:fraction of total energy assigned correctly(FTE):
总能量的正确分配是NILM算法常见的检测标准之一,表述实际与估计的一致
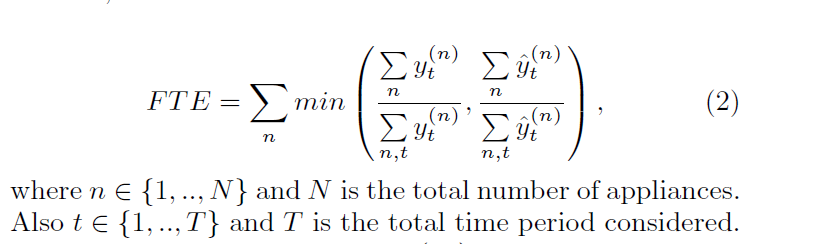
2解聚合中出现的总的错误率:T(e)
所有用电器的解聚合 错误不同于总的能源消耗的解聚合,通过总能量规范化,他被这样给出
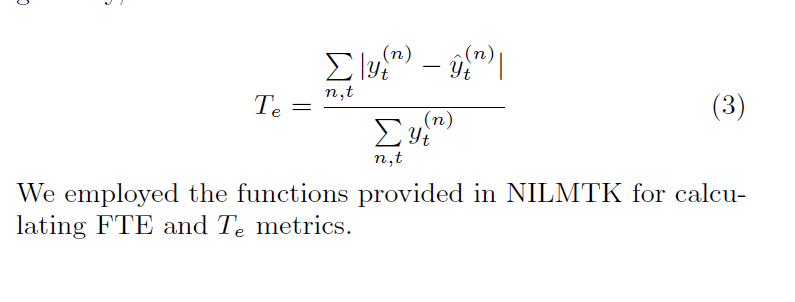
3.Number of appliances identified correctly(Ja):

4.Js

5
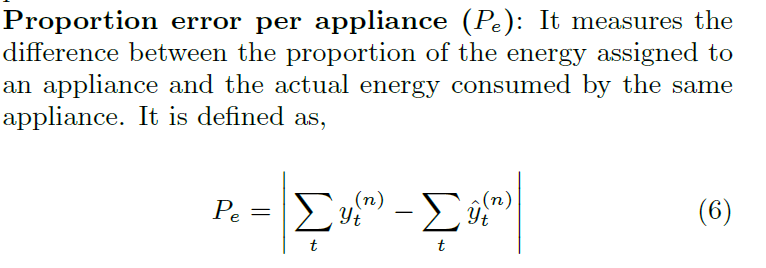
6

6.结果
我们比较LocED解聚合的结果通过不同的数据集,REDD数据集合来自MIT,不包括用户的居住信息,结尾,我们部属一个模型来推测REDD数据中的有用户信息。
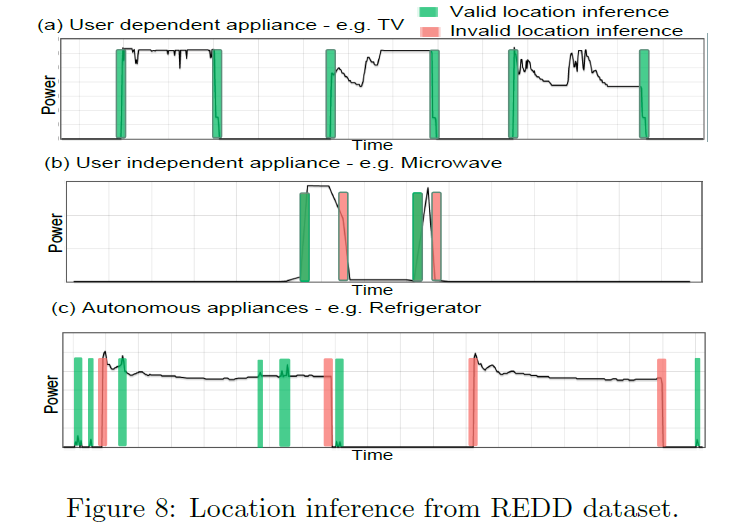
REDD数据集合的位置推理:为了更全面的比较数据,我们根据用电器级的的数据来推测用户的信息,LocED在不同的用电器依赖和用电器不依赖来准确的推测用电器的位置信息,图8显示了有电器的能量 消耗来推测用户的位置信息。

现在我们来看LocED的框架和原始CO算法的表现,为了公平的比较,LocEDT CO算法都用3.3部分所述的的数据和用电器模型,虽然这个模型给出了相关的位置数据模型,但要做一个通用的模型是复杂的。LocED uses a crowd-sourced appliance model from the power consumption database based on the manufacturer and model number of an appliance.在我们的估计中,我们直接用PIR传感器来获取数据,和Smart* ,iAWE数据集合一样,也用到间接获取的数据集像DRED。最后我们用一个参数来决定用电器的优化组合,这个参数决定了用电器的类型,从我们的实验中,发现小功率用电器有小的噪声,在能量消耗过程中有小的变化,大功率用电器有相反的变化规律,最后这个参数可以被用来计量未被监测的用电器通过历史能量消耗。
图9显示了LocED和CO的解聚合的表现,
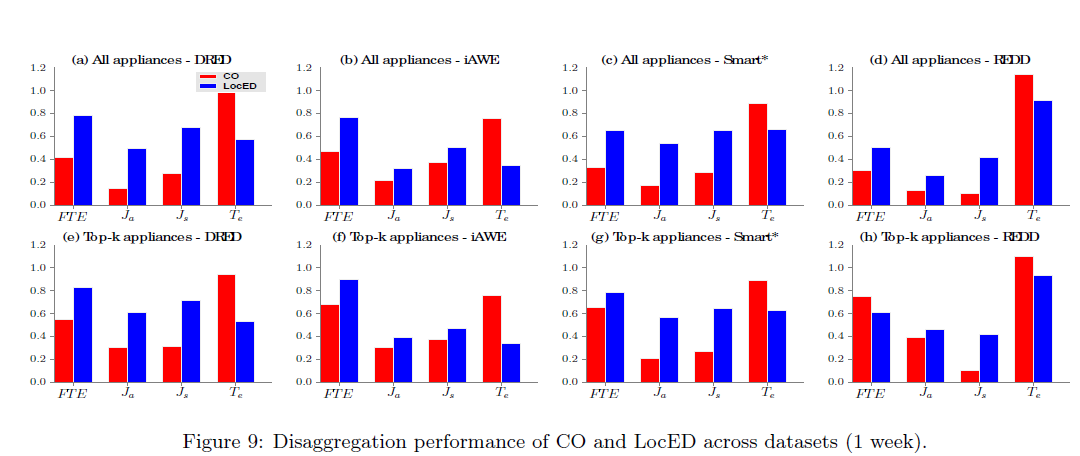
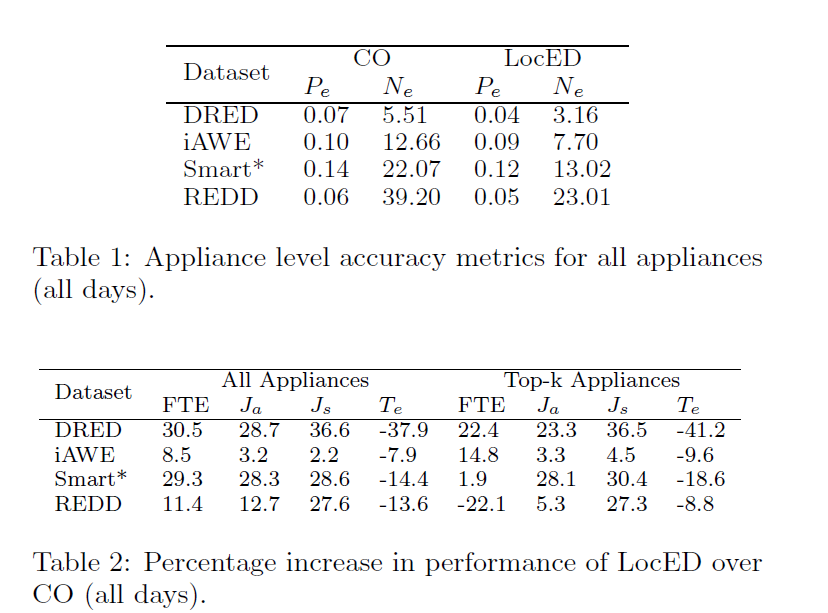
我们考虑所有4个集合一周的数据,一般来说FTE,Ja,Js从0到1变化,Te是非负值,LocED的表现比其它都好,LocED比CO好的主要原因有下面两点,
1.LocED确保这个预测在一段时间内不会连续变化,这都要感谢priority combination
2.LocED 确保相同功率的用电器在不同的在不同的位置不会被选中

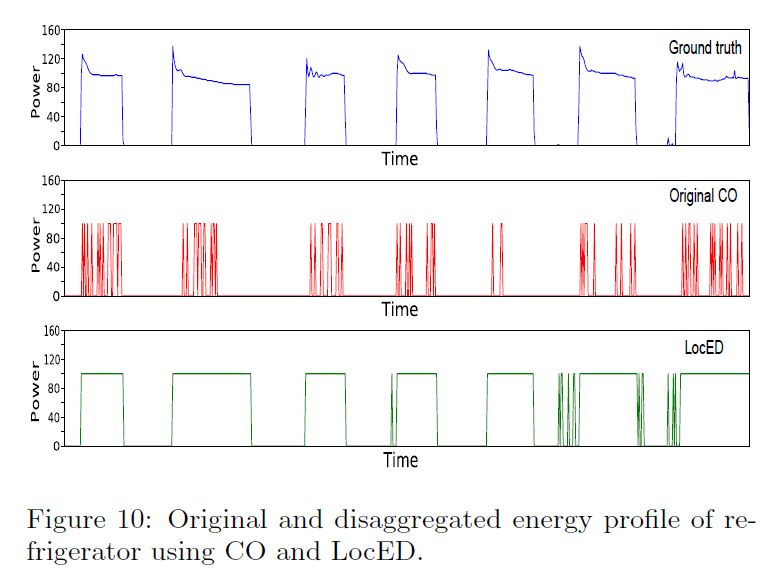

最后

完















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









