







原型模式
前言
创建型模式的主要关注点是“怎样创建对象?”,它的主要特点是“将对象的创建与使用分离”。这样可以降低系统的耦合度,使用者不需要关注对象的创建细节。
创建型模式分为:
单例模式
工厂方法模式
抽象工程模式
原型模式
建造者模式
原型模式

1. 原型模式
1.1 概述
用一个已经创建的实例作为原型,通过复制该原型对象来创建一个和原型对象相同的新对象。
1.2 结构
抽象原型类:规定了具体原型对象必须实现的的 clone() 方法。
具体原型类:实现抽象原型类的 clone() 方法,它是可被复制的对象。
访问类:使用具体原型类中的 clone() 方法来复制新的对象。
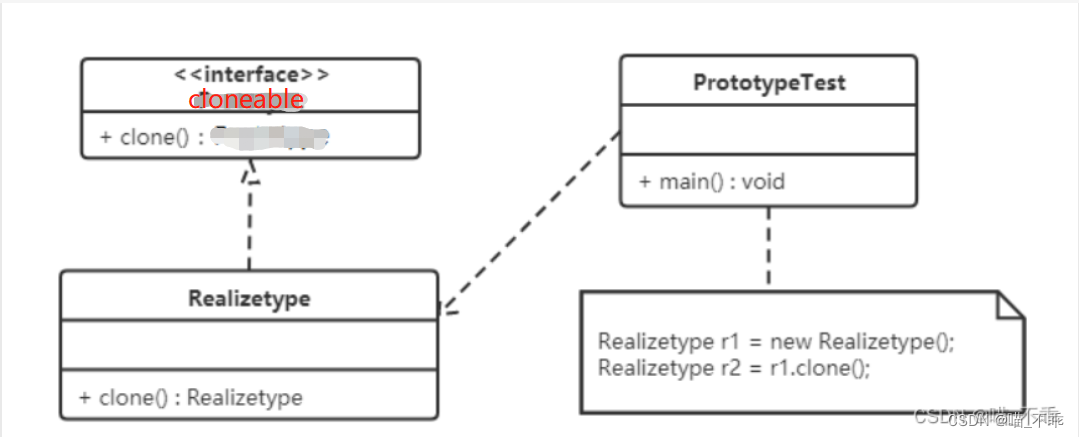
1.3 实现
在Java中对象的克隆有深克隆和浅克隆之分。有这种区分的原因是Java中分为基本数据类型和引用数据类型,对于不同的数据类型在内存中的存储的区域是不同的。基本数据类型存储在栈中,引用数据类型存储在堆中。
浅克隆:创建一个新对象,对于基本数据类型和String类型属性(拷贝一份该对象并重新分配内存,即产生了新的对象);对于非基本数据类型,浅克隆并不会克隆这些属性(即不会为这些属性分配内存,仍指向原有属性所指向的对象的内存地址)。
深克隆:创建一个新对象,属性中引用的其他对象也会被克隆,不再指向原有对象地址。
总结:浅克隆中由于除8中数据类型和String类型外的其他类型的属性不会被克隆,因此当通过新对象对这些属性进行修改时,原对象的属性也会同时改变。而深克隆则已经对这些属性重新分配内存,所以当通过新对象对这些属性进行修改时,原对象的属性不会改变。
Java中的Object类中提供了 clone() 方法来实现浅克隆。 Cloneable 接口是上面的类图中的抽象原型类,而实现了Cloneable接口的子实现类就是具体的原型类。代码如下:
Realizetype(具体的原型类):
public class Realizetype implements Cloneable {
public Realizetype() {
System.out.println("具体的原型对象创建完成!");
}
@Override
protected Realizetype clone() throws CloneNotSupportedException {
System.out.println("具体原型复制成功!");
return (Realizetype) super.clone();
}
}
PrototypeTest(测试访问类):
public class PrototypeTest {
public static void main(String[] args) throws CloneNotSupportedException{
Realizetype r1 = new Realizetype();
Realizetype r2 = r1.clone();
System.out.println("对象r1和r2是同一个对象?" + (r1 == r2)); //ture
}
}
前置:cloneable接口的作用
cloneable其实就是一个标记接口,只有实现这个接口后,然后在类中重写Object中的clone方法,然后通过类调用clone方法才能克隆成功,如果不实现这个接口,则会抛出CloneNotSupportedException(克隆不被支持)异常。
这里有一个疑问,Object中的clone方法是一个空的方法,那么他是如何判断类是否实现了cloneable接口呢?
原因在于这个方法中有一个native关键字修饰。native修饰的方法都是空的方法,但是这些方法都是有实现体的(这里也就间接说明了native关键字不能与abstract同时使用。因为abstract修饰的方法与java的接口中的方法类似,他显式的说明了修饰的方法,在当前是没有实现体的,abstract的方法的实现体都由子类重写),只不过native方法调用的实现体,都是非java代码编写的(例如:调用的是在jvm中编写的C的接口),每一个native方法在jvm中都有一个同名的实现体,native方法在逻辑上的判断都是由实现体实现的,另外这种native修饰的方法对返回类型,异常控制等都没有约束。
由此可见,这里判断是否实现cloneable接口,是在调用jvm中的实现体时进行判断的。
1.4 浅克隆
Demo1:基本类型

Demo2:引用类型
public static void main(String[] args) throws CloneNotSupportedException {
Address address = new Address("中国" , "山西" , "运城");
Customer customer1 = new Customer(1 , 18 , address);
Customer customer2 = customer1.clone();
customer2.getAddress().setProvince("北京");
customer2.getAddress().setCity("北京");
customer2.setAge(28);
System.out.println("customer1:"+customer1.toString());
System.out.println("customer2:"+customer2.toString());
}
}
class Customer implements Cloneable{
public int ID;
public int age;
public Address address;
//get/set...
@Override
public Customer clone() throws CloneNotSupportedException {
return (Customer) super.clone();
}
}
class Address{
private String country;
private String province;
private String city;
//get/set...
//toString
}

customer2修改了age后没有影响到customer1,
但是修改了customer2的address属性修改后,发现customer1的address值也发生了改变。这样就没有达到完全复制、相互之间完全没有影响的目的。这样就需要进行深克隆。
浅克隆总结:
浅克隆对于一个只含有基本数据类型的类来说使用clone方法,是完全没有问题的。
1.5 深克隆
深克隆与浅克隆的区别就是,浅克隆不会克隆原对象中的引用类型,仅仅拷贝了引用类型的指向。深克隆则拷贝了所有。也就是说深克隆能够做到原对象和新对象之间完全没有影响。
而深克隆的实现就是在引用类型所在的类实现Cloneable接口,并使用public访问修饰符重写clone方法。
实现方式1:浅克隆嵌套
1. Address类实现Cloneable接口,重写clone方法;
@Override
public Address clone() throws CloneNotSupportedException {
return (Address) super.clone();
}
2. 在Customer类的clone方法中调用Address类的clone方法
@Override
public Customer clone() throws CloneNotSupportedException {
Customer customer = (Customer) super.clone();
customer.address = address.clone();
return customer;
}

发现customer2无论如何修改,customer1都没有受到影响。
实现方式2:序列化
实现深克隆的另一种方法就是使用序列化,将对象写入到流中,这样对象的内容就变成了字节流,也就不存在什么引用了。然后读取字节流反序列化为对象就完成了完全的复制操作了。
Address address = new Address("CH" , "SD" , "QD");
Customer customer1 = new Customer(1 , 23 , address);
Customer customer2 = (Customer) cloneObject(customer1);
customer2.getAddress().setCity("JN");
customer2.setID(2);
System.out.println("customer1:"+customer1.toString());
System.out.println("customer2:"+customer2.toString());
public static Object cloneObject(Object obj) throws IOException, ClassNotFoundException{
ByteArrayOutputStream byteOut = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(byteOut);
out.writeObject(obj);
ByteArrayInputStream byteIn = new ByteArrayInputStream(byteOut.toByteArray());
ObjectInputStream in =new ObjectInputStream(byteIn);
return in.readObject();
}
customer1:Customer [ID=1, age=23, address=Address [country=CH, province=SD, city=QD]]
customer2:Customer [ID=2, age=23, address=Address [country=CH, province=SD, city=JN]]
总结
- 浅克隆:只复制基本类型的数据,引用类型的数据只复制了引用的地址,引用的对象并没有复制,在新的对象中修改引用类型的数据会影响原对象中的引用。
- 深克隆1:是在引用类型的类中也实现了clone,是clone的嵌套,复制后的对象与原对象之间完全不会影响。
- 深克隆2:使用序列化也能完成深复制的功能:对象序列化后写入流中,此时也就不存在引用什么的概念了,再从流中读取,生成新的对象,新对象和原对象之间也是完全互不影响的。
来源:深克隆和浅克隆:https://blog.csdn.net/weixin_44351616/article/details/125146241
https://www.bilibili.com/video/BV1Np4y1z7BU?p=49&spm_id_from=pageDriver&vd_source=b901ef0e9ed712b24882863596eab0ca
cloneable接口的作用:https://blog.csdn.net/qq_37113604/article/details/81168224















 9198
9198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









