






3G显存也能跑Stable Diffussion了
之前出了ubuntu的安装教程,想自己笔记本也试下,不得不说很辛酸,昨晚历时3个小时终于跑起来了,显卡都跑满了,但是效果很哇塞哈哈。
个人笔记本配置:
cpu: i7 6700hq
gpu: 1060 3g
先上图,看看我生成的小姐姐:
这是我找了civi上面的一些prompt随机生成的,感兴趣的小伙伴可以自己试试,如果自己的电脑配置可以,那生图效率会更高,分辨率也能更高!



没有加人脸修复,人物细节还是差点。实测生成一张图快的话平均25秒左右。再试试新加的openjourney模型。






感觉跟midjourny效果差不多了,有没有很炸裂!注意这都是随机生成的!,只要给定足够的提示词和反推提示词就行了。不得不说AI进步真的快!下面是安装教程:
windows安装非常方便下面是安装教程:
- clone项目并下载依赖
git clone https://ghproxy.com/https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui
3.修改依赖并配置pip源
ps:这时候默认下载的话会很慢,建议pip更换清华源,执行如下命令:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
修改lanch.py
注意由于网络限制,需要将所有github的地址前面都加上代理前缀,请自行修改
修改如下:
def prepare_environment():
global skip_install
torch_command = os.environ.get('TORCH_COMMAND', "pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117")
requirements_file = os.environ.get('REQS_FILE', "requirements_versions.txt")
xformers_package = os.environ.get('XFORMERS_PACKAGE', 'xformers==0.0.16rc425')
gfpgan_package = os.environ.get('GFPGAN_PACKAGE', "git+https://ghproxy.com/https://github.com/TencentARC/GFPGAN.git@8d2447a2d918f8eba5a4a01463fd48e45126a379")
clip_package = os.environ.get('CLIP_PACKAGE', "git+https://ghproxy.com/https://github.com/openai/CLIP.git@d50d76daa670286dd6cacf3bcd80b5e4823fc8e1")
openclip_package = os.environ.get('OPENCLIP_PACKAGE', "git+https://ghproxy.com/https://github.com/mlfoundations/open_clip.git@bb6e834e9c70d9c27d0dc3ecedeebeaeb1ffad6b")
stable_diffusion_repo = os.environ.get('STABLE_DIFFUSION_REPO', "https://ghproxy.com/https://github.com/Stability-AI/stablediffusion.git")
taming_transformers_repo = os.environ.get('TAMING_TRANSFORMERS_REPO', "https://ghproxy.com/https://github.com/CompVis/taming-transformers.git")
k_diffusion_repo = os.environ.get('K_DIFFUSION_REPO', 'https://ghproxy.com/https://github.com/crowsonkb/k-diffusion.git')
codeformer_repo = os.environ.get('CODEFORMER_REPO', 'https://ghproxy.com/https://github.com/sczhou/CodeFormer.git')
blip_repo = os.environ.get('BLIP_REPO', 'https://ghproxy.com/https://github.com/salesforce/BLIP.git')
然后运行webuser.bat ,就开始自动安装了。
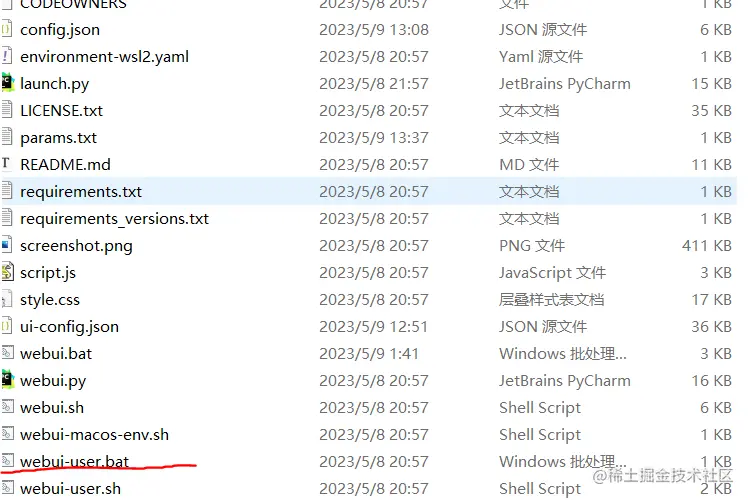
注意,如果你的机器Gpu内存跟我一样小于6G的话,建议安装xformers并且开启低内存模式。
crtl +c结束刚才的进程。
打开windows cmd窗口。
进入stable venv
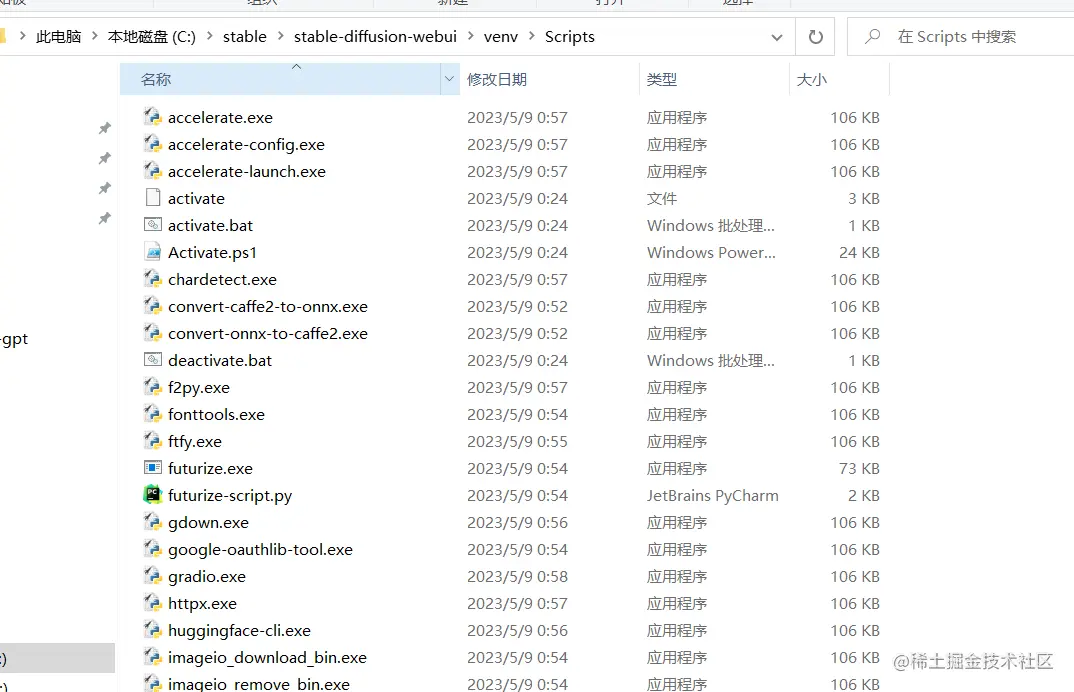
可直接在地址栏输入 cmd就进入到这个文件夹了。
然后在cmd命令行运行activate.bat进入python虚拟环境。
执行启动命令
首先cd到stable目录
安装xformers
cd ..
cd .. #这是为了回到stable目录
pip install -U xformers
#安装完就可以启动了
python launch.py --xformers --medvram
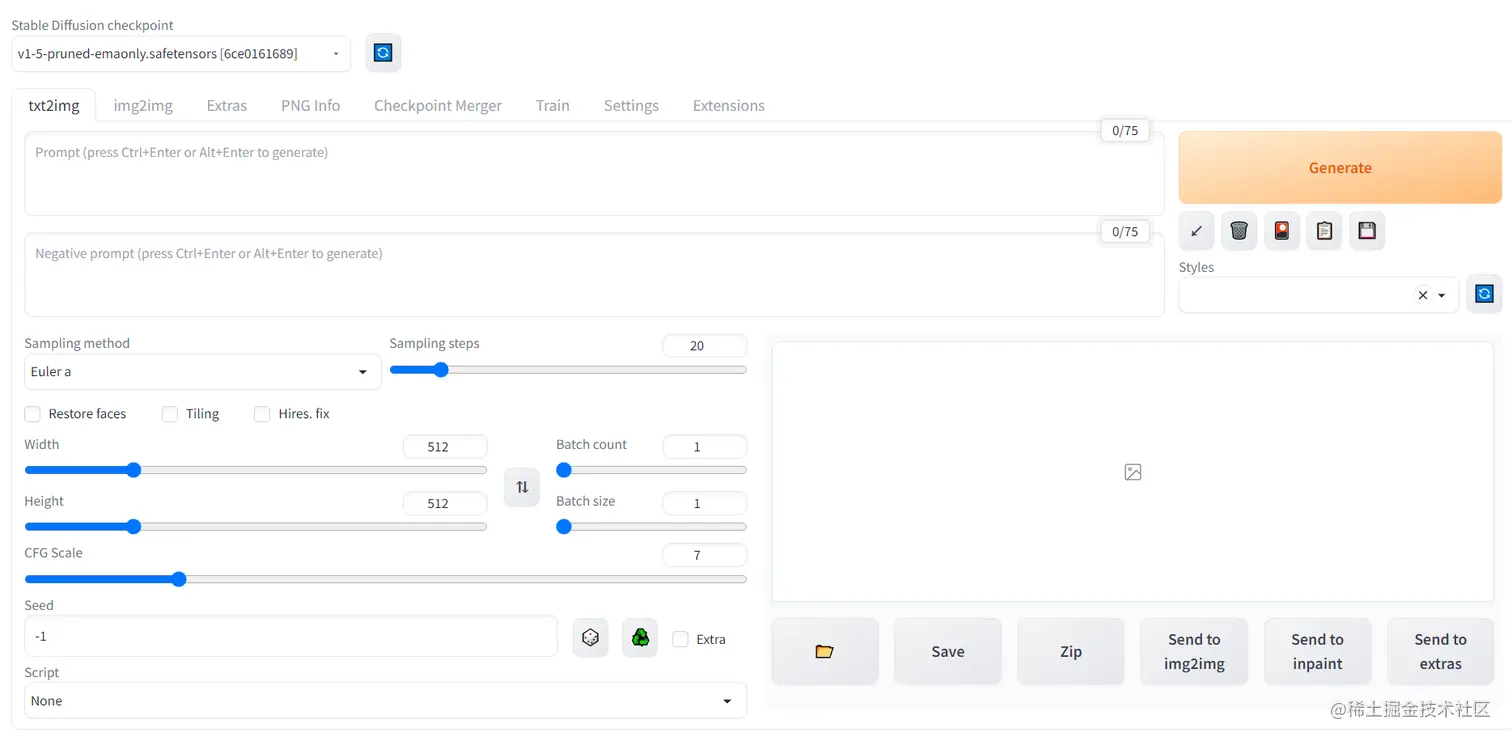
至此,大功告成!
最后启动完如下图所示:
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









