






kinetics400数据集获取
博客链接: kinetics400
非常感谢这位大神的数据集
数据集下载解压之后的格式如下:

mmaction2
kinetics数据集格式整理
需要的格式:

rawframes_train和rawframes_val生成
rawframes_train是根据train目录下面的.mp4视频提取的图片帧。
方法一
提取代码可以参考mmaction2官方kinetics数据准备的方法。
我没有安装densorflow,所以使用
bash extract_rgb_frames_opencv.sh ${DATASET}
由于我的数据集是在服务器库中,并不在项目中所以我单独将这部分代码拿出来。
python build_rawframes.py ../data/train/ ../data/rawframes_train/ --level 2 --ext mp4 --task rgb --new-short 256 --use-opencv
val修改一下路径就可以。具体参数可以看官方解释
方法二
在tiny-kinetics400中有很好的处理方法,因此借用一下,具体使用大家去看他主页,非常感谢这位大哥无私奉献。但是提取代码中需要将
frame_%05d.jpg
改成
img_%05d.jpg
不改的话后面训练会出现找不到img_%05d.jpg的问题。
提取完后的目录格式:

train.txt和val.txt生成
具体可以参考这篇博客
生成的txt格式如下:
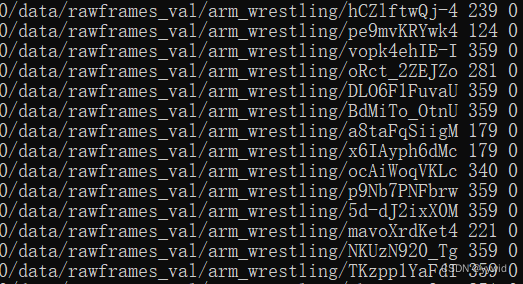
前面是路径,中间是帧数(图片个数),最后是label
感谢博客大哥的代码。
timesformer模型训练
具体训练可以参考mmaction2官方timesformer介绍
由于我是使用多GPU进行训练,所以参考官方训练文档
使用多个gpu进行训练:
tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
其中${CONFIG_FILE}根据自己需要修改configs下面文件,我是使用timesformer进行训练,故修改的文件路径
/mmaction2-master/configs/recognition/timesformer/timesformer_divST_8x32x1_15e_kinetics400_rgb.py
_base_ = ['../../_base_/default_runtime.py']
# model settings
model = dict(
type='Recognizer3D',
backbone=dict(
type='TimeSformer',
pretrained= # noqa: E251
'https://download.openmmlab.com/mmaction/recognition/timesformer/vit_base_patch16_224.pth', # noqa: E501
num_frames=8,
img_size=224,
patch_size=16,
embed_dims=768,
in_channels=3,
dropout_ratio=0.,
transformer_layers=None,
attention_type='divided_space_time',
norm_cfg=dict(type='LN', eps=1e-6)),
cls_head=dict(type='TimeSformerHead', num_classes=13, in_channels=768),
# model training and testing settings
train_cfg=None,
test_cfg=dict(average_clips='prob'))
# dataset settings
dataset_type = 'RawframeDataset'
data_root = '../data/rawframes_train'
data_root_val = '../data/rawframes_val'
ann_file_train = '../data/train.txt'
ann_file_val = '../data/val.txt'
ann_file_test = '../data/val.txt'
img_norm_cfg = dict(
mean=[127.5, 127.5, 127.5], std=[127.5, 127.5, 127.5], to_bgr=False)
train_pipeline = [
dict(type='SampleFrames', clip_len=8, frame_interval=32, num_clips=1),
dict(type='RawFrameDecode'),
dict(type='RandomRescale', scale_range=(256, 320)),
dict(type='RandomCrop', size=224),
dict(type='Flip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCTHW'),
dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),
dict(type='ToTensor', keys=['imgs', 'label'])
]
val_pipeline = [
dict(
type='SampleFrames',
clip_len=8,
frame_interval=32,
num_clips=1,
test_mode=True),
dict(type='RawFrameDecode'),
dict(type='Resize', scale=(-1, 256)),
dict(type='CenterCrop', crop_size=224),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCTHW'),
dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),
dict(type='ToTensor', keys=['imgs', 'label'])
]
test_pipeline = [
dict(
type='SampleFrames',
clip_len=8,
frame_interval=32,
num_clips=1,
test_mode=True),
dict(type='RawFrameDecode'),
dict(type='Resize', scale=(-1, 224)),
dict(type='ThreeCrop', crop_size=224),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCTHW'),
dict(type='Collect', keys=['imgs', 'label'], meta_keys=[]),
dict(type='ToTensor', keys=['imgs', 'label'])
]
data = dict(
videos_per_gpu=2,
workers_per_gpu=0,
test_dataloader=dict(videos_per_gpu=1),
train=dict(
type=dataset_type,
ann_file=ann_file_train,
data_prefix=data_root,
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=ann_file_val,
data_prefix=data_root_val,
pipeline=val_pipeline),
test=dict(
type=dataset_type,
ann_file=ann_file_test,
data_prefix=data_root_val,
pipeline=test_pipeline))
evaluation = dict(
interval=1, metrics=['top_k_accuracy', 'mean_class_accuracy'])
# optimizer
optimizer = dict(
type='SGD',
lr=0.005,
momentum=0.9,
paramwise_cfg=dict(
custom_keys={
'.backbone.cls_token': dict(decay_mult=0.0),
'.backbone.pos_embed': dict(decay_mult=0.0),
'.backbone.time_embed': dict(decay_mult=0.0)
}),
weight_decay=1e-4,
nesterov=True) # this lr is used for 8 gpus
optimizer_config = dict(grad_clip=dict(max_norm=40, norm_type=2))
# learning policy
lr_config = dict(policy='step', step=[5, 10])
total_epochs = 100
# runtime settings
checkpoint_config = dict(interval=1)
work_dir = './work_dirs/timesformer_divST_8x32x1_15e_kinetics400_rgb'
具体要改的:

以上只能得到每个epoch的权重信息,如果需要得到best.pth权重,修改evaluation如下:
evaluation = dict(
interval=1, save_best_ckpt=True, metrics=['top_k_accuracy', 'mean_class_accuracy'], best_ckpt_name='best.pth')
训练例子:
tools/dist_train.sh configs/recognition/timesformer/timesformer_divST_8x32x1_15e_kinetics400_rgb.py 8 --validate
我使用的是100个epochs,训练后的权重文件比较大,可以运行中删除部分,保存最好的模型,具体可以修改配置文件。
由于跑demo部分比较简单我就不说了,希望对各位有用,有错误等希望大家指出来。















 940
940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









