






以下提供基于不同框架的物体识别实现方案,涵盖图片、视频及摄像头实时检测场景,结合YOLO、TensorFlow等主流技术实现。代码示例均经过简化,可直接运行。
一、基于YOLOv5的物体识别(推荐方案)
YOLOv5是当前高效的实时检测框架,代码示例如下:
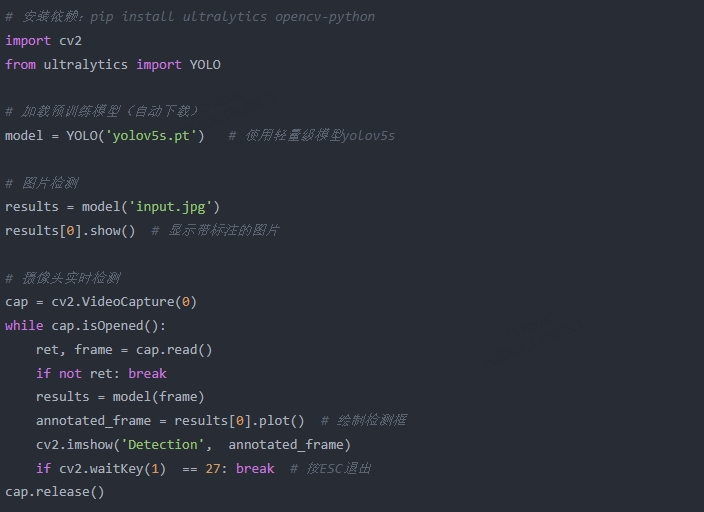
关键点说明:
使用ultralytics库简化了YOLO模型调用,支持自动下载权重文件。
yolov5s.pt 为轻量级模型,可在CPU/GPU上运行,适合实时检测。
二、基于OpenCV与YOLOv3的经典实现
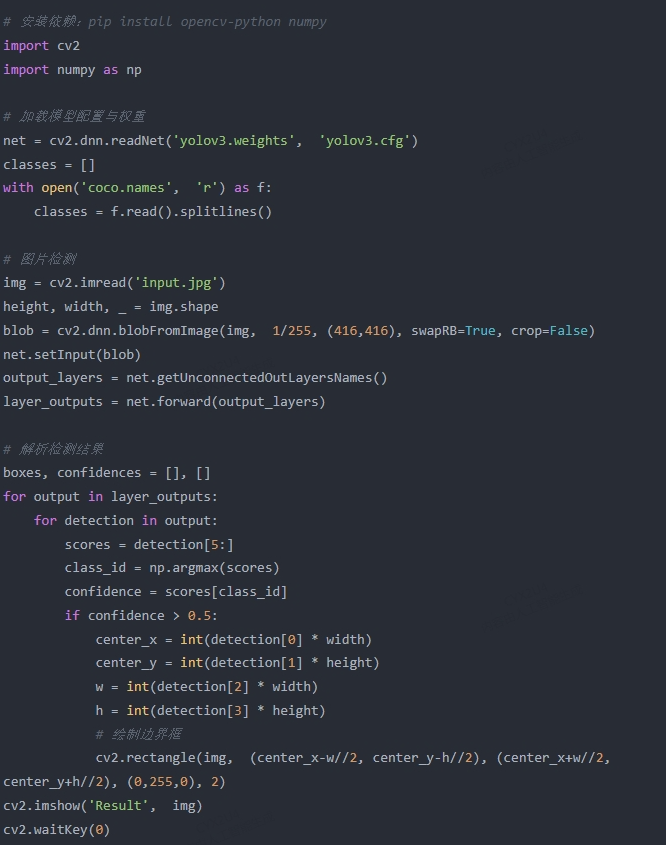
关键点说明:
需手动下载yolov3.weights 、yolov3.cfg 和coco.names 文件。
使用OpenCV的dnn模块直接调用YOLO模型,适合嵌入式设备部署。
三、基于TensorFlow Object Detection API
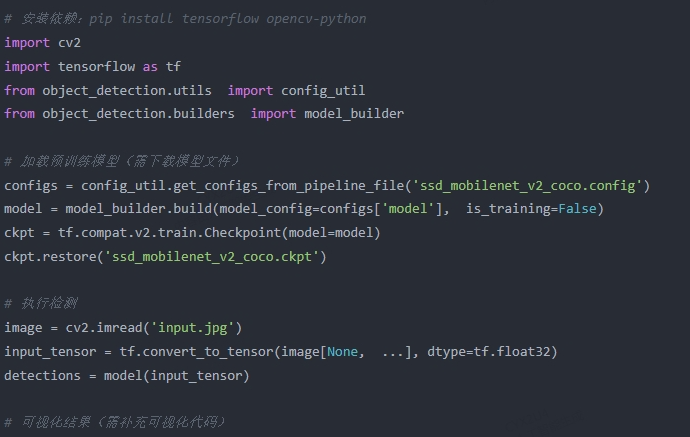
关键点说明:
需预下载SSD MobileNet模型文件(含.config和.ckpt)。
适合需要自定义训练的场景,但部署复杂度较高。
四、运行与优化建议
环境准备:
推荐使用Python 3.8+和PyTorch 1.10+环境。
GPU加速需安装CUDA和cuDNN(YOLOv5/TensorFlow版本需匹配)。
模型选择:
实时性优先:YOLOv5s > SSD MobileNet > YOLOv3
精度优先:YOLOv5x > Faster R-CNN
扩展功能:
多线程处理:使用threading模块分离图像采集与推理过程。
结果保存:通过cv2.VideoWriter保存检测后的视频流。
完整代码及模型文件可参考:
YOLO官方仓库:https://github.com/ultralytics/yolov5
TensorFlow Models:https://github.com/tensorflow/models3


















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











