







导语
卷积神经网络(CNN)是AI界的“视觉拆解大师”——用数学的局部感知和参数共享,模拟人脑对视觉信号的层次化处理。其核心如同一个智能放大镜:卷积层用滑动滤波器提取局部特征(边缘→纹理→部件),池化层像信息压缩器保留显著特征,全连接层则扮演终极裁判,将空间拼图转化为分类决策。这种“局部感知-全局推理”的架构,让CNN在图像中既见树木又见森林,成为计算机视觉的基石模型。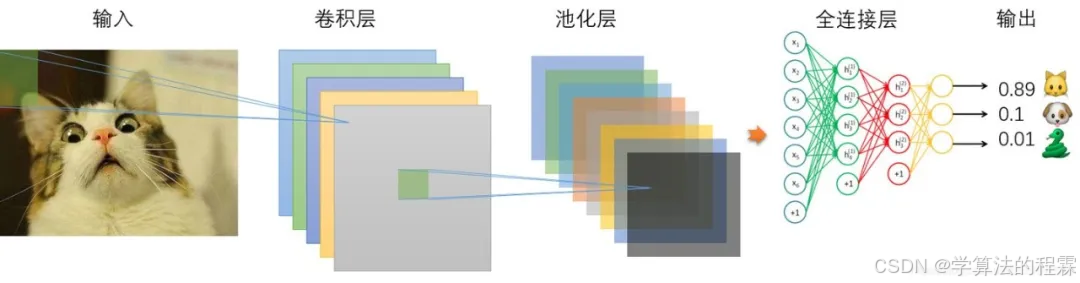
[👇️👇️卷积神经网络学习视频👇️👇️👇️]
大神勿进!适合新手入门的卷积神经网络原理详解教程,一口气学完CNN的卷积层、池化层、激活函数、全连接层、LeNet-5、AlexNet!机器学习|计算机视觉![]() https://www.bilibili.com/video/BV1PxoQYTExE/?spm_id_from=333.337.search-card.all.click【附源码】毕设有救了!整整30套CNN卷积神经网络项目!新手轻松拿捏!学完就能玩透人工智!pytorch/机器学习/计算机视觉/深度学习/Python
https://www.bilibili.com/video/BV1PxoQYTExE/?spm_id_from=333.337.search-card.all.click【附源码】毕设有救了!整整30套CNN卷积神经网络项目!新手轻松拿捏!学完就能玩透人工智!pytorch/机器学习/计算机视觉/深度学习/Python![]() https://www.bilibili.com/video/BV156DdYDEtk/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV156DdYDEtk/?spm_id_from=333.337.search-card.all.click
CNN历史
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算的前馈神经网络,图像处理中,图像数据具有非常高的维数(高维的RGB矩阵表示),因此训练一个标准的前馈网络来识别图像将需要成千上万的输入神经元,除了显而易见的高计算量,还可能导致许多与神经网络中的维数灾难相关的问题。
1962年,哈佛医学院神经生理学家Hubel和Wiesel通过猫视觉皮层细胞的研究,提出感受野(receptive field)的概念。
传统BP网络处理计算机视觉任务:权值太多,计算量太大。CNN通过局部感受野和权值共享,减少神经网络需要训练的参数个数。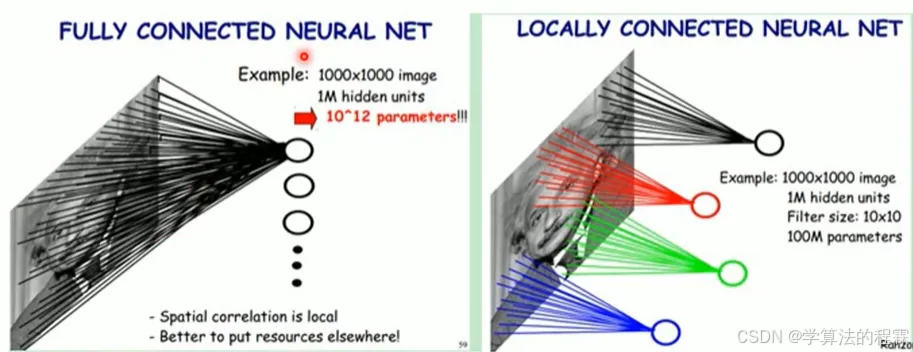
1. 雏形期(1980-1998)
-
1980:福岛邦彦提出 Neocognitron(CNN前身),首次引入"局部感受野"和"层次结构"概念。
-
推荐阅读:
Fukushima K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 1980.
-
-
1989:Yann LeCun等人将反向传播应用于CNN,用于手写数字识别。
-
关键论文:
LeCun Y, et al. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Computation, 1989.
-
2. 奠基期(1998-2012)
-
1998:LeCun提出 LeNet-5(首个现代CNN架构),用于MNIST分类。
-
必读论文:
LeCun Y, et al. Gradient-Based Learning Applied to Document Recognition. Proceedings of the IEEE, 1998.
-
3. 爆发期(2012-2015)
-
2012:AlexNet在ImageNet竞赛中夺冠(首次使用ReLU和Dropout)。
-
里程碑论文:
Krizhevsky A, et al. ImageNet Classification with Deep Convolutional Neural Networks. NeurIPS 2012.
-
-
2014:
-
VGGNet(证明深度的重要性):
Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR 2015. -
GoogLeNet(Inception模块):
Szegedy C, et al. Going Deeper with Convolutions. CVPR 2015.
-
4. 创新期(2015-至今)
-
2015:ResNet提出残差连接(解决梯度消失问题)。
-
核心论文:
He K, et al. Deep Residual Learning for Image Recognition. CVPR 2016.
-
-
2017:Transformer开始挑战CNN地位,但CNN仍有创新:
-
EfficientNet(复合缩放方法):
Tan M, Le Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. ICML 2019. -
ConvNeXt(CNN的现代化改造):
Liu Z, et al. A ConvNet for the 2020s. CVPR 2022.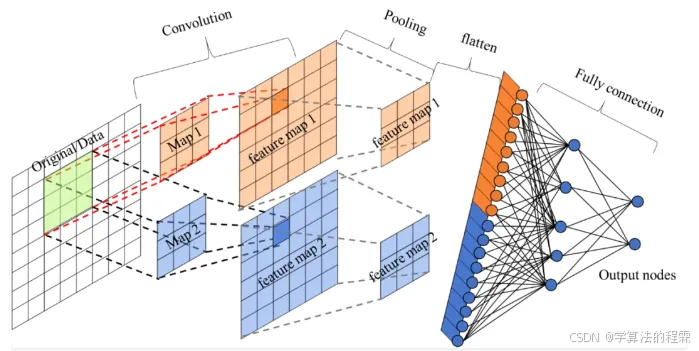
-
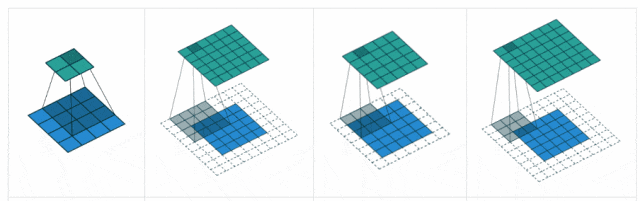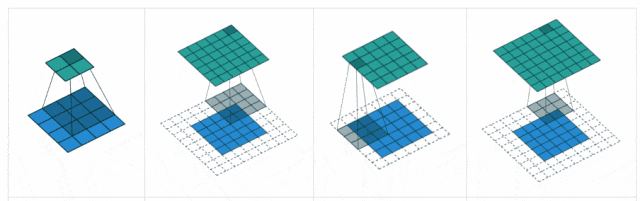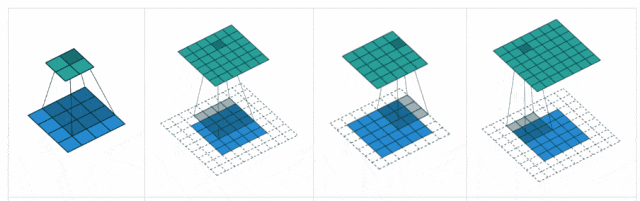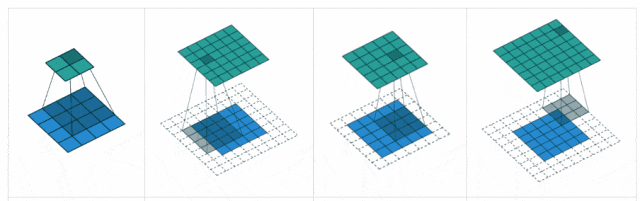
卷积、池化、填充
1. 卷积(Convolution)
自动学习并提取从低级到高级的层次化特征。
卷积 ≠ 滤波,但卷积是线性滤波的主流实现方式。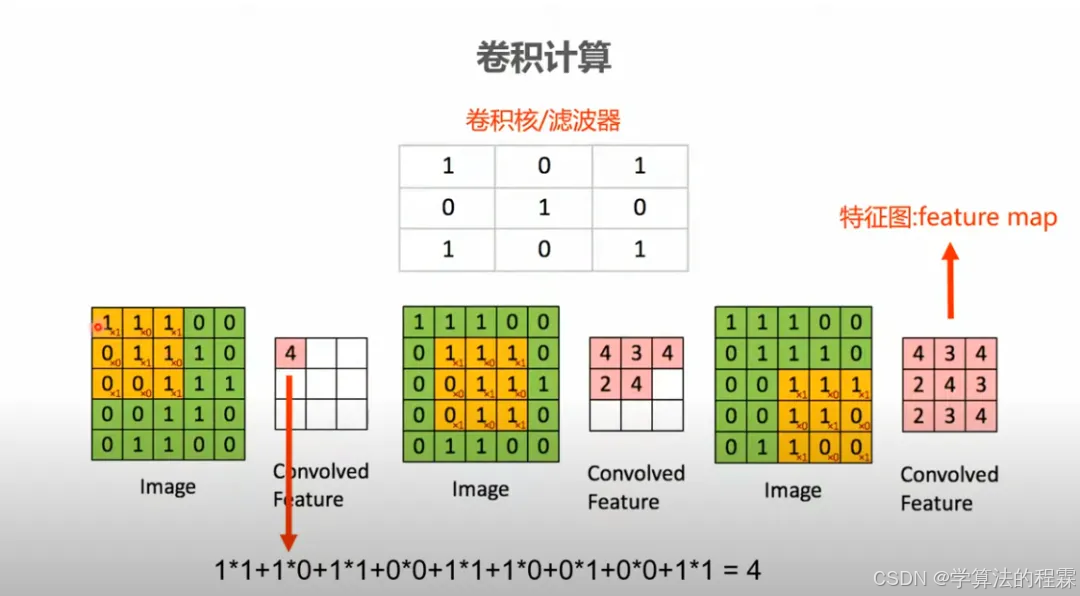
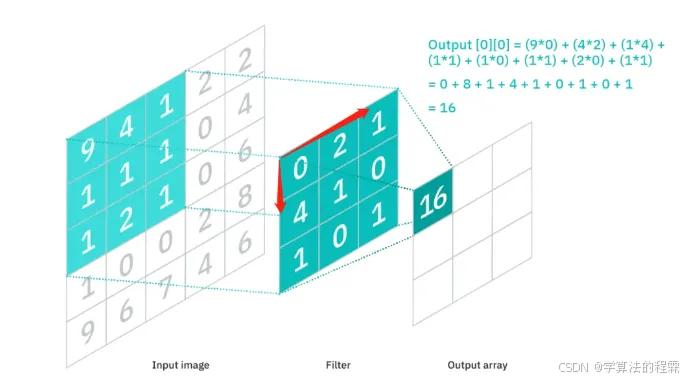
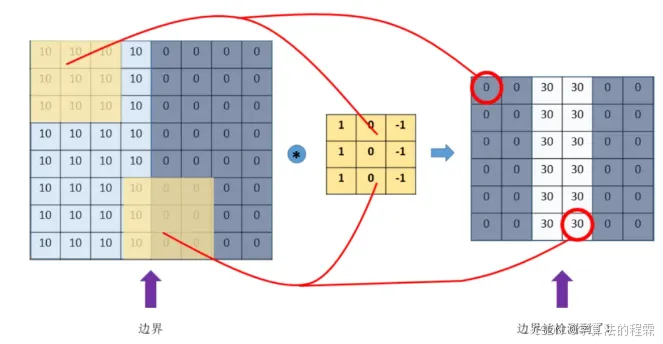
卷积核(Kernel):直观理解就是一个滤波矩阵,普遍使用的卷积核大小为3×3、5×5等。卷积核大小必须大于1才有提升感受野的作用,而大小为偶数的卷积核即使对称地加padding也不能保证输入feature map尺寸和输出feature map尺寸不变(假设n为输入宽度,d为padding个数,m为卷积核宽度,在步长为1的情况下,如果保持输出的宽度仍为n,公式,n+2d-m+1=n,得出m=2d+1,需要是奇数),所以一般都用3作为卷积核大小。
import cv2
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 'SimHei' 是黑体,你也可以尝试
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 1. 读取图像并转为灰度图
image = cv2.imread('lib.jpeg') # 替换为你的图片路径
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
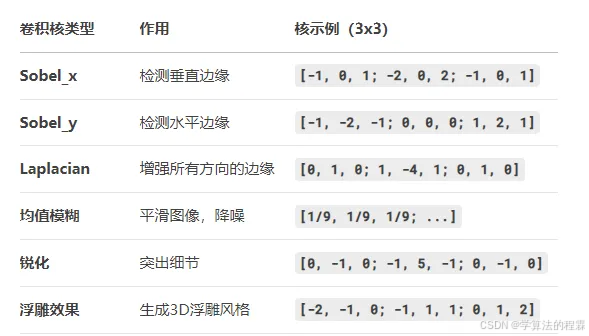
# 2. 定义不同卷积核
kernels = {
"原始图像": np.array([[0, 0, 0], [0, 1, 0], [0, 0, 0]]), # 无变化
"边缘检测 (Sobel_x)": np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]),
"边缘检测 (Sobel_y)": np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]]),
"边缘检测 (Laplacian)": np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]]),
"模糊(均值滤波)": np.ones((3, 3)) / 9.0,
"锐化": np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]]),
"浮雕效果": np.array([[-2, -1, 0], [-1, 1, 1], [0, 1, 2]])
}
# 3. 应用卷积核并可视化
plt.figure(figsize=(15, 10))
for i, (title, kernel) in enumerate(kernels.items(), 1):
filtered = cv2.filter2D(gray, -1, kernel) # 应用卷积核
plt.subplot(3, 3, i)
plt.imshow(filtered, cmap='gray')
plt.title(title)
plt.axis('off')
plt.tight_layout()
plt.show() 

卷积是CNN的核心运算,本质是局部特征提取器。其工作流程可概括为:
-
滑动扫描:卷积核(滤波器)在输入数据(如图像)上逐像素滑动;
-
局部加权:每个位置计算核与对应局部区域的点积,得到特征响应值;
-
特征映射:所有位置的响应值组成输出特征图,突出输入中的特定模式(如边缘、纹理)。
-
步长(Stride):卷积核遍历特征图时每步移动的像素,如步长为1则每次移动1个像素,步长为2则每次移动2个像素(即跳过1个像素),以此类推。步长越小,提取的特征会更精细。
-
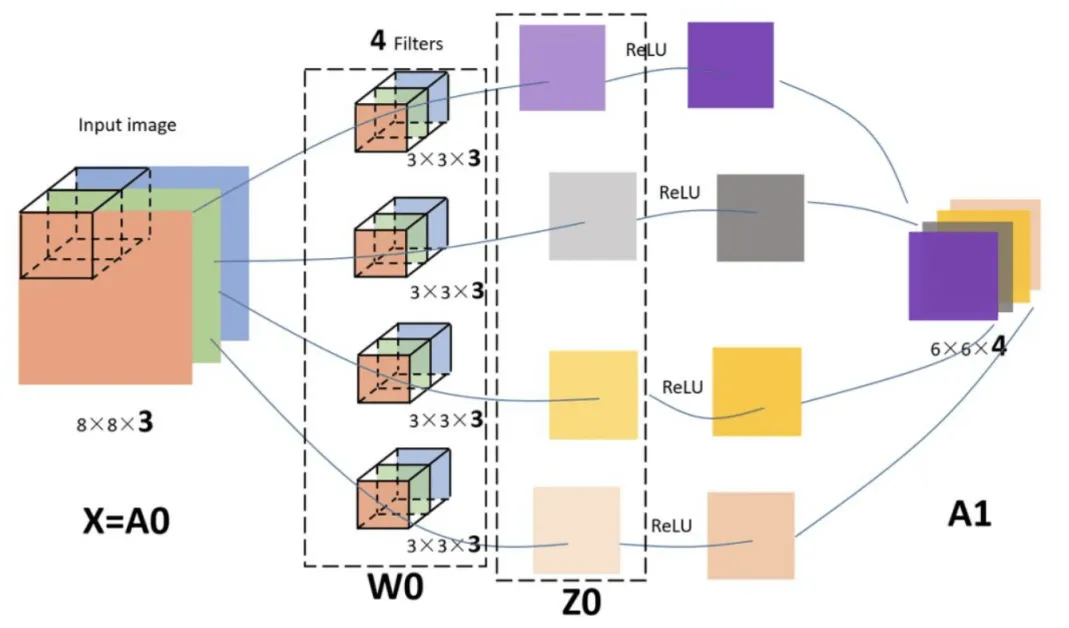
多通道(channels)图片的卷积
彩色图像,一般都是RGB三个通道(channel)的,因此输入数据的维度一般有三个:(长,宽,通道),图中的输入图像是(8,8,3),filter有4个,大小均为(3,3,3),得到的输出为(6,6,4)。
2.池化(Pooling)
CNN中的特征压缩器,用"局部摘要"取代细节。
(1) Max Pooling
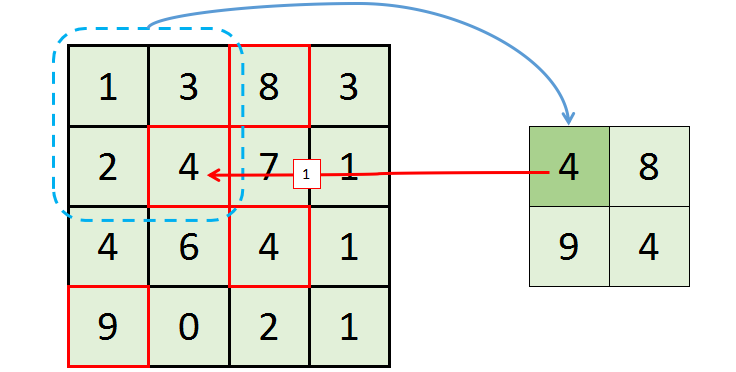

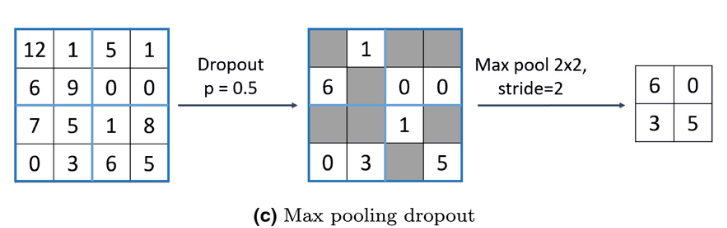
Dropout:训练时随机关闭部分神经元(如关闭50%),防止网络训练过拟合,迫使网络不依赖特定节点,提升泛化能力。
(2) Average Pooling/Mean Pooling
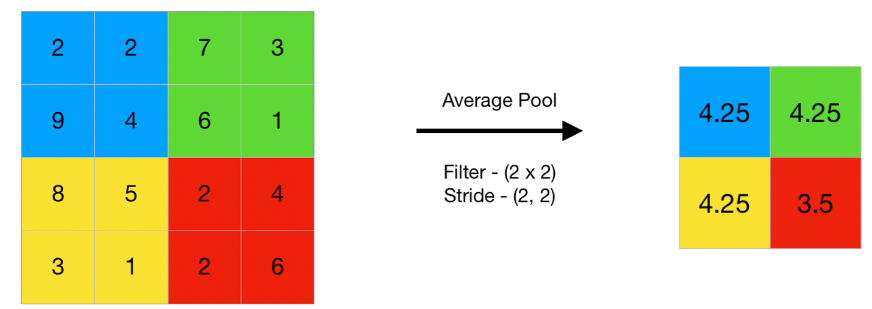
(3) Global Pooling/Stochastic Pooling
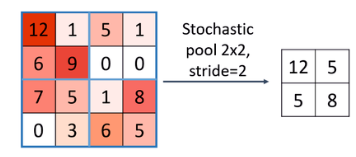
-
填充(Padding):处理特征图边界的方式,一般有两种,一种是“valid”,对边界外完全不填充,只对输入像素执行卷积操作,这样会使输出特征图像尺寸变得更小,且边缘信息容易丢失;另一种是还是“same”,对边界外进行填充(一般填充为0),再执行卷积操作,这样可使输出特征图的尺寸与输入特征图的尺寸一致,边缘信息也可以多次计算。

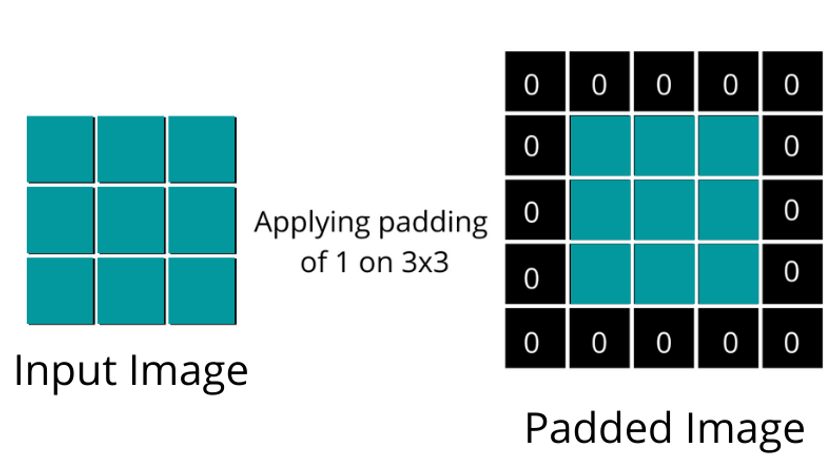
-
本质:补偿卷积核的尺寸缩减,空间维度的“缓冲区”,平衡特征提取与分辨率损失。
MNIST手写数字分类实践

1.MNIST数据集
国内镜像下载:
https://ossci-datasets.s3.amazonaws.com/mnist/train-images-idx3-ubyte.gz
https://ossci-datasets.s3.amazonaws.com/mnist/train-labels-idx1-ubyte.gz
https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz
https://ossci-datasets.s3.amazonaws.com/mnist/t10k-labels-idx1-ubyte.gz
采用一种名为 IDX 的二进制格式存储,专为高效存储多维数组设计(见于机器学习领域)。

import numpy as np
import struct
def read_idx3_ubyte(filename):
with open(filename, 'rb') as f:
# 读取文件头(16字节)
magic, num_images, rows, cols = struct.unpack('>IIII', f.read(16))
# 读取像素数据(无符号字节)
data = np.frombuffer(f.read(), dtype=np.uint8)
# 重塑为 [num_images, rows, cols]
return data.reshape(num_images, rows, cols)
images = read_idx3_ubyte('./data/raw/train-images.idx3-ubyte')
print(images.shape) # MNIST输出: (60000, 28, 28)2.LeNet-5手写体识别实践
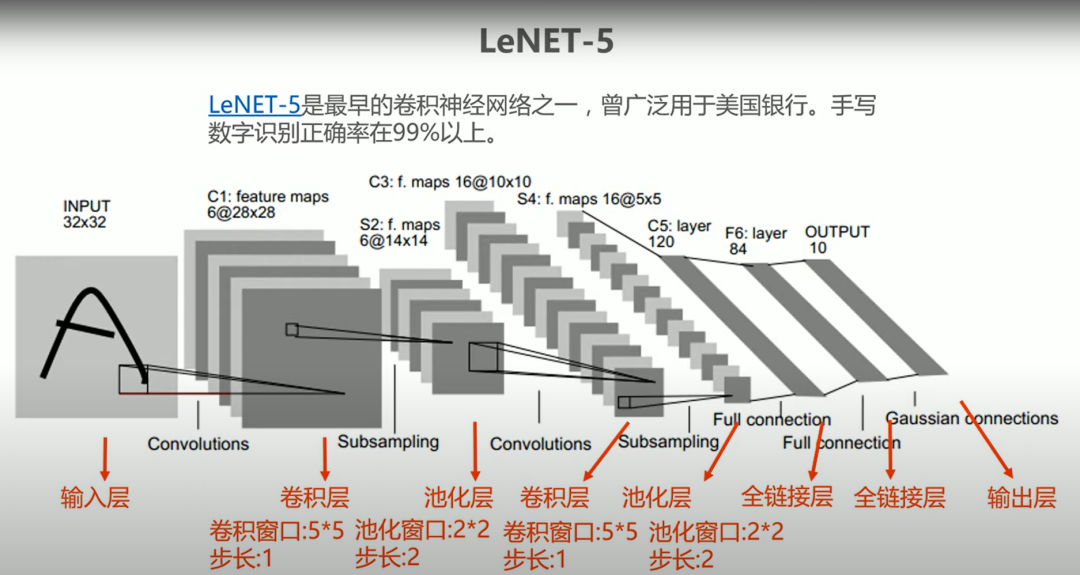
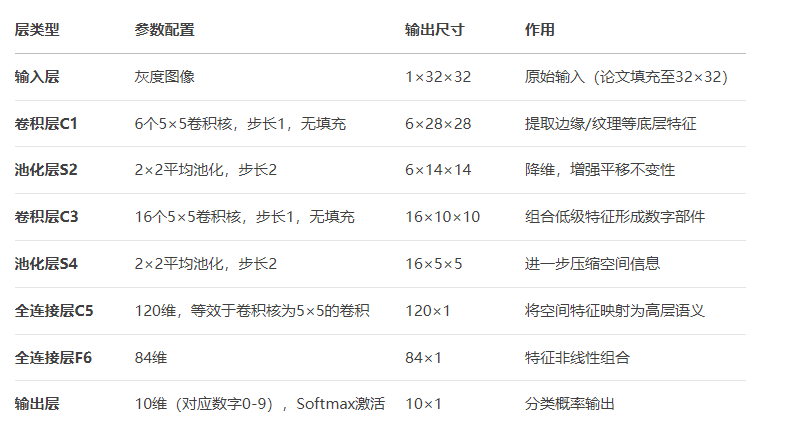
LeNet-5 是Yann LeCun于1998年提出的经典卷积神经网络,专为手写数字识别(如MNIST)设计,被视为现代CNN的奠基之作。LeNet-5首次验证了卷积+池化+全连接架构的有效性,奠定了CNN三大核心设计思想:
-
局部感受野(卷积核)
-
权值共享(卷积核滑动)
-
空间降采样(池化)
其设计理念直接影响了后续AlexNet、ResNet等现代CNN架构。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import numpy as np
import struct
import matplotlib.pyplot as plt
from torchvision import transforms
from PIL import Image
# 设置中文字体显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# ----------------------
# 1. 自定义数据集加载
# ----------------------
class MNISTDataset(Dataset):
def __init__(self, img_path, label_path, transform=None):
# 读取图像数据
with open(img_path, 'rb') as f:
magic, num, rows, cols = struct.unpack('>IIII', f.read(16))
self.images = np.frombuffer(f.read(), dtype=np.uint8).reshape(num, rows, cols)
# 读取标签数据
with open(label_path, 'rb') as f:
magic, num = struct.unpack('>II', f.read(8))
self.labels = np.frombuffer(f.read(), dtype=np.uint8)
self.transform = transform
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
image = self.images[idx]
label = self.labels[idx]
# 应用数据转换
if self.transform:
image = Image.fromarray(image)
image = self.transform(image)
else:
image = torch.from_numpy(image).float().unsqueeze(0) / 255.0
return image, label
# ----------------------
# 2. 数据预处理与加载
# ----------------------
def get_data_loaders(train_img_path, train_label_path, test_img_path, test_label_path, batch_size=64):
# 数据预处理管道
transform = transforms.Compose([
transforms.Resize((32, 32)), # 调整图像尺寸为32x32以匹配LeNet-5输入
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])
# 创建数据集
train_dataset = MNISTDataset(
img_path=train_img_path,
label_path=train_label_path,
transform=transform
)
test_dataset = MNISTDataset(
img_path=test_img_path,
label_path=test_label_path,
transform=transform
)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
return train_loader, test_loader
# ----------------------
# 3. LeNet-5模型定义
# ----------------------
class LeNet5(nn.Module):
def __init__(self, num_classes=10):
super(LeNet5, self).__init__()
# 特征提取部分
self.features = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), # 输入[1,32,32] -> 输出[6,32,32]
nn.Tanh(),
nn.AvgPool2d(kernel_size=2, stride=2), # 输出[6,16,16]
nn.Conv2d(6, 16, kernel_size=5), # 输出[16,12,12]
nn.Tanh(),
nn.AvgPool2d(kernel_size=2, stride=2), # 输出[16,6,6]
)
# 分类器部分
self.classifier = nn.Sequential(
nn.Linear(16 * 6 * 6, 120),
nn.Tanh(),
nn.Linear(120, 84),
nn.Tanh(),
nn.Linear(84, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1) # 展平为[batch_size, 16*6*6]
x = self.classifier(x)
return x
# ----------------------
# 4. 训练与测试函数
# ----------------------
def train(model, train_loader, criterion, optimizer, device, epoch, log_interval=100):
model.train()
train_loss = 0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
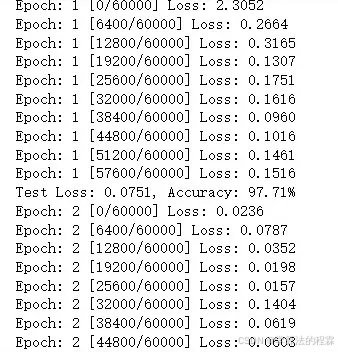
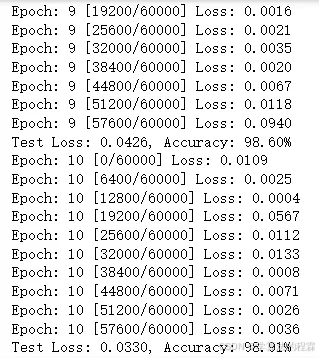
if batch_idx % log_interval == 0:
print(f'Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} '
f'({100. * batch_idx / len(train_loader):.0f}%)]\t'
f'Loss: {loss.item():.4f}\t'
f'Accuracy: {100. * correct / total:.2f}%')
avg_loss = train_loss / len(train_loader)
accuracy = 100. * correct / total
return avg_loss, accuracy
def test(model, test_loader, criterion, device):
model.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
avg_loss = test_loss / len(test_loader)
accuracy = 100. * correct / total
print(f'Test set: Average loss: {avg_loss:.4f}, '
f'Accuracy: {correct}/{total} ({accuracy:.2f}%)')
return avg_loss, accuracy
# ----------------------
# 5. 可视化函数
# ----------------------
def visualize_predictions(model, test_loader, device, num_samples=10):
model.eval()
data, target = next(iter(test_loader))
data, target = data[:num_samples].to(device), target[:num_samples].to(device)
with torch.no_grad():
output = model(data)
preds = output.argmax(dim=1)
data = data.cpu()
plt.figure(figsize=(15, 5))
for i in range(num_samples):
plt.subplot(2, 5, i+1)
plt.imshow(data[i].squeeze(), cmap='gray')
plt.title(f'预测: {preds[i].item()} | 实际: {target[i].item()}', fontsize=12)
plt.axis('off')
plt.tight_layout()
plt.show()
def plot_training_history(train_losses, train_accs, test_losses, test_accs):
plt.figure(figsize=(12, 5))
# 绘制损失曲线
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='训练损失')
plt.plot(test_losses, label='测试损失')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.legend()
plt.title('训练和测试损失')
# 绘制准确率曲线
plt.subplot(1, 2, 2)
plt.plot(train_accs, label='训练准确率')
plt.plot(test_accs, label='测试准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率 (%)')
plt.legend()
plt.title('训练和测试准确率')
plt.tight_layout()
plt.show()
# ----------------------
# 6. 主函数
# ----------------------
def main():
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'使用设备: {device}')
# 加载数据
train_loader, test_loader = get_data_loaders(
train_img_path='./data/raw/train-images.idx3-ubyte',
train_label_path='./data/raw/train-labels.idx1-ubyte',
test_img_path='./data/raw/t10k-images.idx3-ubyte',
test_label_path='./data/raw/t10k-labels.idx1-ubyte'
)
# 初始化模型
model = LeNet5().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练配置
epochs = 10
train_losses, train_accs = [], []
test_losses, test_accs = [], []
# 训练循环
for epoch in range(1, epochs + 1):
print(f'\nEpoch {epoch}/{epochs}')
train_loss, train_acc = train(model, train_loader, criterion, optimizer, device, epoch)
test_loss, test_acc = test(model, test_loader, criterion, device)
# 记录训练历史
train_losses.append(train_loss)
train_accs.append(train_acc)
test_losses.append(test_loss)
test_accs.append(test_acc)
# 可视化训练历史
plot_training_history(train_losses, train_accs, test_losses, test_accs)
# 可视化预测结果
visualize_predictions(model, test_loader, device)
if __name__ == '__main__':
main()

[👇️👇️卷积神经网络学习视频👇️👇️👇️]
大神勿进!适合新手入门的卷积神经网络原理详解教程,一口气学完CNN的卷积层、池化层、激活函数、全连接层、LeNet-5、AlexNet!机器学习|计算机视觉![]() https://www.bilibili.com/video/BV1PxoQYTExE/?spm_id_from=333.337.search-card.all.click【附源码】毕设有救了!整整30套CNN卷积神经网络项目!新手轻松拿捏!学完就能玩透人工智!pytorch/机器学习/计算机视觉/深度学习/Python
https://www.bilibili.com/video/BV1PxoQYTExE/?spm_id_from=333.337.search-card.all.click【附源码】毕设有救了!整整30套CNN卷积神经网络项目!新手轻松拿捏!学完就能玩透人工智!pytorch/机器学习/计算机视觉/深度学习/Python![]() https://www.bilibili.com/video/BV156DdYDEtk/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV156DdYDEtk/?spm_id_from=333.337.search-card.all.click


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









