







分享学习Python爬虫、数据分析、数据挖掘的点滴。
最近发现了抖音无水印视频的下载方法。
# 抖音接口
「url」参数值就是从抖音上复制的链接。
##Python下载
首先来看一下,直接访问抖音链接得到的结果。

妥妥的水印…
接下来打开浏览器的开发者工具,看看视频的地址。
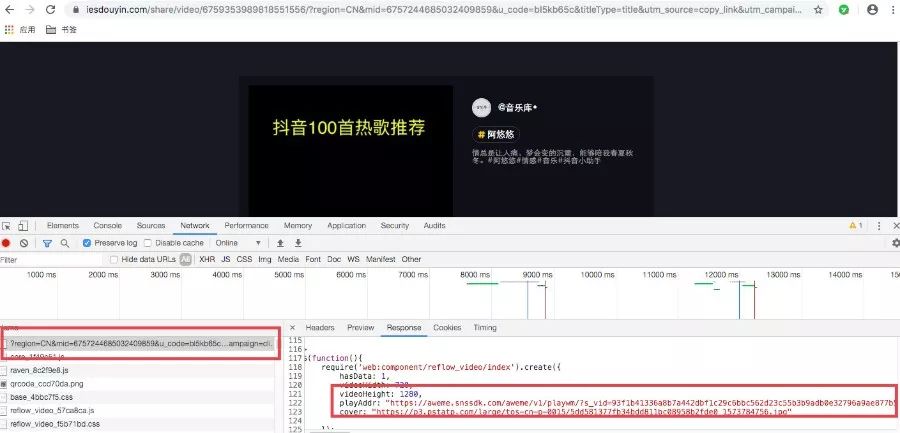
可以发现「playAddr」就是视频的地址,复制然后访问。
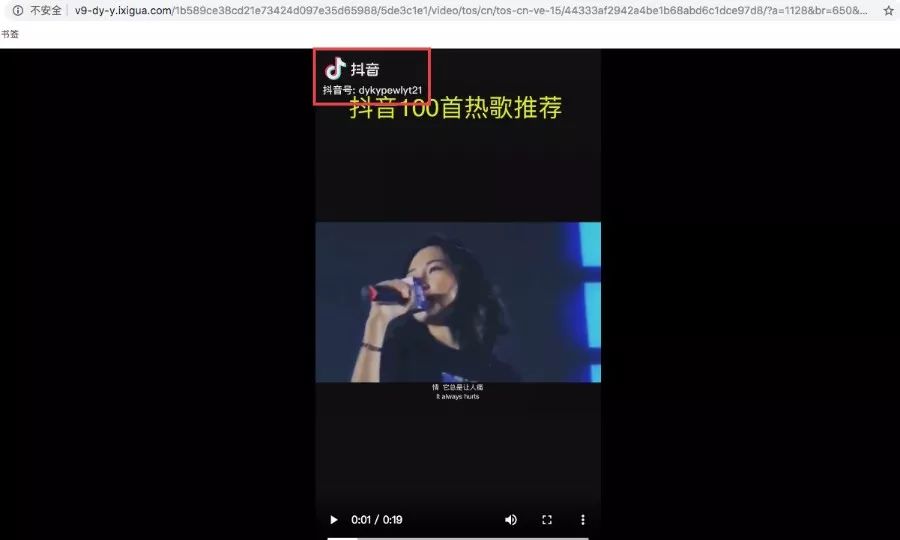
链接会重定向到以「v9」开头的链接,然而还是有水印。
接下来就是重点了,首先你需要让你的浏览器能够修改UA,即爬虫经常用到的「User-Agent」。
我用的是Mac+谷歌浏览器,就说说我自己怎么修改的。
Windows的请自行百度~
首先在电脑的文稿中创建一个文件夹。
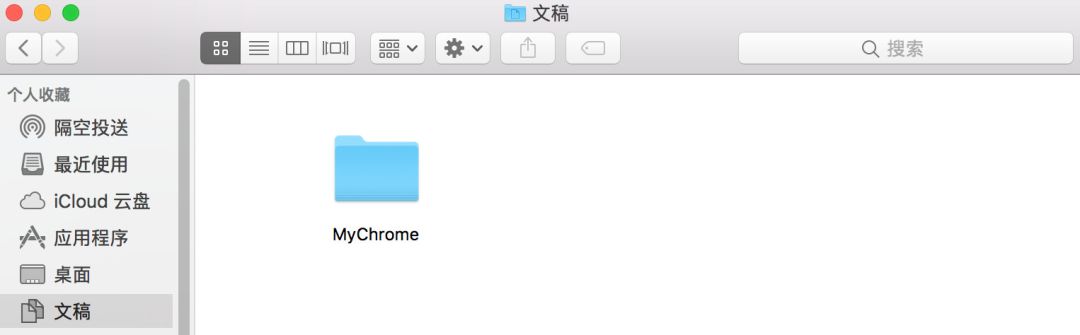
这个文件夹的路径如下。
/Users/star-river/Documents/MyChrome
并且在根目录的终端运行下面这段代码。
open -n /Applications/Google\ Chrome.app/ --args --disable-web-security --user-data-dir=/Users/star-river/Documents/MyChrome
如此我的谷歌浏览器就能成功更换UA啦!
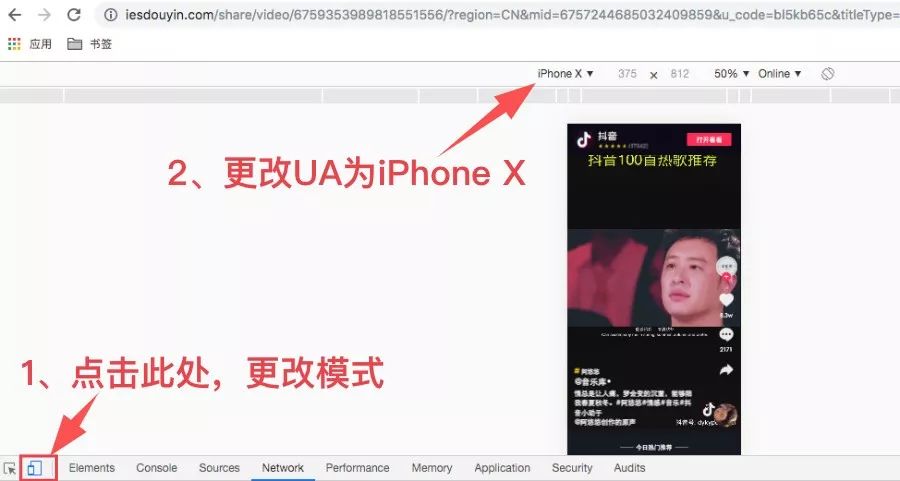
还是直接访问抖音的链接,可以看到结果和最初的不一样。
就在这个模式下查找接口。
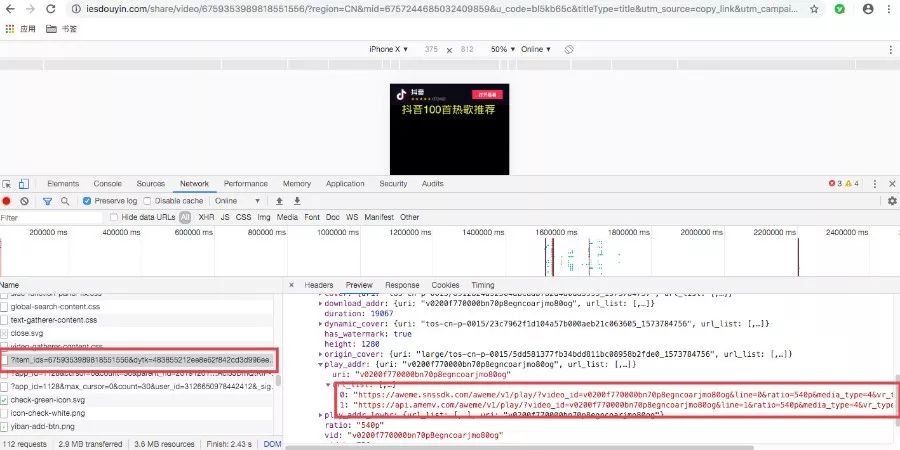
发现「?item_ids」开头的这个接口就包含了我们想要的无水印抖音视频。
就是「play_addr」下的列表中的那两个链接。
其中「?item_ids」开头的这个接口有两个参数需要我们在另一个接口中获取。
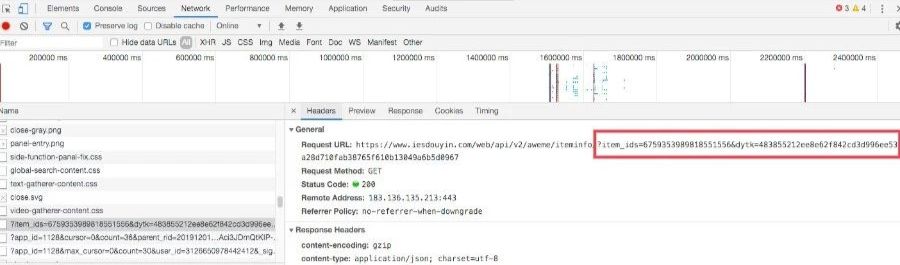
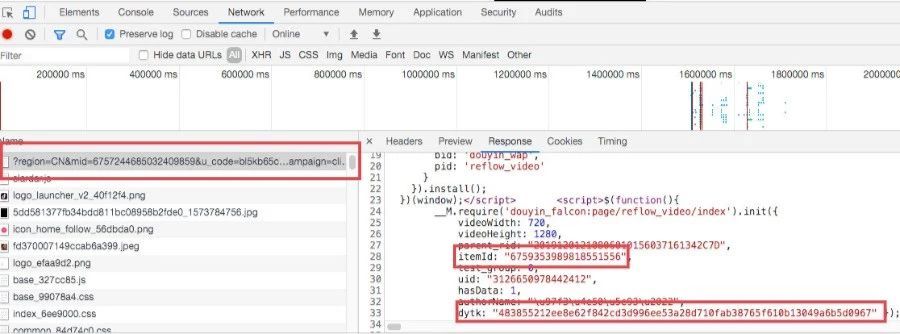
这样「item_ids」和「dytk」参数值我们也知道了。
不过我们直接用浏览器访问获取到的那两个链接是不会直接出现视频的,需要和上面的一样。
也改变一下UA,这里的链接如果还用「iPhone X」这个UA访问,会失败。
什么原因,小F就不得而知了…
把浏览器UA改为「Responsive」即可访问,链接会重定向。
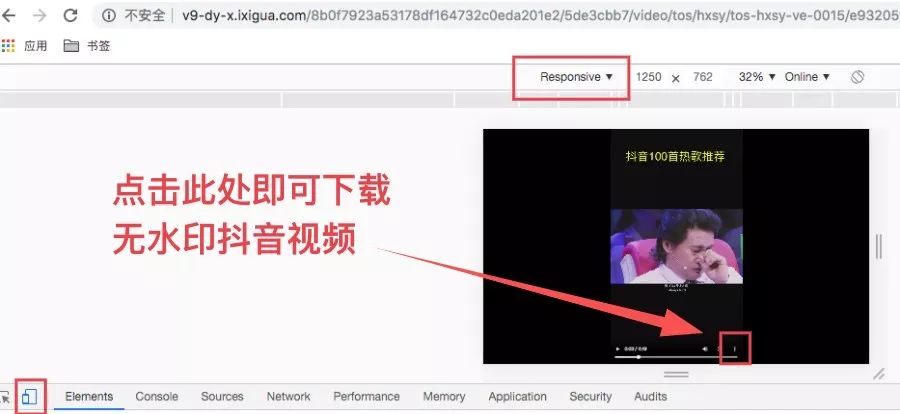
这样无水印的抖音视频就搞定了。
不过要是每个视频都需要这么下载,就太麻烦了。
所以写了用Python就可以下载视频的代码。
import requests
import json
import re
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'max-age=0',
# 这个貌似很重要
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36',
}
def download(url):
"""
下载抖音无水印视频
"""
# 获取接口参数
html = requests.get(url=url, headers=headers)
title = re.findall('itemId: "(.*?)",', html.text)[0]
dytk = re.findall('dytk: "(.*?)" }', html.text)[0]
# 拼接接口
url_item = 'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=' + title + '&dytk=' + dytk
# 获取抖音无水印视频链接
html_item = requests.get(url=url_item, headers=headers)
# 字符串转字典
content = json.loads(html_item.text)
# 视频接口
url_video = content['item_list'][0]['video']['play_addr']['url_list'][1]
response = requests.get(url_video, headers=headers, allow_redirects=True)
# 获取重定向后的链接,这个也是无水印视频的下载链接,不过本次没用
redirect = response.url
print(redirect)
# 视频是二进制,需要这种下载办法
video = requests.get(url_video, headers=headers).content
video_name = "douyin.mp4"
with open(video_name, 'wb') as f:
f.write(video)
f.flush()
print("下载完成")
if __name__ == '__main__':
# 抖音链接
url = 'https://v.douyin.com/XJj85H/'
download(url)
无水印视频完美下载。
##接口下载
既然知道了如何用Python下载视频。
那么小F想让大家下载的更方便一点,所以将程序部署到了服务器上。
你只需要通过小F的接口即可下载视频,代码如下。
from flask import Flask, request, send_file
import requests
import json
import re
app = Flask(__name__)
# 只接受get方法访问
@app.route("/douyin/", methods=["GET"])
def check():
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'max-age=0',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36',
}
# 默认返回内容
return_dict = {'code': 1, 'result': False, 'msg': '请求成功'}
# 判断入参是否为空
if request.args is None:
return_dict['return_code'] = '504'
return_dict['return_info'] = '请求参数为空'
return json.dumps(return_dict, ensure_ascii=False)
# 获取传入的参数
get_data = request.args.to_dict()
url = get_data.get('url')
# 获取接口参数
html = requests.get(url=url, headers=headers)
title = re.findall('itemId: "(.*?)",', html.text)[0]
dytk = re.findall('dytk: "(.*?)" }', html.text)[0]
# 拼接接口
url_item = 'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=' + title + '&dytk=' + dytk
# 获取抖音无水印视频链接
html_item = requests.get(url=url_item, headers=headers)
# 字符串转字典
content = json.loads(html_item.text)
# 获取视频相关的信息
# data = {}
# 视频的描述
# data['videoDesc'] = content['item_list'][0]['desc']
# 视频的封面图,小图
# data['dynamiCoverUrl'] = content['item_list'][0]['video']['dynamic_cover']['url_list'][0]
# 视频的封面图,大图
# data['staticCoverUrl'] = content['item_list'][0]['video']['origin_cover']['url_list'][0]
# 视频的评论数
# data['comments'] = content['item_list'][0]['statistics']['comment_count']
# 视频的点赞数
# data['prise'] = content['item_list'][0]['statistics']['digg_count']
# 视频接口
url_video = content['item_list'][0]['video']['play_addr']['url_list'][1]
response = requests.get(url_video, headers=headers, allow_redirects=True)
# 获取重定向后的链接,这个也是无水印视频的下载链接,不过本次没用
redirect = response.url
# print(redirect)
# 视频的下载链接
# data['videoPlayAddr'] = redirect
# 返回视频的信息
# return_dict['result'] = data
# 返回结果
# return json.dumps(return_dict, ensure_ascii=False)
video = requests.get(url=redirect, headers=headers).content
video_name = "douyin.mp4"
with open(video_name, 'wb') as f:
f.write(video)
f.flush()
return send_file('douyin.mp4')
if __name__ == "__main__":
# 本地调试
app.run(debug=True)
# 部署上线
# app.run(host='127.0.0.1', port=443)
如果本地安装了Flask以及Requests库,这个程序是可以直接运行。
并且能够下载到你所想要的无水印抖音视频。
# 本地接口
http://127.0.0.1:500/douyin/?url=https://v.douyin.com/CoQBx1/
部署到服务器上的话,则需要使用443端口。
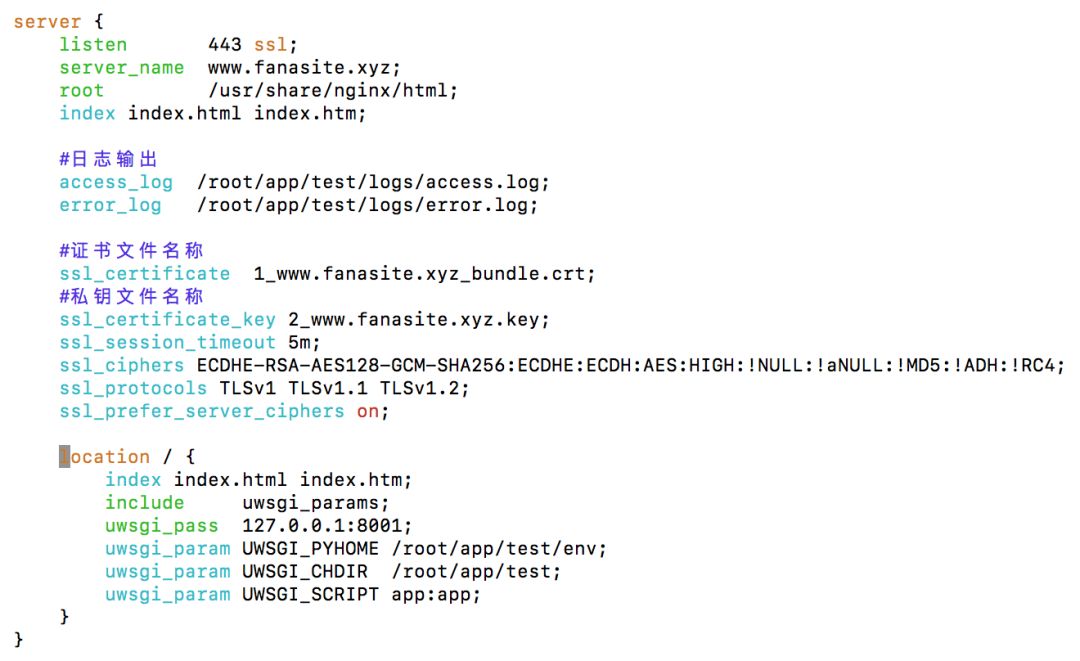
文末
您的点赞收藏就是对我最大的鼓励!
欢迎关注我,分享Python干货,交流Python技术。
对文章有何见解,或者有何技术问题,欢迎在评论区一起留言讨论!

















 3468
3468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









