







高斯分布是机器学习领域中一个重要的概率分布模型,高斯模型分为单高斯模型和混合高斯模型,其中,混合高斯分布能更好地刻画历史数据集中的数据分布,因此,本文将详细叙述混合高斯模型的理论及其模型求解方法。
首先,先介绍单高斯模型。多维高斯分布的概率密度函数定义如下:
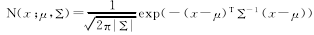
其中,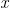
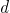
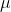
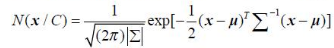
式(2)表明样本属于类别C的概率大小。从而,将任意测试样本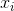
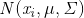
针对复杂数据集而言,一个单高斯模型往往不能完整地描述其数据的分布情况,因此需要用多个高斯模型来逼近数据的分布,即,使用混合高斯模型(GMM, Gaussian Mixture Model)来逼近。
在GMM中,对于给定的训练集样本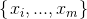
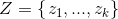
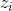
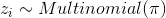
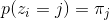
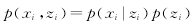
GMM模型中有3个需要求解的变量,分别为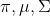
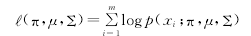
将式(3)代入(4)中,得到:

在做参数估计的时候,一般是通过对待求变量进行求导来求极值的,但是,上式中,log中又有求和,故如果采取求导的方式求极值,将会十分复杂,且没有闭合解。因此,可以采用EM算法来估计各个参数,EM算法的求解分为两步:第一步,假设知道各个高斯模型的参数(可以初始化,或基于上一步迭代结果),然后去估计每个高斯模型的权值;第二步,基于估计的权值,再去迭代高斯模型的参数,重复这两步,直到收敛为止。EM具体表达如下:
1.(E step)
对于第i个样本
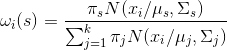
2. (M step)
在得到每个点的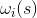
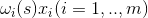



用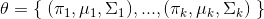
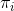
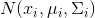

其中,















 263
263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









