







 文章探讨了One-hot编码的缺点,如高维度和无法捕捉语义相似性,然后介绍了WordEmbedding的核心思想,即通过上下文理解单词语义。word2vec的两种方法——CBOW和Skip-gram被详细阐述,重点在于参数共享以降低模型复杂性和提高效率。通过训练,模型能学习到单词的向量表示,使得语义相近的词具有相近的嵌入。最后,提到词嵌入可用于任何单词的转化,通过乘以学习到的权重矩阵。
文章探讨了One-hot编码的缺点,如高维度和无法捕捉语义相似性,然后介绍了WordEmbedding的核心思想,即通过上下文理解单词语义。word2vec的两种方法——CBOW和Skip-gram被详细阐述,重点在于参数共享以降低模型复杂性和提高效率。通过训练,模型能学习到单词的向量表示,使得语义相近的词具有相近的嵌入。最后,提到词嵌入可用于任何单词的转化,通过乘以学习到的权重矩阵。
One-hot-encoding
缺点
1.向量维度和向量个数很大,假设有1w个token的话,向量个数和维度就都是1w
2. 语义相近的词的向量并不相似
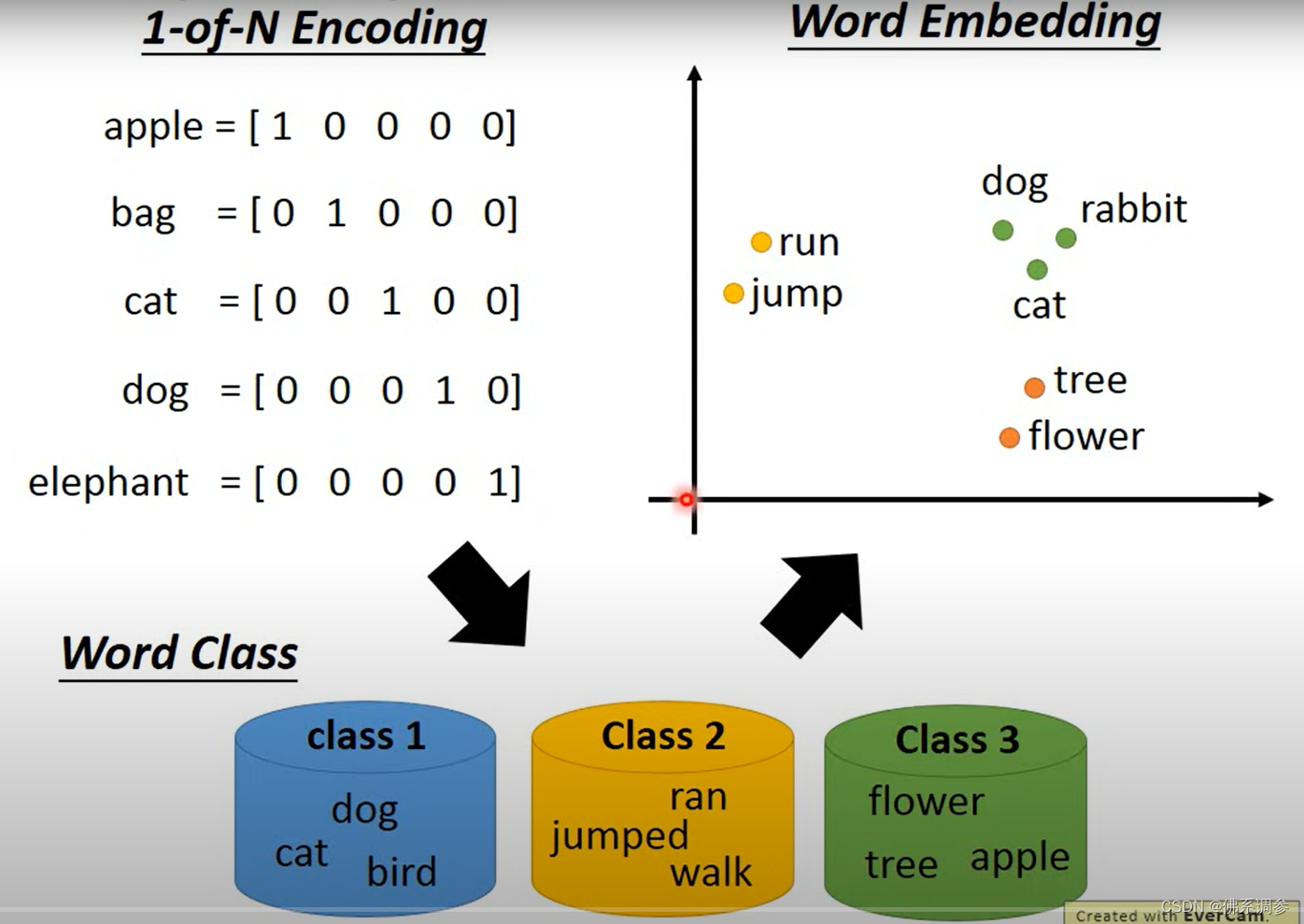
Word Embedding
核心思想:可以通过上下文理解单词的语义

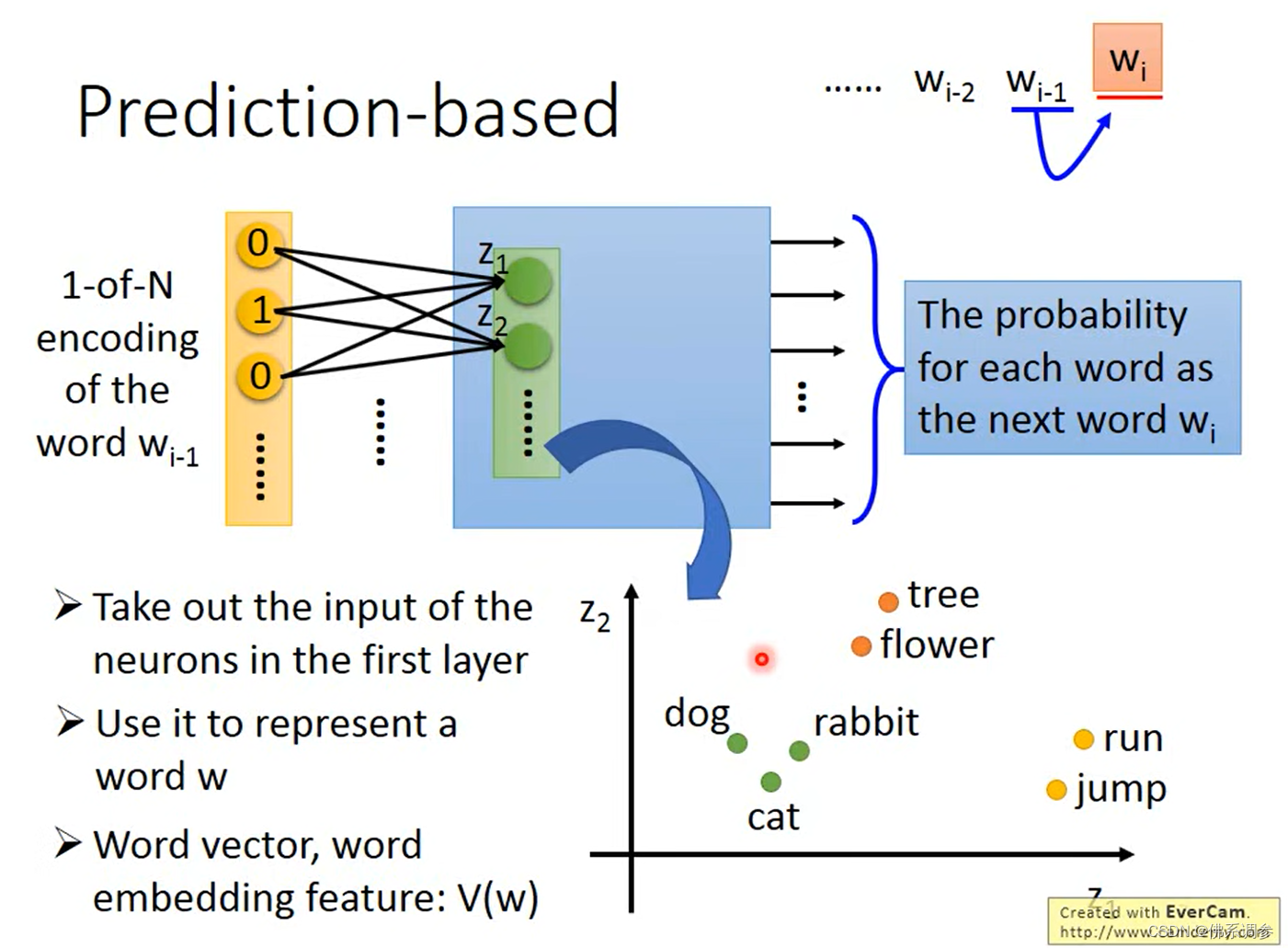
predection-based方法
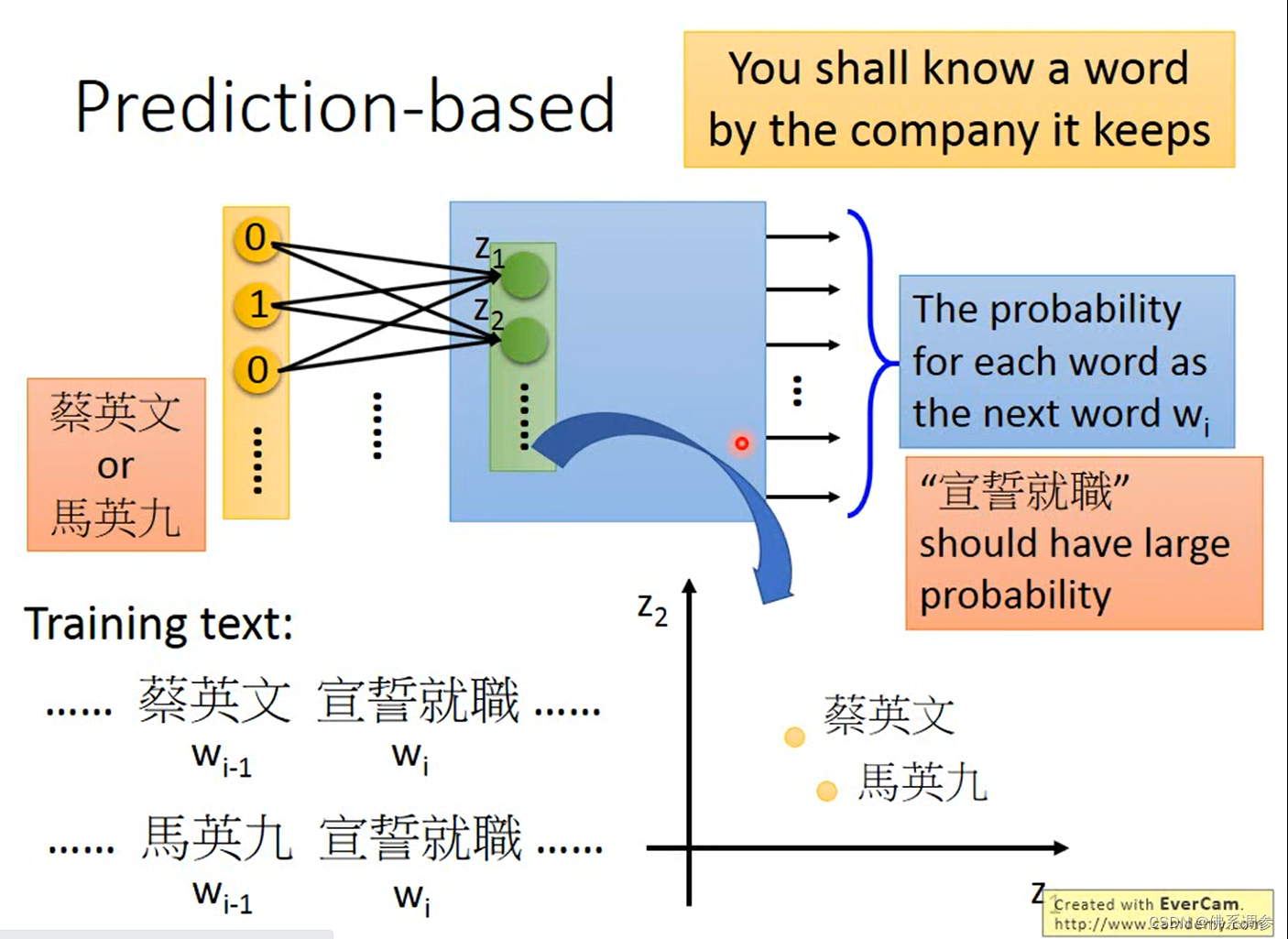
使用前一个单词预测下一个单词
使用一个简单的多层MLP网络,输入第Wi-1个单词,输出预测下一个单词Wi。输入输出都是one-hot向量,取隐藏层中的第一层作为Wi-1单词的embedding,记为V(Wi-1)(但隐藏层的维度很小)
实际word2vec算法中采用的网络只有一层隐藏层,总共是三层网络(输入,隐藏,输出)
使用多个单词预测一个单词, sharing parameters
为什么要共享参数?
1.Wi-2和Wi-1输入顺序不同,输出Wi应该是相同的
2.降低参数量
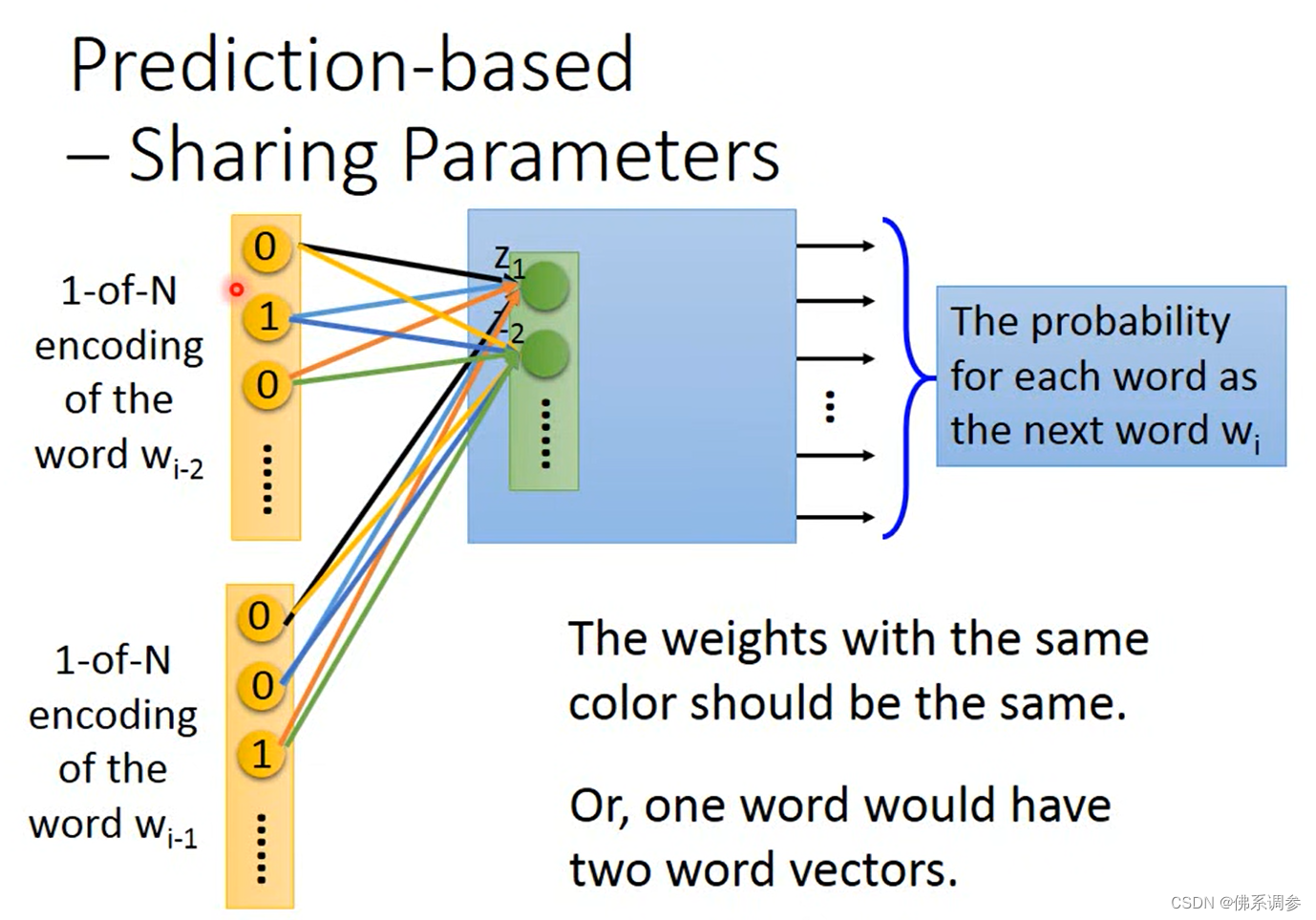
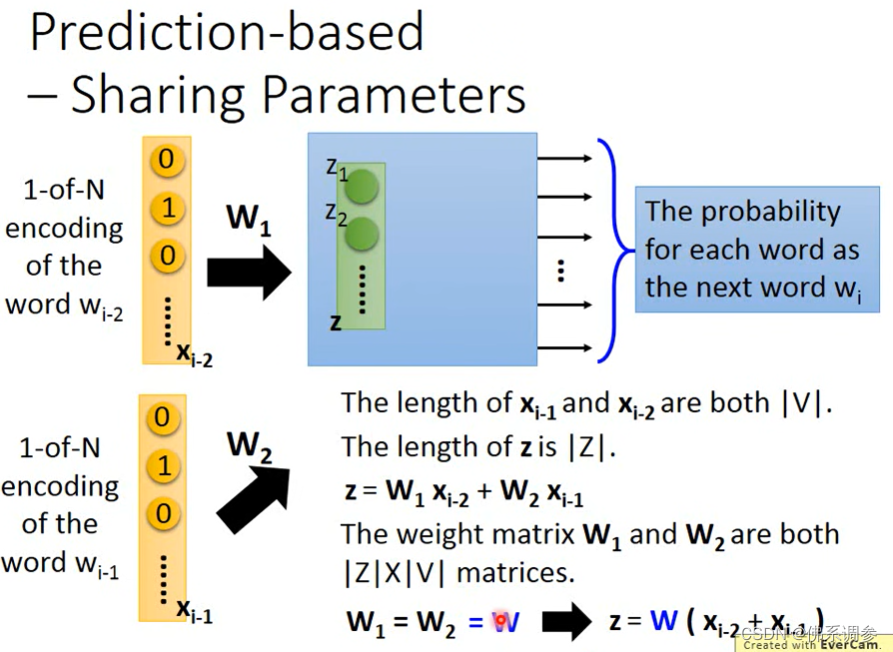
如何使得参数共享?
做法:更新的梯度值相同即可
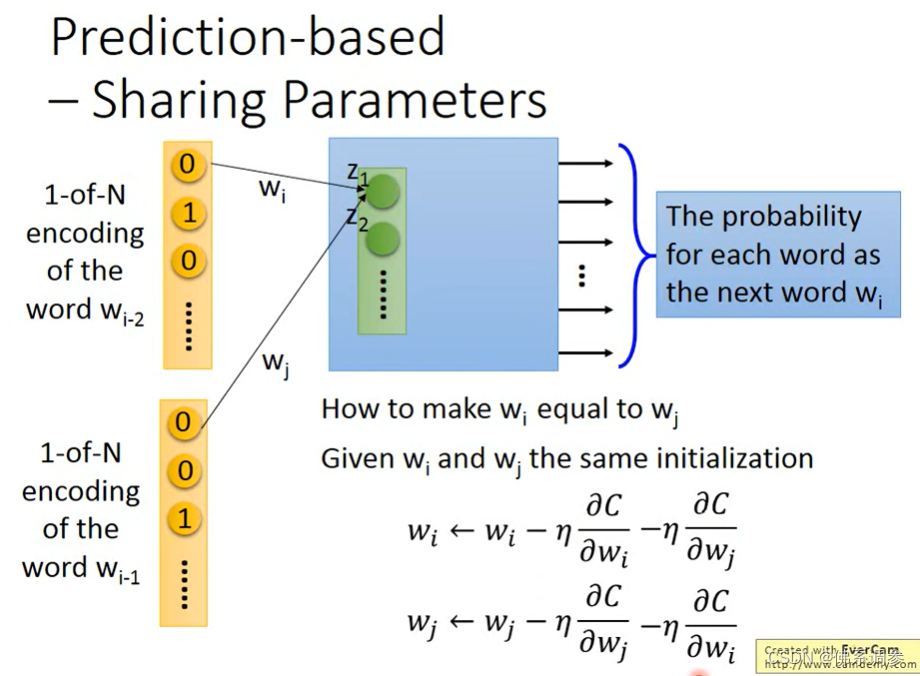
训练

不同方法变种
CBOW和Skip-gram
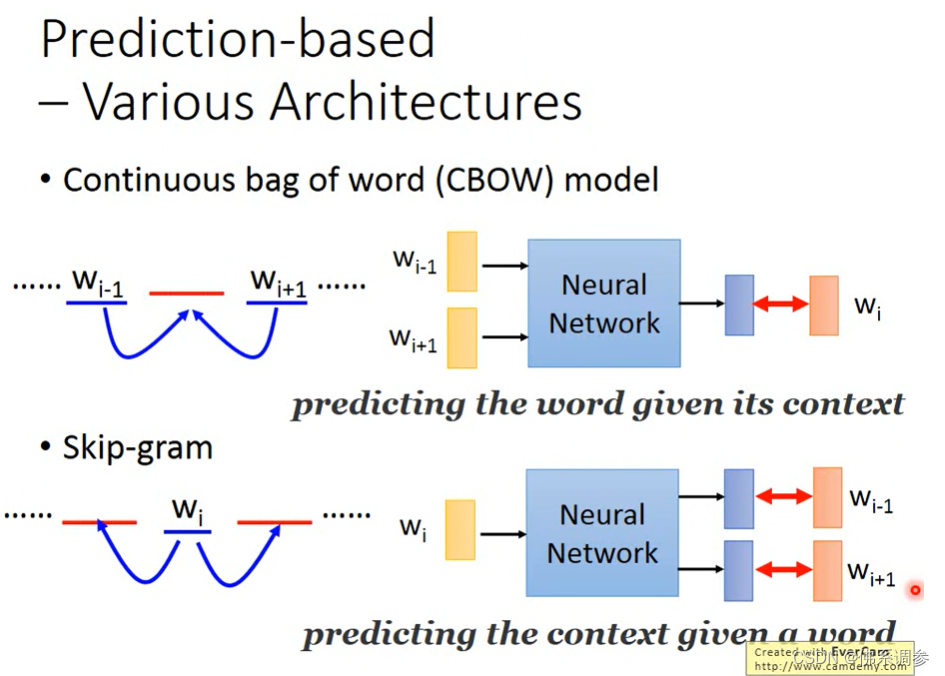
NOTE:花括号内{}为解释内容.
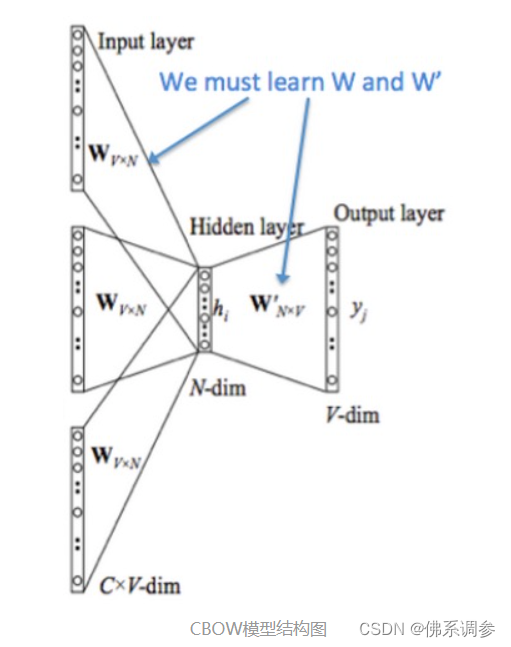
- 输入层:上下文单词的onehot. {假设单词向量空间dim为V,上下文单词个数为C}
- 所有onehot分别乘以共享的输入权重矩阵W. {V*N矩阵,N为自己设定的数,初始化权重矩阵W}
- 所得的向量 {因为是onehot所以为向量} 相加求平均作为隐层向量, size为1*N.
- 乘以输出权重矩阵W' {N*V}
- 得到向量 {1*V} 激活函数处理得到V-dim概率分布 {PS: 因为是onehot嘛,其中的每一维度代表着一个单词},概率最大的index所指示的单词为预测出的中间词(target word)
- 与true label的onehot做比较,误差越小越好
采用交叉熵损失训练网络,得到参数W和W',其中W矩阵就是我们需要的,也可称为look up table。任何单词的One-hot向量乘以矩阵W便得到其对应的embedding
词嵌入结果展示
相近单词具有相近的嵌入,词嵌入向量之间可以进行加减运算来衡量向量之间的距离

 如何使用?
如何使用?
任何一个单词的one-hot表示乘以这个学习出来的矩阵W,都将得到自己的word embedding。
参考链接


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









