







导航
安装教程导航
Mamba 及 Vim 安装问题参看本人博客:Mamba 环境安装踩坑问题汇总及解决方法(初版)- Linux 下 Mamba 安装问题参看本人博客:Mamba 环境安装踩坑问题汇总及解决方法(重置版)
- Windows 下 Mamba 的安装参看本人博客:Window 下Mamba 环境安装踩坑问题汇总及解决方法 (无需绕过selective_scan_cuda)
- Linux 下 Vim 安装问题参看本人博客:Linux 下 Vim 环境安装踩坑问题汇总及解决方法(重置版)
- Windows 下 Vim 安装问题参看本人博客:Window 下 Vim 环境安装踩坑问题汇总及解决方法
- Linux 下Vmamba 安装教程参看本人博客:Vmamba 安装教程(无需更改base环境中的cuda版本)
- Windows 下 VMamba的安装参看本人博客:Windows 下 VMamba 安装教程(无需更改base环境中的cuda版本且可加速)
- Windows下 Mamba2及高版本 causal_conv1d 安装参考本人博客:Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)
- Windows 下 Mamba / Vim / Vmamba 环境安装终极版参考本人博客:Windows 下Mamba2 / Vim / Vmamba 环境安装问题记录及解决方法终极版(无需绕过triton)
- (GPU算力12.0版本)Windows 下 Mamba / Vim / Vmamba 环境配置教程 参考本人博客:Windows 下 Mamba / Vim / Vmamba 环境配置安装教程(适用于5070,5080,5070Ti等GTX 50系显卡)
安装教程及安装包索引
不知道如何入手请先阅读新手索引:Linux / Windows 下 Mamba / Vim / Vmamba 安装教程及安装包索引
本系列教程已接入ima知识库,欢迎在ima小程序里进行提问!(如问题无法解决,安装问题 / 资源售后 / 论文合作想法请+文末或个人简介vx)
背景
Vim 官方代码链接为:https://github.com/hustvl/Vim,在原来博客 “Mamba 环境安装踩坑问题汇总及解决方法” 基础上,不绕过selective_scan_cuda进行 Vim 环境安装,这样可以获得和 Linux 一样的速度。注意,Vim (Vision Mamba)和 Vmamba (VMamba: Visual State Space Model)虽然都是基于mamba,但是它们不是同一篇!
Windows 下环境准备
- 前期环境准备,同原来博客 “Mamba 环境安装踩坑问题汇总及解决方法” ,具体为:
conda create -n mamba python=3.10
conda activate mamba
conda install cudatoolkit==11.8
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
pip install setuptools==68.2.2
conda install nvidia/label/cuda-11.8.0::cuda-nvcc_win-64
conda install packaging
pip install triton-2.0.0-cp310-cp310-win_amd64.whl
其中 triton-2.0.0-cp310-cp310-win_amd64.whl 获取:网盘、triton 2.1.0 版本的下载链接 以及 triton 的 Windows 包 。
上述安装包里面 triton 核心的 triton.jit 和 torch.compile 等功能均无法像Linux下正常运行,上述安装包只是从形式上完成编译,所以你选什么版本都行,只要能形式上装上。
Windows 下完全使用triton的终极版参考本人博客:Windows 下Mamba2 / Vim / Vmamba 环境安装问题记录及解决方法终极版(无需绕过triton)
然后下载 Vim 的官方代码:
git clone https://github.com/hustvl/Vim.git
causal-conv1d的安装,Vim 官方代码仓里给了其源码,因此只需要利用其源码安装即可,类似 “Window 下Mamba 环境安装踩坑问题汇总及解决方法 (无需绕过selective_scan_cuda)”
cd causal-conv1d
set CAUSAL_CONV1D_FORCE_BUILD=TRUE
pip install .
官方没有编译好的适用于Windows版本的 whl,因此需要用上述步骤来手动编译。
笔者编译好了 Windows 下的causal_conv1d-1.0.0-cp310-cp310-win_amd64.whl ,亦可直接下载安装(只适用于torch 2.1,CUDA 11.8) 。
pip install causal_conv1d-1.0.0-cp310-cp310-win_amd64.whl
- Vim 官方代码仓给的
causal-conv1d源码有误,过于老旧且不兼容,causal-conv1d版本应≥1.1.0,类似 “Window 下Mamba 环境安装踩坑问题汇总及解决方法 (无需绕过selective_scan_cuda)”
git clone https://github.com/Dao-AILab/causal-conv1d.git
cd causal-conv1d
git checkout v1.1.1 # 安装最新版的话,此步可省略
set CAUSAL_CONV1D_FORCE_BUILD=TRUE
pip install .
官方没有编译好的适用于Windows版本的 whl,因此需要用上述步骤来手动编译。笔者编译好了 Windows 下的 causal_conv1d-1.1.1-cp310-cp310-win_amd64.whl,亦可直接下载安装(只适用于torch 2.1,不要急着下,后面还有合集)。
pip install causal_conv1d-1.1.1-cp310-cp310-win_amd64.whl
完成前期工作后进入下一步正式编译。注意安装成功后会在相应环境(xxx\conda\envs\xxx\Lib\site-packages\)中生成 causal_conv1d_cuda.cp310-win_amd64.pyd 文件,此文件对应 causal_conv1d_cuda 包。
Windows 下适合于Vim的 mamba-ssm 的编译
Vim 官方对 mamba-ssm 的源码进行了修改,所以其与原版有不同。
既可以在安装完原版的基础上再修改相应环境(xxx\conda\envs\xxx\Lib\site-packages\)中的源码文件,参考“Window 下Mamba 环境安装踩坑问题汇总及解决方法 (无需绕过selective_scan_cuda)”。
也可以直接强行利用Vim的源码进行编译。方法如下:
cd mamba-1p1p1 # 先切换到Vim 下面的这个目录
- 在mamba-1p1p1下的
setup.py修改第41行配置:
FORCE_BUILD = os.getenv("MAMBA_FORCE_BUILD", "TRUE") == "TRUE"
修改第261行配置为(可选,相当于在 BuildExtension 后多加了一个.with_options(use_ninja=False)):
cmdclass={"bdist_wheel": CachedWheelsCommand, "build_ext": BuildExtension.with_options(use_ninja=False)}
- 将
csrc/selective_scan/selective_scan_fwd_kernel.cuh的void selective_scan_fwd_launch函数改为
void selective_scan_fwd_launch(SSMParamsBase ¶ms, cudaStream_t stream) {
// Only kNRows == 1 is tested for now, which ofc doesn't differ from previously when we had each block
// processing 1 row.
static constexpr int kNRows = 1;
BOOL_SWITCH(params.seqlen % (kNThreads * kNItems) == 0, kIsEvenLen, [&] {
BOOL_SWITCH(params.is_variable_B, kIsVariableB, [&] {
BOOL_SWITCH(params.is_variable_C, kIsVariableC, [&] {
BOOL_SWITCH(params.z_ptr != nullptr , kHasZ, [&] {
using Ktraits = Selective_Scan_fwd_kernel_traits<kNThreads, kNItems, kNRows, kIsEvenLen, kIsVariableB, kIsVariableC, kHasZ, input_t, weight_t>;
// constexpr int kSmemSize = Ktraits::kSmemSize;
static constexpr int kSmemSize = Ktraits::kSmemSize + kNRows * MAX_DSTATE * sizeof(typename Ktraits::scan_t);
// printf("smem_size = %d\n", kSmemSize);
dim3 grid(params.batch, params.dim / kNRows);
auto kernel = &selective_scan_fwd_kernel<Ktraits>;
if (kSmemSize >= 48 * 1024) {
C10_CUDA_CHECK(cudaFuncSetAttribute(
kernel, cudaFuncAttributeMaxDynamicSharedMemorySize, kSmemSize));
}
kernel<<<grid, Ktraits::kNThreads, kSmemSize, stream>>>(params);
C10_CUDA_KERNEL_LAUNCH_CHECK();
});
});
});
});
}
- 将
csrc/selective_scan/static_switch.h的BOOL_SWITCH函数改为
#define BOOL_SWITCH(COND, CONST_NAME, ...) \
[&] { \
if (COND) { \
static constexpr bool CONST_NAME = true; \
return __VA_ARGS__(); \
} else { \
static constexpr bool CONST_NAME = false; \
return __VA_ARGS__(); \
} \
}()
(这两步是将 constexpr 改为 static constexpr)
- 在
csrc/selective_scan/selective_scan_bwd_kernel.cuh和csrc/selective_scan/selective_scan_fwd_kernel.cuh文件开头加入:
#ifndef M_LOG2E
#define M_LOG2E 1.4426950408889634074
#endif
- 完成上述修改后,执行
pip install .一般即可顺利编译,成功安装。 - 本人编译好的Windows 下的适用于Vim的whl 也有:mamba-ssm-1.1.1 (只适用于torch 2.1,CUDA 11.8),合集全家桶,可直接下载安装。利用 whl 安装命令为:
pip install mamba_ssm-1.1.1-cp310-cp310-win_amd64.whl --no-dependencies causal_conv1d
由于此时没有绕过selective_scan_cuda,在虚拟环境中(xxx\conda\envs\xxx\Lib\site-packages\)产生了 selective-scan-cuda.cp310-win-amd64.pyd 文件,所以运行速度较快。
出现的问题
1. 出现 KeyError: 'HOME'
具体来说出现以下报错
Traceback (most recent call last):
.....
File "xxx\models\vimamba.py", line 115, in forward
hidden_states, residual = fused_add_norm_fn(
File "D:\Anaconda\envs\xxx\lib\site-packages\mamba_ssm\ops\triton\layernorm.py", line 478, in rms_norm_fn
return LayerNormFn.apply(x, weight, bias, residual, eps, prenorm, residual_in_fp32, True)
File "D:\Anaconda\envs\xxx\lib\site-packages\torch\autograd\function.py", line 539, in apply
return super().apply(*args, **kwargs) # type: ignore[misc]
File "D:\Anaconda\envs\xxx\lib\site-packages\mamba_ssm\ops\triton\layernorm.py", line 411, in forward
y, mean, rstd, residual_out = _layer_norm_fwd(
File "D:\Anaconda\envs\xxx\lib\site-packages\mamba_ssm\ops\triton\layernorm.py", line 155, in _layer_norm_fwd
_layer_norm_fwd_1pass_kernel[(M,)](
File "D:\Anaconda\envs\xxx\lib\site-packages\triton\runtime\jit.py", line 106, in launcher
return self.run(*args, grid=grid, **kwargs)
File "D:\Anaconda\envs\xxx\lib\site-packages\triton\runtime\autotuner.py", line 73, in run
timings = {config: self._bench(*args, config=config, **kwargs)
File "D:\Anaconda\envs\xxx\lib\site-packages\triton\runtime\autotuner.py", line 73, in <dictcomp>
timings = {config: self._bench(*args, config=config, **kwargs)
File "D:\Anaconda\envs\xxx\lib\site-packages\triton\runtime\autotuner.py", line 63, in _bench
return do_bench(kernel_call)
File "D:\Anaconda\envs\xxx\lib\site-packages\triton\testing.py", line 136, in do_bench
fn()
File "D:\Anaconda\envs\xxx\lib\site-packages\triton\runtime\autotuner.py", line 62, in kernel_call
self.fn.run(*args, num_warps=config.num_warps, num_stages=config.num_stages, **current)
File "<string>", line 41, in _layer_norm_fwd_1pass_kernel
File "D:\Anaconda\envs\xxx\lib\site-packages\triton\compiler.py", line 1230, in compile
so_cache_manager = CacheManager(so_cache_key)
File "D:\Anaconda\envs\xxx\lib\site-packages\triton\compiler.py", line 1102, in __init__
self.cache_dir = os.environ.get('TRITON_CACHE_DIR', default_cache_dir())
File "D:\Anaconda\envs\xxx\lib\site-packages\triton\compiler.py", line 1093, in default_cache_dir
return os.path.join(os.environ["HOME"], ".triton", "cache")
File "D:\Anaconda\envs\xxx\lib\os.py", line 680, in __getitem__
raise KeyError(key) from None
KeyError: 'HOME'
在Win下还需要修改 mamba 安装路径下 D:\Anaconda\envs\xxx\lib\site-packages\mamba_ssm\ops\triton\layernorm.py 文件,具体来说,是把原来 layernorm.py 里面的
def layer_norm_fn(
x,
weight,
bias,
residual=None,
eps=1e-6,
prenorm=False,
residual_in_fp32=False,
is_rms_norm=False,
):
return LayerNormFn.apply(x, weight, bias, residual, eps, prenorm, residual_in_fp32, is_rms_norm)
def rms_norm_fn(x, weight, bias, residual=None, prenorm=False, residual_in_fp32=False, eps=1e-6):
return LayerNormFn.apply(x, weight, bias, residual, eps, prenorm, residual_in_fp32, True)
改为
def layer_norm_fn(
x,
weight,
bias,
residual=None,
eps=1e-6,
prenorm=False,
residual_in_fp32=False,
is_rms_norm=False,
):
return layer_norm_ref(x, weight, bias, residual, eps, prenorm, residual_in_fp32)
def rms_norm_fn(x, weight, bias, residual=None, prenorm=False, residual_in_fp32=False, eps=1e-6):
return rms_norm_ref(x, weight, bias, residual, eps, prenorm, residual_in_fp32)
2. 出现 TypeError: causal_conv1d_fwd()
具体来说,出现以下报错:
conv1d_out = causal_conv1d_cuda.causal_conv1d_fwd(
TypeError: causal_conv1d_fwd(): incompatible function arguments. The following argument types are supported:
这种情况是 causal_conv1d 和 mamba_ssm 的版本兼容问题。
实测发现 Vim 官方给的 causal_conv1d 源码过于老旧,应该按照≥1.1.0的版本。
3. 出现 unexpected keyword argument 'if_devide_out'
运行 Vim 官方代码发现出现错误:
Mamba.__init__() got an unexpected keyword argument 'if_devide_out'
即
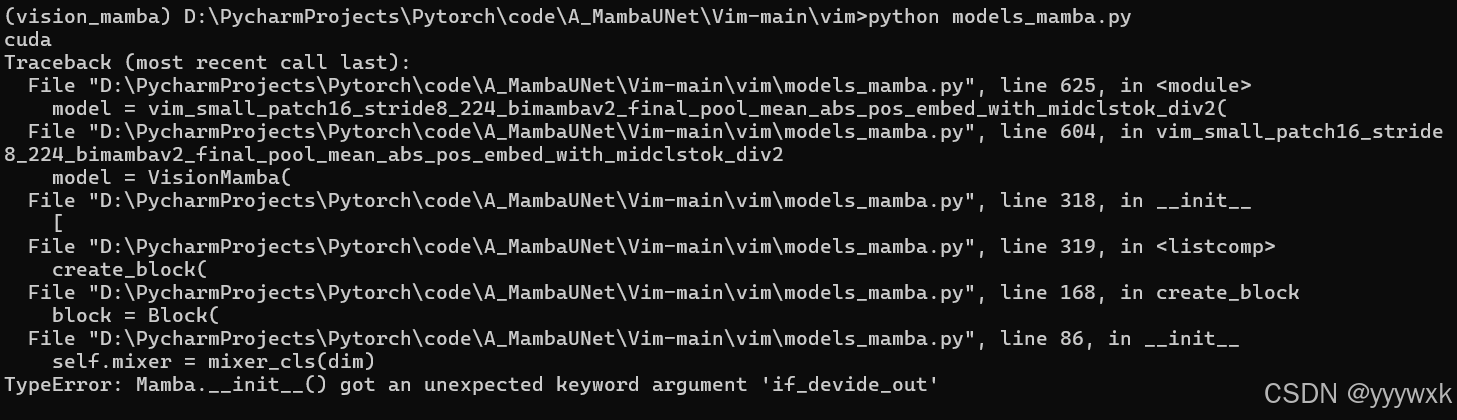
出现这个错误是因为官方代码的一个笔误,在 Vim/vim/models_mamba.py 第 608 行 vim_base_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_middle_cls_token_div2,误将 if_divide_out 拼错为 if_devide_out,Mamba 里没有这个属性,所以将文件中的 if_devide_out 替换为 if_divide_out 即可。在旧的 Vim 代码中没有这个笔误。
4. TypeError: the first argument must be callable
运行 Vim 官方代码发现出现错误 TypeError: the first argument must be callable:
File "D:\YoLo\Vim-main\vim\models_mamba.py",line 165,in create_block
norm_cls = partial(
TypeError: the first argument must be callable
原因在于 Vim/vim/models_mamba.py 的开头

注意一下 mamba_ssm.ops.triton 文件夹下面 是 layernorm.py 还是 layer_norm.py,mamba_ssm 里面是叫layer_norm.py,Vim 旧版本也是,最新版本改了名字。
5. RuntimeError: failed to find C compiler
如果出现:
RuntimeError: failed to find C compiler, Please specify via cc environment variable.
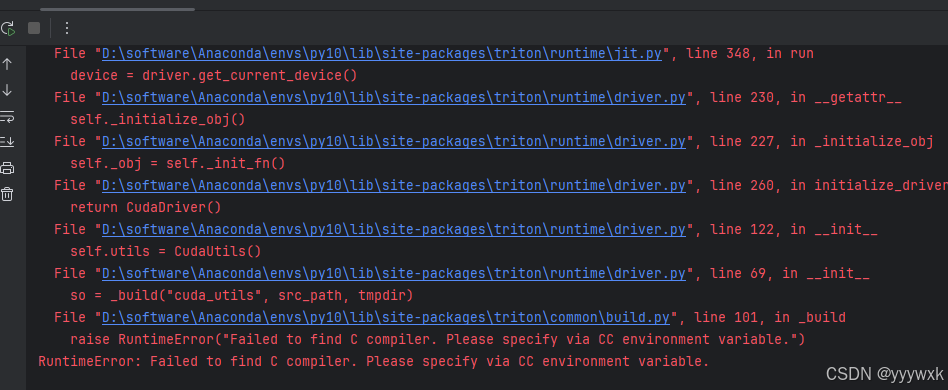
则还是因为调用了 triton 库,应该同 前述出现 KeyError: 'HOME' 一样,去环境中修改 layernorm.py 里面的两个函数。
6. FileNotFoundError
如果出现:
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
即
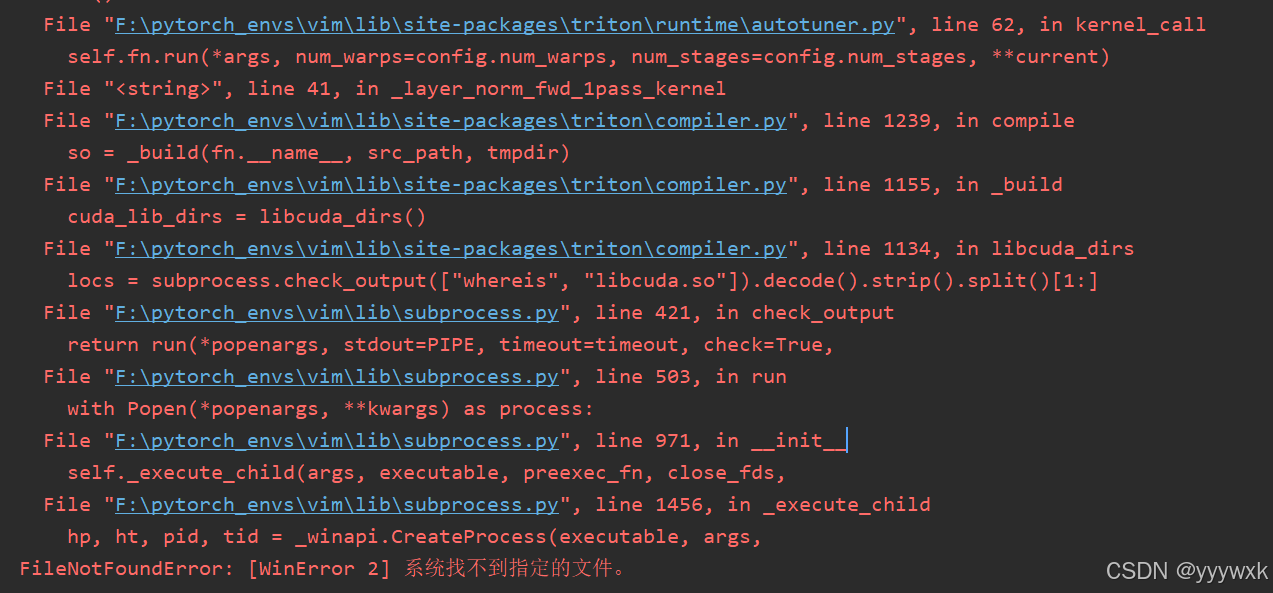
则还是因为调用了 triton 库,应该同 前述出现 KeyError: 'HOME' 一样,去环境中修改 layernorm.py 里面的两个函数。
20250109 更新
7. 关于 triton 的问题
由于 triton 官方目前只支持Linux,因此在 Windows 系统运行时,函数中只要涉及到其调用都会出现报错,包括但不限于:
KeyError: 'HOME'RuntimeError: failed to find C compiler, Please specify via cc environment variable.
终极解决方案参考Windows 下 Mamba / Vim / Vmamba 环境安装终极版:Windows 下Mamba2 / Vim / Vmamba 环境安装问题记录及解决方法终极版(无需绕过triton)
关于whl付费的说明
- 无论是Linux还是Win,在这些平台下面的Mamba,Vim 以及Vmamba 编译过程以及所有可能遇到的问题已经在本系列博客中全程开源并写明,不少同学按照本博客自己编译成功。
- 资金紧张但学有余力的同学请自己按照本教程自己动手编译,出现问题请查阅本系列所有博客,不鼓励从任何渠道购买!!!
- 为时间紧张的同学提供优惠通道:【causal-conv1d-1.1.1-cp310-cp310-win-amd64.whl】;【(Vim)mamba_ssm-1.1.1-cp310-cp310-win_amd64.whl】;【Window下Vim环境安装包】。
- 由于精力有限,只对【付费同学】全程售后,安装包本身没有价值,指导安装挤占了本人大量时间,所以付费其实是咨询费,其他同学随缘。
- 使用本人提供的whl请保证python、torch及cuda版本与博客里一致。否则会出现
DLL load failed问题。有环境版本定制化需求请私信vx。 - 网上有大量人抄袭本系列博客的教程,连本人当时随手建的环境都变成了这些教程的基础配置,还是请关注本系列博客的权威解答,除前述渠道外的其他渠道均需理性看待,谨防诈骗。


















 6553
6553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











