







vgg16
因为vgg16太大了(100多个G)所以没有下载
pretrained = False 模型中所有的参数为默认参数
pretrained = True 模型中所的参数为训练好的参数
from torch import nn
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
# 在原有的模型中添加操作
vgg16_true.classfier.add_module("add_linear",nn.Linear(1000,10)) # 名字,操作
print(vgg16_true) # classfier为模型中的一个分类,也就是把线性层加在classfier下
#在原模型中更改操作
print(vgg_false)
vgg16_false.classfier[7] = nn.Linear(4096,10) # 更改classfier下的第7个
print(vgg16_false)
在第二三四行代码中进行运行,下载了vgg16的模型(0.5G)
模型的保存和加载
保存方式1:
import torch
import torchvision
vgg16 = torchvision.model.vgg16(pretrained=False)
torch.save(vgg16,"vgg16_method1.pth")保存模型结构和模型参数
对应保存方式1加载模型:
import torch
model = torch.load("vgg16_method1.pth") # 模型所在位置
print(model)# 加载自己定义的模型时需要引入 from 文件名 import *
# 或者把class粘贴进来
保存方式2:
import torch
import torchvision
torch.save(vgg16.state_dict(),"vgg16_method2.pth") # 把vgg16中的模型参数保存到字典
保存模型参数(官方推荐)(空间小)
对应保存方式2加载模型
import torch
mmodel = torch.load("vgg16_method2.pth")
print(model)
# 打印出来是在字典中的模型参数
import torch
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth")))
print(model)
# 打印出模型和参数
完整的训练模型套路
在同一个文件夹底下建立两个python文件
# 构建神经网络 命名为 module
import torch
from torch import nn
class Didi(nn.Module):
def __init__(self):
super(Didi, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__': # 设置为主方法
didi = Didi()
input = torch.ones((64,3,32,32)) # 检查是否正确
output = didi(input)
print(output.shape)在另一个文件中引入该模型
from module import *
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from module import *
train_data = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=torchvision.transforms.ToTensor())
train_data_size = len(train_data) # 看数据集长度(图片的个数)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size)) # 字符串格式化
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型
didi = Didi()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(didi.parameters(),lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练次数
total_train_step = 0
# 记录测试次数
total_test_step = 0
# 训练的轮数
epoch= 10
for i in range(epoch):
print(f"-----第{i}轮训练开始-----")
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = didi(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 先梯度清零,然后反向传播求梯度,然后优化数据
loss.backward()
optimizer.step() # 是对数据data进行优化
total_train_step = total_train_step + 1
print(f"训练次数{total_train_step}loss:{loss}")如何知道模型在训练时是否训练好或者达到想要的需求
# 测试步骤开始
total_test_loss = 0
with torch.no_grad(): # 保证不会对测试的代码进行调优
for data in test_dataloader:
imgs ,targets = data
outputs = didi(imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item()
# 什么.item 就是把各种类型的数比如说tensor类型的数转换成一个纯粹的数
print(f"整体测试集的loss:{total_test_loss}")对于分类问题可以用正确率来表示
2个输入
放入model(二分类)
输出[0.1,0.2] 属于1类别
[0.05,0.4] 属于1类别
类别 0 1
利用Argmax
预测=[1]
[1]
真实target = [0][1]
预测==真实target
[false,true].sum = 1
import torch
outputs = torch.tensor([[0.1,0.2],
[0.05,0.4]])
print(outputs.argmax(1)) # 1 横向比较 0 纵向比较
preds = outputs.argmax(1)
targets = torch.tensor([0,1])
print((preds == targets).sum())优化模型(完整代码)
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from module import *
train_data = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=torchvision.transforms.ToTensor())
train_data_size = len(train_data) # 看数据集长度(图片的个数)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size)) # 字符串格式化
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型
didi = Didi()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(didi.parameters(),lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练次数
total_train_step = 0
# 记录测试次数
total_test_step = 0
# 训练的轮数
epoch= 10
# 添加tensorboard
writer = SummaryWriter("./ceshi")
for i in range(epoch):
print(f"-----第{i}轮训练开始-----")
# 训练步骤开始
didi.train() # 只对特定的层进行调用(本示例中无可调用的层)
for data in train_dataloader:
imgs, targets = data
outputs = didi(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 先梯度清零,然后反向传播求梯度,然后优化梯度
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print(f"训练次数{total_train_step}loss:{loss}")
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
didi.eval() # 只对特定的层进行调用(本示例中无可调用的层)
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 保证不会对测试的代码进行调优
for data in test_dataloader:
imgs ,targets = data
outputs = didi(imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item()
# 什么.item 就是把各种类型的数比如说tensor类型的数转换成一个纯粹的数
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print(f"整体测试集的loss:{total_test_loss}")
print(f"整体测试集上的正确率 {total_accuracy/test_data_size}")
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step = total_test_step + 1
torch.save(didi,"didi_{}.pth".format(i)) # 保存每一轮训练的模型
# torch.save(didi.state_dict(),"didi_{}.pth".format(i))
print("模型已保存")
writer.close()总结步骤:准备数据集,准备dataloader,创建网络模型,创建损失函数,优化器,设置训练参 数,设置训练轮数epoch,开始训练算出误差放入优化器优化,进行测试(不需要梯 度)计算误差,保存模型。
利用GPU训练
1. 可在 网络模型, 数据(输入,标注) ,损失函数 中使用
.cuda()
简略代码
………… import time ………… didi = Didi() if torch.cuda.is_available(): didi = didi.cuda() # 损失函数 loss_fn = nn.CrossEntropyLoss() loss_fn = loss_fn.cuda() ………… # 开始时间 start_time = time.time() for i in range(epoch): print(f"-----第{i}轮训练开始-----") # 训练步骤开始 didi.train() # 只对特定的层进行调用(本示例中无可调用的层) for data in train_dataloader: imgs, targets = data imgs = imgs.cuda() targets = targets.cuda() ………… if total_train_step % 100 == 0: end_time = time.time() print(end_time - start_time) ………… # 测试步骤开始 didi.eval() # 只对特定的层进行调用(本示例中无可调用的层) total_test_loss = 0 total_accuracy = 0 with torch.no_grad(): # 保证不会对测试的代码进行调优 for data in test_dataloader: imgs ,targets = data imgs = imgs.cuda() targets = targets.cuda() ………… ………… writer.close()
2. 可在 网络模型, 数据(输入,标注) ,损失函数 中使用
.to(device)
Device = torch.device("cpu")
Torch.device("cuda") 或者 Torch.device("cuda:0") # 电脑中有多个显卡使用第一个
简略代码
# 定义训练设备
device = torch.device("cuda" if torch.cuda.is_availiable() else"cpu")
# 替换上面红色代码
didi = didi.to(device)
loss_fn = loss_fn.to(device)
imgs = imgs.to(device)
targets = targets.to(device)
imgs = imgs.to(device)
targets = targets.to(device)
完整的模型验证(测试,demo)套路
利用已经训练好的模型,然后给他提供输入
因为我上一个保存的模型是用GPU保存的,所以这次输入也要用GPU
 屏幕截图
屏幕截图
import torch
import torchvision
from PIL import Image
from module import *
image_path = "屏幕截图 2021-10-27 185044.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')
# png格式是4通道,除了RGB三通道外,还有一个透明通道。所以调用该函数,保留其颜色通道。该操作可适应任何png jpg各种格式的图片
transform =torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])
image = transform(image)
image = image.cuda()
print(image.shape)
# 加载网络模型
model = torch.load("didi_0.pth")
# model = torch.load("didi_0.pth",map_location=torch.device("cpu")) 不增加.cuda()而使用cpu的方法
print(model)
image = torch.reshape(image,(1,3,32,32))
image = image.cuda()
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))输出
<PIL.PngImagePlugin.PngImageFile image mode=RGBA size=383x221 at 0x23F271B3D00>
torch.Size([3, 32, 32])
Didi(
(model): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
tensor([[-1.1313, -0.1298, 0.3228, 0.6047, 0.4514, 0.7824, 0.5668, 0.1615,
-1.5708, -1.0045]], device='cuda:0')
tensor([5], device='cuda:0') # 预测为第六个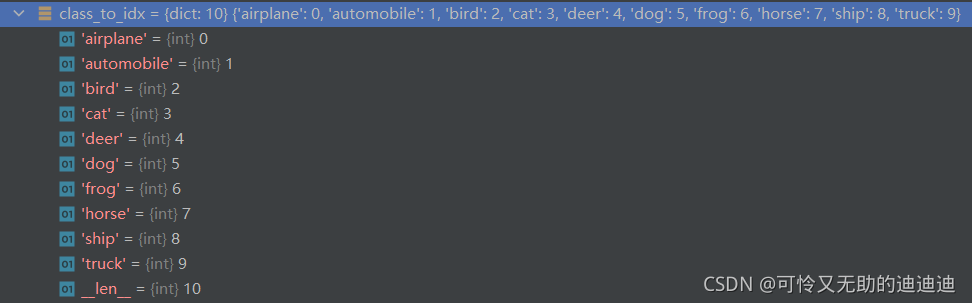
可以看出输出5对应dog 预测成功














 9016
9016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









