







深度学习中激活函数的作用是能够给神经网络加入一些非线性因素,使得神经网络可以更好地解决较为复杂的问题。没有激活函数,即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的,可见激活函数的重要性如此之大。下面,分别介绍深度学习中常用的激活函数。
1. sigmoid
sigmoid的公式如下:
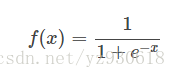
函数对应的图像如下:
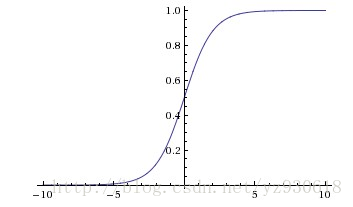
优点:
1. sigmoid函数的输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可以用于输入的归一化,也可以用作输出层。
2. 求导容易
缺点:
1. 由于其软饱和性,即容易产生梯度消失,导致训练出现问题。
2. 其输出并不是以0为中心的。
2. tanh
tanh的公式如下:
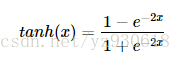
函数对应的图像如下:
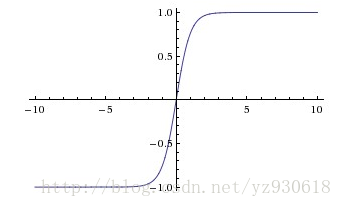
优点:
1. 比sigmoid函数收敛速度更快。
2. 相比sigmoid函数,其输出以0为中心。
缺点:
1. 依旧具有软饱和问题。
3. Relu
Relu的公式如下:
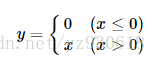
函数对应的图像如下:
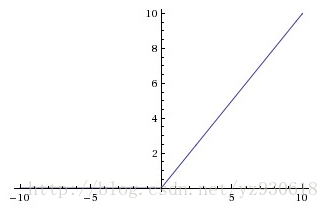
优点:
1. Relu具有线性、非饱和的特点,并且相比Sigmoid和tanh,Relu的收敛速度更快。
2. Relu实现比较简单。
3. Relu有效缓解了梯度下降问题。
4. 提供了神经网络的稀疏表达能力
缺点:
1. 随着训练的进行,可能会出现神经元死亡,权重无法更新的情况。
2. 当x<0时,Relu是硬饱和的。
4. LReLU/PReLU
针对在x<0时的硬饱和问题,LReLu对Relu进行了改进,其公式如下:
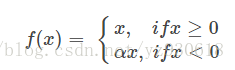
函数的图像如下:
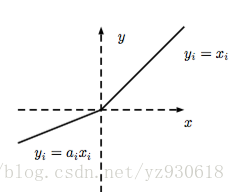
LReLU的目的是避免梯度消失,所以LReLU对准确率并没有太大的影响。此外,必须非常小心谨慎地重复训练,从而选取合适的参数a。这样会十分麻烦,因此PReLu就此诞生,可以自适应地从数据中学习参数。PReLU具有收敛速度快、错误率低的特点,可以用于反向传播的训练。
5. ELU
ELU的公式如下:

函数的图像如下:
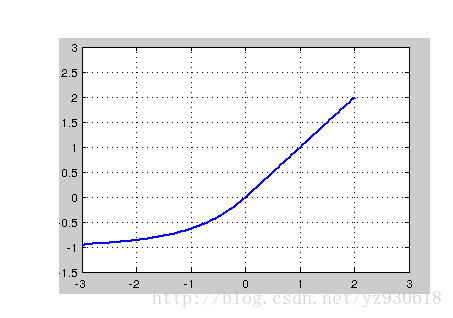
优点:
1. ELU融合了sigmoid和ReLU,左侧具有软饱和性,右侧无饱和性。
右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够 让ELU对输入变化或噪声更鲁棒。
2. ELU的输出均值接近于零,所以收敛速度更快。
总结
关于激活函数的选取,需要结合实际情况,并且要考虑不同激活函数的优缺点,不能盲目使用一种激活函数。















 3516
3516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









